






若要修改默认引擎,可以修改配置文件中的 default-storage-engine。可以通过: show variables like 'default_storage_engine';查看当前数据库到默认引擎。命令: show engines和show variables like 'have%'可以列出当前数据库所支持到引擎。其中Value显示为disabled的记录表示数据库支持此引擎,而在数据库启动时被禁用。在MySQL5.1以后,INFORMATION_SCHEMA数据库中存在一个ENGINES的表,它提供的信息与show engines;语句完全一样,可以使用下面语句来查询哪些存储引擎支持事物处理: select engine from information_chema.engines where transactions = 'yes';
可以通过 engine关键字在创建或修改数据库时指定所使用到引擎。
主要存储引擎:MyISAM、InnoDB、MEMORY和MERGE介绍:
在创建表到时候通过 engine=...或 type=...来指定所要使用到引擎。 show table status from DBname来查看指定表到引擎。
(一)MyISAM
它不支持事务,也不支持外键,尤其是访问速度快,对事务完整性没有要求或者以SELECT、INSERT为主的应用基本都可以使用这个引擎来创建表。
每个MyISAM在磁盘上存储成3个文件,其中文件名和表名都相同,但是扩展名分别为:
- .frm(存储表定义)
- MYD(MYData,存储数据)
- MYI(MYIndex,存储索引)
数据文件和索引文件可以放置在不同的目录,平均分配IO,获取更快的速度。要指定数据文件和索引文件的路径,需要在创建表的时候通过DATA DIRECTORY和INDEX DIRECTORY语句指定,文件路径需要使用绝对路径。
每个MyISAM表都有一个标志,服务器或myisamchk程序在检查MyISAM数据表时会对这个标志进行设置。MyISAM表还有一个标志用来表明该数据表在上次使用后是不是被正常的关闭了。如果服务器以为当机或崩溃,这个标志可以用来判断数据表是否需要检查和修复。如果想让这种检查自动进行,可以在启动服务器时使用--myisam-recover现象。这会让服务器在每次打开一个MyISAM数据表是自动检查数据表的标志并进行必要的修复处理。MyISAM类型的表可能会损坏,可以使用CHECK TABLE语句来检查MyISAM表的健康,并用REPAIR TABLE语句修复一个损坏到MyISAM表。
MyISAM的表还支持3种不同的存储格式:
- 静态(固定长度)表
- 动态表
- 压缩表
其中静态表是默认的存储格式。静态表中的字段都是非变长字段,这样每个记录都是固定长度的,这种存储方式的优点是存储非常迅速,容易缓存,出现故障容易恢复;缺点是占用的空间通常比动态表多。静态表在数据存储时会根据列定义的宽度定义补足空格,但是在访问的时候并不会得到这些空格,这些空格在返回给应用之前已经去掉。同时需要注意:在某些情况下可能需要返回字段后的空格,而使用这种格式时后面到空格会被自动处理掉。
动态表包含变长字段,记录不是固定长度的,这样存储的优点是占用空间较少,但是频繁到更新删除记录会产生碎片,需要定期执行OPTIMIZE TABLE语句或myisamchk -r命令来改善性能,并且出现故障的时候恢复相对比较困难。
压缩表由myisamchk工具创建,占据非常小的空间,因为每条记录都是被单独压缩的,所以只有非常小的访问开支。
(二)InnoDB
InnoDB存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。但是对比MyISAM的存储引擎,InnoDB写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引。
1)自动增长列:
InnoDB表的自动增长列可以手工插入,但是插入的如果是空或0,则实际插入到则是自动增长后到值。可以通过"ALTER TABLE...AUTO_INCREMENT=n;"语句强制设置自动增长值的起始值,默认为1,但是该强制到默认值是保存在内存中,数据库重启后该值将会丢失。可以使用LAST_INSERT_ID()查询当前线程最后插入记录使用的值。如果一次插入多条记录,那么返回的是第一条记录使用的自动增长值。
对于InnoDB表,自动增长列必须是索引。如果是组合索引,也必须是组合索引的第一列,但是对于MyISAM表,自动增长列可以是组合索引的其他列,这样插入记录后,自动增长列是按照组合索引到前面几列排序后递增的。
2)外键约束:
