








黑色加粗部分基本就是题目给出的部分,红色部分是自己需要注意的知识点。
16.合并两个排序的链表
题目描述:
输入两个单调递增的链表,输出两个链表合成后的链表,当然我们需要合成后的链表满足单调不减规则。
思路:
基本思想就是递归,首先想到最终返回的要么是p1的头,要么是p2的头,所以呢,可以用这个作为终止条件。
代码:
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* Merge(ListNode* pHead1, ListNode* pHead2)
{
if(pHead1==NULL)
return pHead2;
else if(pHead2==NULL)
return pHead1;
ListNode* newhead=NULL;
if(pHead1->val<pHead2->val)
{
newhead=pHead1;
newhead->next=Merge(pHead1->next,pHead2);
}else{
newhead=pHead2;
newhead->next=Merge(pHead1,pHead2->next);
}
return newhead;
}
};
17.树的子结构
题目描述:
输入两棵二叉树A,B,判断B是不是A的子结构。(ps:我们约定空树不是任意一个树的子结构)
思路:
这一道题在这篇博客上讲的比较清楚:点击打开链接。主要思想就是先判断A,B是否有相同的根节点。其次是判断A的子节点是否和B的子结构。
代码:
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};*/
class Solution {
public:
bool HasSubtree(TreeNode* pRootA, TreeNode* pRootB)
{
if(pRootA==NULL||pRootB==NULL)
return false;
return isSubtree(pRootA,pRootB) || HasSubtree(pRootA->left,pRootB) || HasSubtree(pRootA->right,pRootB);
}
private:
bool isSubtree(TreeNode* pRootA,TreeNode* pRootB){
if(pRootB==NULL) return true;
if(pRootA==NULL) return false;
if(pRootA->val==pRootB->val)
{
return isSubtree(pRootA->left,pRootB->left)&& isSubtree(pRootA->right,pRootB->right);
}else
return false;
}
};
18.二叉树的镜像
题目描述:
操作给定的二叉树,将其变换为源二叉树的镜像。
思路:
这道题的思路就是用递归,算是比较考验人的。
代码:
/*struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};*/
class Solution {
public:
void Mirror(TreeNode *pRoot) {
if(pRoot)
{
swap(pRoot->right,pRoot->left);
Mirror(pRoot->right);
Mirror(pRoot->left);
}
}
};
19.顺时针打印矩阵
题目描述:
输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字,例如,如果输入如下矩阵: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 则依次打印出数字1,2,3,4,8,12,16,15,14,13,9,5,6,7,11,10.
思路:
这道题的思路就是上下左右四个边界,然后这四个边界用来作为记录遍历的条件。当然要注意其中遍历的判断条件避免二次遍历。
代码:
class Solution {public:
vector<int> printMatrix(vector<vector<int> > matrix) {
vector<int>res;
int top,bottom,left,right;
int row=matrix.size();
int col=matrix[0].size();
if(row==0||col==0)return res;
top=0;bottom=row-1;
left=0;right=col-1;
while(left<=right && top<=bottom)
{
for(int i=left;i<=right;++i) res.push_back(matrix[top][i]);
for(int i=top+1;i<=bottom;++i) res.push_back(matrix[i][right]);
if(top!=bottom)
for(int i=right-1;i>=left;--i) res.push_back(matrix[bottom][i]);
if(left!=right)
for(int i=bottom-1;i>top;i--) res.push_back(matrix[i][left]);
left++,top++,right--,bottom--;
}
return res;
}
};
20.包含min函数的栈
题目描述:
定义栈的数据结构,请在该类型中实现一个能够得到栈最小元素的min函数。
思路:
基本上是stack类型的应用吧。然后多引入了一个mindata的最小函数需要判断push进来的值是否比原来的top小
代码:
class Solution {public:
void push(int value) {
if(minData.empty())
minData.push(value);
else
{
if(minData.top()<value)
minData.push(minData.top());
else
minData.push(value);
}
data.push(value);
}
void pop() {
minData.pop();
data.pop();
}
int top() {
return data.top();
}
int min() {
return minData.top();
}
private:
stack<int>data,minData;
};
21.栈的压入、弹出序列
题目描述:
输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如序列1,2,3,4,5是某栈的压入顺序,序列4,5,3,2,1是该压栈序列对应的一个弹出序列,但4,3,5,1,2就不可能是该压栈序列的弹出序列。(注意:这两个序列的长度是相等的)
思路:
这道题没怎么理解,主要应该就是如果压入栈的最后的数和弹出栈一样就把最后的数单出。
代码:
class Solution {public:
bool IsPopOrder(vector<int> pushV,vector<int> popV) {
if(pushV.size()==0) return false;
vector<int> stack;
for(int i=0,j=0;i<pushV.size();)
{
stack.push_back(pushV[i++]);
while(j<popV.size() && stack.back()==popV[j])
{
stack.pop_back();
j++
}
}
return stack.empty();
}
};
22.从上往下打印二叉树
题目描述:
从上往下打印出二叉树的每个节点,同层节点从左至右打印。
思路:
这道题是典型的广度优先搜索的题目,有句话说的好:道理我都懂,但就是做不到。其实这一题拿到手我也是一头雾水。后来想明白了,说白了其实就是运用队列来实现,为什么用队列实现好呢?队列的特性摆在那儿,先进先出。而且使用方法和stack差不多,就是数据进出的顺序不一样罢了。
代码:
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};*/
class Solution {
public:
vector<int> PrintFromTopToBottom(TreeNode* root) {
//这不是典型的广度优先搜索bfs
queue<TreeNode*>jinchen;
vector<int>jieguo;
TreeNode* yingru;
if(root==NULL) return jieguo;
jinchen.push(root);
while(!jinchen.empty())
{
yingru=jinchen.front();
jieguo.push_back(yingru->val);
if(yingru->left!=NULL)
jinchen.push(yingru->left);
if(yingru->right!=NULL)
jinchen.push(yingru->right);
jinchen.pop();
}
return jieguo;
}
};
23.二叉树的后序遍历序列
题目描述:
输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历的结果。如果是则输出Yes,否则输出No。假设输入的数组的任意两个数字都互不相同。
思路:
这道题目呢,有个问题就是二叉搜索树的问题(毕竟不是科班出身,知识还是有所欠缺的),这个博客给出了比较详细的二叉树和二叉搜索树的区别:点击打开链接 。就是左孩子小于右孩子。还有一个就是这道题普遍采用是递归,但是采用这种写法显然优于递归写法。
代码:
class Solution {public:
bool VerifySquenceOfBST(vector<int> sequence) {
//后序遍历,就是左右根的遍历顺序,判断一个序列是不是后序遍历的结果
int size=sequence.size();
if(0==size) return false;
int i=0;
while(--size)
{
while(sequence[i++]<sequence[size]);
while(sequence[i++]>sequence[size]);
if(i<size) return false;
i=0;
}
return true;
}
};
24.二叉树中和为某一值的路径
题目描述:
输入一颗二叉树和一个整数,打印出二叉树中结点值的和为输入整数的所有路径。路径定义为从树的根结点开始往下一直到叶结点所经过的结点形成一条路径。
思路:
这道题目呢,有个问题就是二叉搜索树的问题(毕竟不是科班出身,知识还是有所欠缺的),这个博客给出了比较详细的二叉树和二叉搜索树的区别:点击打开链接 。就是左孩子小于右孩子。还有一个就是这道题普遍采用是递归,但是采用这种写法显然优于递归写法。
代码:
/*struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};*/
class Solution {
public:
vector<vector<int>>buffer;
vector<int>temp;
vector<vector<int> > FindPath(TreeNode* root,int expectNumber) {
//这个应该是采用深度优先搜索,先全左然后再向右分
//最后实现找到数字的目的。
if(root==NULL)
return buffer;
temp.push_back(root->val);
if((expectNumber-root->val)==0 && (root->left==NULL) && (root->right==NULL) )
{
buffer.push_back(temp);
}
FindPath(root->left,expectNumber-root->val);
FindPath(root->right,expectNumber-root->val);
if(temp.size()!=0)
temp.pop_back();
return buffer;
}
};
25.复杂链表的复制
题目描述:
输入一个复杂链表(每个节点中有节点值,以及两个指针,一个指向下一个节点,另一个特殊指针指向任意一个节点),返回结果为复制后复杂链表的head。(注意,输出结果中请不要返回参数中的节点引用,否则判题程序会直接返回空)
思路:
这一题还是比较难的,但是总的来说就是链表的运用,说到底还是自己比较渣 ,学的不好。
代码:
/*struct RandomListNode {
int label;