MySQL支持外键的存储引擎只有InnoDB,在创建外键的时候,父表必须有对应的索引,子表在创建外键的时候也会自动创建对应的索引。
在创建索引的时候,可以指定在删除、更新父表时,对子表进行的相应操作,包括restrict、cascade、set null和no action。其中restrict和no action相同,是指限制在子表有关联的情况下,父表不能更新;casecade表示父表在更新或删除时,更新或者删除子表对应的记录;set null 则表示父表在更新或者删除的时候,子表对应的字段被set null。
当某个表被其它表创建了外键参照,那么该表对应的索引或主键被禁止删除。
可以使用set foreign_key_checks=0;临时关闭外键约束,set foreign_key_checks=1;打开约束。
(三)MEMORY
memory使用存在内存中的内容来创建表。每个MEMORY表实际对应一个磁盘文件,格式是.frm。MEMORY类型的表访问非常快,因为它的数据是放在内存中的,并且默认使用HASH索引,但是一旦服务器关闭,表中的数据就会丢失,但表还会继续存在。
默认情况下,memory数据表使用散列索引,利用这种索引进行“相等比较”非常快,但是对“范围比较”的速度就慢多了。因此,散列索引值适合使用在"="和"<=>"的操作符中,不适合使用在"<"或">"操作符中,也同样不适合用在order by字句里。如果确实要使用"<"或">"或betwen操作符,可以使用btree索引来加快速度。
存储在MEMORY数据表里的数据行使用的是长度不变的格式,因此加快处理速度,这意味着不能使用BLOB和TEXT这样的长度可变的数据类型。VARCHAR是一种长度可变的类型,但因为它在MySQL内部当作长度固定不变的CHAR类型,所以可以使用。
create table tab_memory engine=memory
select
id,name,age,addr
from
man order
by
id;
|
使用USING HASH/BTREE来指定特定到索引。
create index mem_hash
using
hash
on
tab_memory(city_id);
|
在启动MySQL服务的时候使用--init-file选项,把insert into...select或load data infile 这样的语句放入到这个文件中,就可以在服务启动时从持久稳固的数据源中装载表。
服务器需要足够的内存来维持所在的在同一时间使用的MEMORY表,当不再使用MEMORY表时,要释放MEMORY表所占用的内存,应该执行DELETE FROM或truncate table或者删除整个表。
每个MEMORY表中放置到数据量的大小,受到max_heap_table_size系统变量的约束,这个系统变量的初始值是16M,同时在创建MEMORY表时可以使用MAX_ROWS子句来指定表中的最大行数。
(四)MERGE
merge存储引擎是一组MyISAM表的组合,这些MyISAM表结构必须完全相同,MERGE表中并没有数据,对MERGE类型的表可以进行查询、更新、删除的操作,这些操作实际上是对内部的MyISAM表进行操作。对于对MERGE表进行的插入操作,是根据INSERT_METHOD子句定义的插入的表,可以有3个不同的值,first和last值使得插入操作被相应的作用在第一个或最后一个表上,不定义这个子句或者为NO,表示不能对这个MERGE表进行插入操作。可以对MERGE表进行drop操作,这个操作只是删除MERGE表的定义,对内部的表没有任何影响。MERGE在磁盘上保留2个以MERGE表名开头文件:.frm文件存储表的定义;.MRG文件包含组合表的信息,包括MERGE表由哪些表组成,插入数据时的依据。可以通过修改.MRG文件来修改MERGE表,但是修改后要通过flush table刷新。
create
table
man_all(id
int
,
name
varchar
(20))engine=merge
union
=(man1,man2) insert_methos=
last
;
==============================================================================================================================================
基本概念
• 字符(Character)是指人类语言中最小的表义符号。例如'A'、'B'等;
• 给定一系列字符,对每个字符赋予一个数值,用数值来代表对应的字符,这一数值就是字符的编码(Encoding)。例如,我们给字符'A'赋予数值0,给字符'B'赋予数值1,则0就是字符'A'的编码;
• 给定一系列字符并赋予对应的编码后,所有这些字符和编码对组成的集合就是字符集(Character Set)。例如,给定字符列表为{'A','B'}时,{'A'=>0, 'B'=>1}就是一个字符集;
• 字符序(Collation)是指在同一字符集内字符之间的比较规则;
• 确定字符序后,才能在一个字符集上定义什么是等价的字符,以及字符之间的大小关系;
• 每个字符序唯一对应一种字符集,但一个字符集可以对应多种字符序,其中有一个是默认字符序(Default Collation);
• MySQL中的字符序名称遵从命名惯例:以字符序对应的字符集名称开头;以_ci(表示大小写不敏感)、_cs(表示大小写敏感)或_bin(表示按编码值比较)结尾。例如:在字符序``utf8_general_ci''下,字符``a''和``A''是等价的;
MySQL字符集设置
• 系统变量:
– character_set_server:默认的内部操作字符集
– character_set_client:客户端来源数据使用的字符集
– character_set_connection:连接层字符集
– character_set_results:查询结果字符集
– character_set_database:当前选中数据库的默认字符集
– character_set_system:系统元数据(字段名等)字符集
– 还有以collation_开头的同上面对应的变量,用来描述字符序。
• 用introducer指定文本字符串的字符集:
– 格式为:[_charset] 'string' [COLLATE collation]
– 例如:
• SELECT _latin1 'string';
• SELECT _utf8 '你好' COLLATE utf8_general_ci;
– 由introducer修饰的文本字符串在请求过程中不经过多余的转码,直接转换为内部字符集处理。
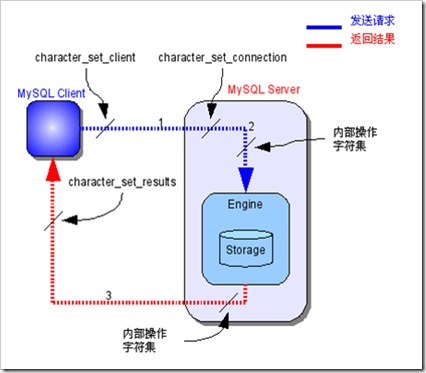
MySQL中的字符集转换过程
1. MySQL Server收到请求时将请求数据从character_set_client转换为character_set_connection;
2. 进行内部操作前将请求数据从character_set_connection转换为内部操作字符集,其确定方法如下:
• 使用每个数据字段的CHARACTER SET设定值;
• 若上述值不存在,则使用对应数据表的DEFAULT CHARACTER SET设定值(MySQL扩展,非SQL标准);
• 若上述值不存在,则使用对应数据库的DEFAULT CHARACTER SET设定值;
• 若上述值不存在,则使用character_set_server设定值。
3. 将操作结果从内部操作字符集转换为character_set_results。
常见问题解析
• 向默认字符集为utf8的数据表插入utf8编码的数据前没有设置连接字符集,查询时设置连接字符集为utf8
– 插入时根据MySQL服务器的默认设置,character_set_client、character_set_connection和character_set_results均为latin1;
– 插入操作的数据将经过latin1=>latin1=>utf8的字符集转换过程,这一过程中每个插入的汉字都会从原始的3个字节变成6个字节保存;
– 查询时的结果将经过utf8=>utf8的字符集转换过程,将保存的6个字节原封不动返回,产生乱码……
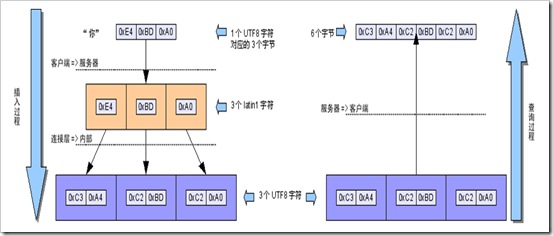
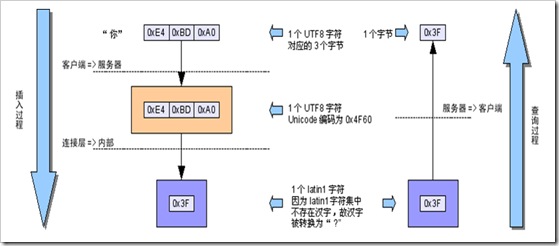
– 插入时根据连接字符集设置,character_set_client、character_set_connection和character_set_results均为utf8;
– 插入数据将经过utf8=>utf8=>latin1的字符集转换,若原始数据中含有/u0000~/u00ff范围以外的Unicode字符,会因为无法在latin1字符集中表示而被转换为“?”(0x3F)符号,以后查询时不管连接字符集设置如何都无法恢复其内容了。
• SHOW CHARACTER SET;
• SHOW COLLATION;
• SHOW VARIABLES LIKE 'character%';
• SHOW VARIABLES LIKE 'collation%';
• SQL函数HEX、LENGTH、CHAR_LENGTH
• SQL函数CHARSET、COLLATION