struct RandomListNode *next, *random;
RandomListNode(int x) :
label(x), next(NULL), random(NULL) {
}
};
*/
class Solution {
public:
RandomListNode* Clone(RandomListNode* pHead)
{
if(!pHead) return NULL;
nodeClone(pHead);
connectRandom(pHead);
return reconnect(pHead);
}
//[1]复制结点,插入到原结点后方
void nodeClone(RandomListNode* head)
{
RanomListNode* pNode=head;
while(pNode!=NULL)
{
RandomListNode* pClone=new RandomListNode(pNode->label);
pClone->next=pNode->next;
pNode->next=pClone;
pNode=pClone->next;
}
}
//还原新节点的random指针
void connectRandom(RandomListNode* head)
{
RandomListNode* pNode=head;
while(pNode!=NULL){
RandomListNode* pClone=pNode->next;
if(pNode->random)
{
pClone->random=pNode->random->next;
}
pNode=pClone->next;
}
}
//拆分
RandomListNode * reconnect(RandomListNode * head){
RandomListNode* pNode=head;
RandomListNode* result=head->next;
while(pNode!=NULL){
RandomListNode *pClone=pNode->next;
pNode->next=pClone->next;
pNode=pNode->next;
if(pNode!=NULL)
pClone->next=pNode->next;
}
return result;
}
};
26.二叉搜索树与双向链表
题目描述:
输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的双向链表。要求不能创建任何新的结点,只能调整树中结点指针的指向。
思路:
这一题还是比较难的。但是看了这幅图之后就比较清晰了,该如何去做。
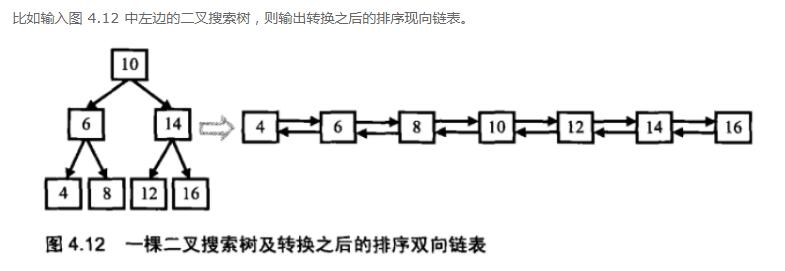
在二叉树中,每个结点都有两个指向子结点的指针。在双向链表中,每个结点也有两个指针,它们分别指向前一个结点和后一个结点。由于这两种结点的结构相似,同时二叉搜索树也是一种排序的数据结构,因此在理论上有可能实现二叉搜索树和排序的双向链表的转换。在搜索二叉树中,左子结点的值总是小于父结点的值,右子结点的值总是大于父结点的值。因此我们在转换成排序双向链表时,原先指向左子结点的指针调整为链表中指向前一个结点的指针,原先指向右子结点的指针调整为链表中指向后一个结点指针。接下来我们考虑该如何转换。
由于要求转换之后的链表是排好序的,我们可以中序遍历树中的每一个结点, 这是因为中序遍历算法的特点是按照从小到大的顺序遍历二叉树的每一个结点。当遍历到根结点的时候,我们把树看成三部分:值为 10 的结点、根结点值为 6 的左子树、根结点值为 14 的右子树。根据排序链表的定义,值为 10 的结点将和它的左子树的最大一个结点(即值为 8 的结点)链接起来,同时它还将和右子树最小的结点(即值为 12 的结点)链接起来,
代码:
/*struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};*/
class Solution {
public:
TreeNode* Convert(TreeNode* pRootOfTree)
{
TreeNode* pList=nullptr;
preoder(pRootOfTree,&pList);
return pList;
}
void preoder(TreeNode* pRootOfTree,TreeNode** pList){
//先序遍历的反向遍历
//右中左
if(pRootOfTree==nullptr)return;
if(pRootOfTree->right!=nullptr)
preoder(pRootOfTree->right,pList);
pRootOfTree->right=*pList;
if(*pList!=nullptr)
(*pList)->left=pRootOfTree;
*pList=pRootOfTree;
if(pRootOfTree->left!=nullptr)
preoder(pRootOfTree->left,pList);
}
};
27.字符串的排列
题目描述:
输入一个字符串,按字典序打印出该字符串中字符的所有排列。例如输入字符串abc,则打印出由字符a,b,c所能排列出来的所有字符串abc,acb,bac,bca,cab和cba。
思路:
这一题还是比较难的,但是看看图也就知道了,是应该运用递归来做。
把一个字符串看成由两部分组成:第一部分为它的第一个字符,第二部分是后面的所有字符。在图 4.14 中,我们用两种不同的背景颜色区分字符串的两部分。
我们求整个字符串的排列,可以看成两步:首先求所有可能出现在第一个位置的字符,即把第一个字符和后面所有的字符交换。图 4.14 就是分别把第一个字符 a 和后面的 b、c 等字符交换的情形。首先固定第一个字符(如图 4.14 (a )所示〉,求后面所有字符的排列。这个时候我们仍把后面的所有字符分成两部分:后面字符的第一个字符,以及这个字符之后的所有字符。然后把第一个字符逐一和它后面的字符交换(如图 4.14 (b)所示)。。。。。。
这其实是很典型的递归思路。
顺带复习一下,break,continue的用法:
break可以在循环和switch中使用,程序执行到break语句时,如在break在循环中出现,则跳出当前层次的循环(只能跳出一层)继续执行循环外的一语句.如果在switch语句中出现,则结束switch,继续执行switch语句之后的语句.