使用MySQL字符集时的建议
• 建立数据库/表和进行数据库操作时尽量显式指出使用的字符集,而不是依赖于MySQL的默认设置,否则MySQL升级时可能带来很大困扰;
• 数据库和连接字符集都使用latin1时虽然大部分情况下都可以解决乱码问题,但缺点是无法以字符为单位来进行SQL操作,一般情况下将数据库和连接字符集都置为utf8是较好的选择;
• 使用mysql C API时,初始化数据库句柄后马上用mysql_options设定MYSQL_SET_CHARSET_NAME属性为utf8,这样就不用显式地用SET NAMES语句指定连接字符集,且用mysql_ping重连断开的长连接时也会把连接字符集重置为utf8;
• 对于mysql PHP API,一般页面级的PHP程序总运行时间较短,在连接到数据库以后显式用SET NAMES语句设置一次连接字符集即可;但当使用长连接时,请注意保持连接通畅并在断开重连后用SET NAMES语句显式重置连接字符集。
其他注意事项
• my.cnf中的default_character_set设置只影响mysql命令连接服务器时的连接字符集,不会对使用libmysqlclient库的应用程序产生任何作用!
• 对字段进行的SQL函数操作通常都是以内部操作字符集进行的,不受连接字符集设置的影响。
• SQL语句中的裸字符串会受到连接字符集或introducer设置的影响,对于比较之类的操作可能产生完全不同的结果,需要小心!
================================================================================================================================
一个生产 系统总会经历一个业务量由小变大的过程,可扩展性成为了考量系统高可用性的一个重要衡量指标。试想一下,一个记事本应用程序,在存储的很少字节时,能够快速的打开和访问,但是如果硬要让记事本存储百万、千万字节,那么这个记事本估计就歇菜了!同样,系统刚开始的时候,用户数量不多,所有的数据都放在了同一个 数据库中,此时因为用户少压力小,一个数据库完全可以应付的了。但是随着用户数量不断增加,数据库压力也与日俱增,如果没有妥善的扩容机制,那么再强劲的硬件和商业数据库也会歇菜。 “Shard”字面意思为碎片,Sharding可以译为分片。 MySQL5以后提供了Sharding的能力,其目的就是为突破单节点数据服务器I/O能力限制,解决数据库Scale Out水平扩展的问题。通过Sharding可以将数据按照物理位置贴合用户分布,得到更加快速的响应;操作庞然大物总是让人头疼,Sharding将数据分块,更小的数据集操作汇总能够得到更加的体验;分片使得数据分摊在各个数据节点,对其操作实现负载均衡,众多屌丝的汇聚战胜了一个高富帅!
Sharding按方向可以分为两类。
垂直分区:以表为单位,把不同的表分散到不同的数据库或主机上。特点是规则简单,实施方便,适合业务之间耦合度低的系统。
水平分区:以行为单位,将同一个表中的数据按照某种条件拆分到不同的数据库或主机上。特点是相对复杂,适合单表巨大的系统。
Sharding按模式可以分为两大模式。
静态分片模式,即分区键是静态分配的,一般使用范围或哈希函数,例如深圳团队放到一个分片,北京团队放到另外一个分片;或者编号为0096开头的员工放到一个分片,而0199开头的员工放到另外一个分片。这种模式虽然实现简单,但明显的缺陷便是存在数据不均匀的情况。
动态分片模式,即分区函数将从字典中查找分区键,然后定位具体哪个分片存储了数据。这种模式比静态模式更加灵活,但是需要一个集中存储来存放字典,每次查找数据都需要执行2次查询,并且集中存储本身还可能存在单点故障。
Sharding按分区类型分为:
1) RANGE 分区:基于属于一个给定连续区间的列值,把多行分配给分区。
2) LIST 分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
3) HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。
4) KEY 分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL 服务器提供其自身的哈希函数。必须有一列或多列包含整数值。 在经过周密的设计和反复的测试后发现,所做的一切的努力都是值得的,MySQL的Sharding技术让一群低廉的PC服务器构成了一个可以媲美昂贵的小型机+商业数据库的性能,以低成本的方式构建了强大的数据中心。难怪淘宝这个巨人在很早的时候就一直推行“走你IOE”!
MySQL 3.22限制的表大小为4GB。由于在mysql 3.23中使用了MyISAM存储引擎,最大表尺寸增加到了65536TB(2567 – 1字节)。由于允许的表尺寸更大,MySQL数据库的最大有效表尺寸通常是由操作系统对文件大小的限制决定的,而不是由MySQL内部限制决定的。
InnoDB存储引擎将InnoDB表保存在一个表空间内,该表空间可由数个文件创建。这样,表的大小就能超过单独文件的最大容量。表空间可包括原始磁盘分区,从而使得很大的表成为可能。表空间的最大容量为64TB。
在下面的表格中,列出了一些关于操作系统文件大小限制的示例。这仅是初步指南,并不是最终的。要想了解最新信息,请参阅关于操作系统的文档。
操作系统
文件大小限制
Linux 2.2-Intel 32-bit
2GB (LFS: 4GB)
linux 2.4+
(using ext3 filesystem) 4TB
Solaris 9/10
16TB
NetWare w/NSS filesystem
8TB
win32 w/ FAT/FAT32
2GB/4GB
win32 w/ NTFS
2TB(可能更大)
MacOS X w/ HFS+
2TB
在Linux 2.2平台下,通过使用对ext2文件系统的大文件支持(LFS)补丁,可以获得超过2GB的MyISAM表。在Linux 2.4平台下,存在针对ReiserFS的补丁,可支持大文件(高达2TB)。目前发布的大多数Linux版本均基于2.4内核,包含所有所需的LFS补丁。使用JFS和XFS,petabyte(千兆兆)和更大的文件也能在Linux上实现。然而,最大可用的文件容量仍取决于多项因素,其中之一就是用于存储MySQL表的文件系统。
关于Linux中LFS的详细介绍,请参见Andreas Jaeger的“Linux中的大文件支持”页面:http://www.suse.de/~aj/linux_lfs.html。
Windows用户请注意: FAT和VFAT (FAT32)不适合MySQL的生产使用。应使用NTFS。
在默认情况下,MySQL创建的MyISAM表允许的最大尺寸为4GB。你可以使用SHOW TABLE STATUS语句或myisamchk -dv tbl_name检查表的最大尺寸。请参见13.5.4节,“SHOW语法”。
如果需要使用大于4GB的MyISAM表(而且你的操作系统支持大文件),可使用允许AVG_ROW_LENGTH和MAX_ROWS选项的CREATE TABLE语句。请参见13.1.5节,“CREATE TABLE语法”。创建了表后,也可以使用ALTER TABLE更改这些选项,以增加表的最大允许容量。请参见13.1.2节,“ALTER TABLE语法”。
处理MyISAM表文件大小的其他方式:
· 如果你的大表是只读的,可使用myisampack压缩它。myisampack通常能将表压缩至少50%,因而,从结果上看,可获得更大的表。此外,myisampack还能将多个表合并为1个表。请参见8.2节,“myisampack:生成压缩、只读MyISAM表”。
· MySQL包含一个允许处理MyISAM表集合的MERGE库,这类MyISAM表具有与单个MERGE表相同的结构。请参见15.3节,“MERGE存储引擎”。
如果你的表是INNODB的,并且操作系统是linux 或 winodws的ntfs,一般都是如此在服务器上,则可以说理论上没有限制。
一般来说,OLTP数据库随着时间的增长,数据会越来越多,常规的设计是定期做归档。仅保留业务需要的数据即可,比如1年的,或者2年的数据。2年前的数据归档,如果需要报表,则把数据同时生成到数据仓库即可。
来自:http://topic.csdn.net/u/20090616/11/7d7253b2-014e-4c9a-9033-1af81f8a26f3.html














 2095
2095











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