continue只能用在循环中,意思是"继续"循环的意思.当程序执行到contnue时,流程会回到循环的头部,continue后面的的语句不会被执行.

代码:
class Solution {public:
vector<string>Permutation(string str){
vector<string>vec;
if(str=="")
return vec;
Perm(str,0,str.length(),vec);
sort(vec.begin(),vec.end());
return vec;
}
private:
void swap(char& a,char& b){
char temp=a;
a=b;
b=temp;
}
void Perm(string str,int begin,int end,vector<string>&vec)
{
if(begin==end)
{
vec.push_back(str);
}else{
for(int i=begin;i<end;++i)
{
if(i!=begin && str[begin]==str[i])
continue;
swap(str[begin],str[i]);
Perm(str,begin+1,end,vec);
swap(str[begin],str[i]);
}
}
}
};
28.数组中出现次数超过一半的数字
题目描述:
数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。例如输入一个长度为9的数组{1,2,3,2,2,2,5,4,2}。由于数字2在数组中出现了5次,超过数组长度的一半,因此输出2。如果不存在则输出0。
思路:
这一题的这种方法太奇妙了,由于它是判断是否超过一半,因此用count是否为0来判断是否超过一半,超过一半自然这个count不会为0
还有一个需要注意的地方就是string.length()表示字符串的长度,vector.size()表示向量的大小
代码:
class Solution {public:
int MoreThanHalfNum_Solution(vector<int> numbers) {
int count=1;
int num;
num=numbers[0];
if(numbers.size()==0)return 0;
for(int i=1;i<numbers.size();i++)
{
if(numbers[i]==num)
{count++;}
else
count--;
if(count==0)
{
num=numbers[i];
count=1;
}
}
count=0;
for(int i=0;i<numbers.size();i++)
{
if(numbers[i]==num) count++;
}
if(2*count>numbers.size())
return num;
else
return 0;
}
};
29.最小的K个数
题目描述:
输入n个整数,找出其中最小的K个数。例如输入4,5,1,6,2,7,3,8这8个数字,则最小的4个数字是1,2,3,4
思路:
这一题还是很简单的,虽然开始我没有考虑全面,首先要判断一下选取的k值是否合理,如果合理然后就利用sort函数进行排序即得到最终结果
这里需要注意的是sort函数是默认从小到大排序。
代码:
class Solution {public:
vector<int> GetLeastNumbers_Solution(vector<int> input, int k) {
vector<int>res;
if(k>input.size())
return res;
sort(input.begin(),input.end());
for(int i=0;i<k;i++)
{
res.push_back(input[i]);
}
return res;
}
};
30.连续子数组的最大和
题目描述:
HZ偶尔会拿些专业问题来忽悠那些非计算机专业的同学。今天测试组开完会后,他又发话了:在古老的一维模式识别中,常常需要计算连续子向量的最大和,当向量全为正数的时候,问题很好解决。但是,如果向量中包含负数,是否应该包含某个负数,并期望旁边的正数会弥补它呢?例如:{6,-3,-2,7,-15,1,2,2},连续子向量的最大和为8(从第0个开始,到第3个为止)。你会不会被他忽悠住?(子向量的长度至少是1)
思路:
基本思想就是用cur做当前的和值如果当前的和值比刚加进来的数值小,就说明刚才这个数值比前面的和值有价值,同时考察最大值,如果最大值小于和值那么和值就是最大值。
代码:
class Solution {public:
int FindGreatestSumOfSubArray(vector<int> array) {
int cur=array[0];
int max=array[0];
for(int i=1;i<array.size();i++)
{
cur+=array[i];
if(cur<array[i])
cur=array[i];
if(cur>max)
max=cur;
}
return max;
}
};















 4445
4445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









