







进入这篇文章的人默认是已经搭建好ELK的日志平台
一、概述
1、日志有什么用?
日志主要包括系统日志、应用程序日志和安全日志。系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。
2、何为ELK?
ELK 由ElasticSearch 、 Logstash 和 Kibana 三个开源工具组成,是一个开源实时日志分析平台。
Elasticsearch 是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制, restful 风格接口,多数据源,自动搜索负载等。
Logstash 是一个完全开源的工具,他可以对你的日志进行收集、分析,并将其存储供以后使用(如,搜索)。
kibana 也是一个开源和免费的工具,他 Kibana 可以为 Logstash 和ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
因为ElasticSearch、kibana、Logstash的搭建和部署,网上一找一大把,此处略过。下文主要是针对Logstash的解析配置和Kibana的使用说明。
二、Logstash解析日志
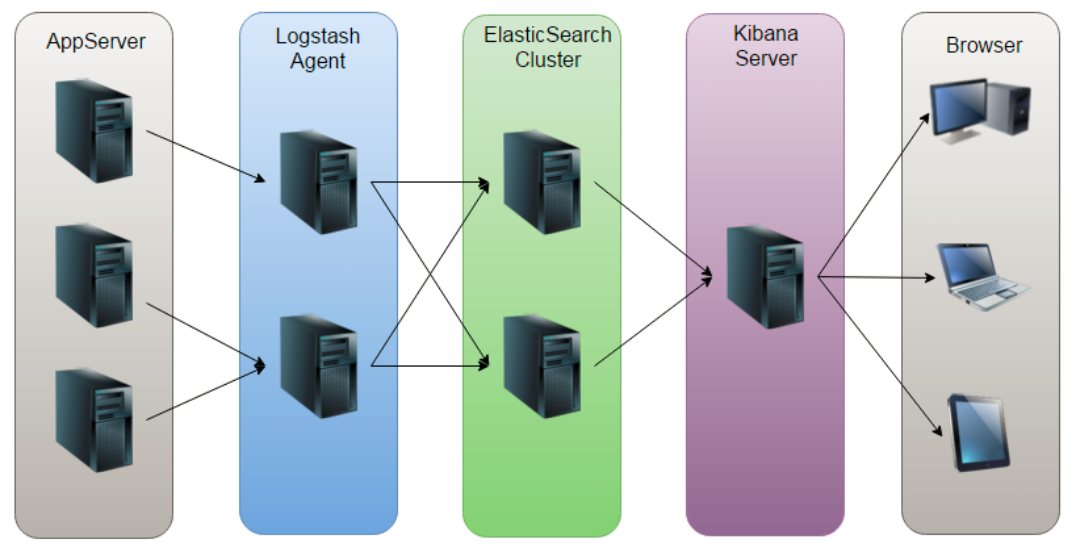
1、Logstash结构

2、Logstash解析文件(以dubbo日志文件解析为例)
input {
file {
path => "F:\log.txt" ## 填写文件的绝对路径
start_position => "beginning" ## 从头开始进行收集
codec => multiline { ## 通过配置识别日志开头,来保证多行可以被合并
pattern => "^[\d{2}:\d{2}:\d{2}.\d+]" ## 正则匹配以什么作为日志开头标志
negate => true
what => "previous"
}
}
}
filter {
grok {## 常用的filter之一,用于对文本日志记录进行json格式化
match => {
"message" => [ ## 多个正则格式数据
"(?<time>\d{2}:\d{2}:\d{2}.\d+)\s(?<thread>\[[^]]*\]{1})\s(?<level>\w+)\s\s(?<class>[\w|.]*)\s-{1}\s+(?<dubbo>\[[\w|\d|\-]*\]{1})\s(?<date>\[\d+-\d+-\d+\s\d+:\d+:\d+\])\s(?<customer>\d+.\d+.\d+.\d+):\d+\s-\>\s(?<producer>\d+.\d+.\d+.\d+:\d+)\s-\s(?<content>[\s|\S]*)",
"(?<time>\d{2}:\d{2}:\d{2}.\d+)\s(?<thread>\[[^]]*\]{1})\s(?<level>\w+)\s(?<content>[\s|\S]*)"
]
}
remove_field => ["message"]
}
date { ## 日期配置
match => [ "timestamp" , "HH:mm:ss Z" ]
}
}
output {
if[level]=="ERROR"{ ## 输出配置,如果当前日志标志为ERROR,则进行下方输出
stdout { ## 输出到控制端
codec => rubydebug
}
file { ## 输出到文件
path => "/diskb/bi_error_log/bi_error.log"
}
}
if[level]=="ERROR" or [level]=="INFO" and "monitor" not in [content]{
elasticsearch { ## 输出到es
hosts => ["localhost:9200"] ## es地址和端口
flush_size => 5000
index => "ebs-%{+YYYY.MM.dd}" ## kibana的检索index
idle_flush_time => 10
}
}
}3、Logstash解析mysql数据库
input {
jdbc {
jdbc_driver_library => "mysql-connector-java-5.1.30.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://ip:3306/schema"
jdbc_user => "your username"
jdbc_password => "your password"
schedule => "* * * * *" ## cron 表达式用以控制数据库记录采集的频率
statement => "SELECT * from `dubbo_invoke` where date_sub(FROM_UNIXTIME(LEFT(invoke_time,10), '%Y-%m-%d %H:%i:%S'),interval 8 hour) > :sql_last_value" ## sql_last_value 是logstash的关键字,保证日志的采集不会重复,同时logstash采集日志时间会慢8个小时
type => "jdbc"
last_run_metadata_path => "logstash-oradb.lastrun" ## 记录最后一条记录的值,可能是id值,也可能是最后一条记录的日期
}
}
filter {
date {
locale => "zh"
timezone => "Asia/Shanghai"
match => [ "invoke_time", "UNIX_MS" ]
}
}
output {
stdout{}
elasticsearch {
hosts => ["localhost:9200"]
flush_size => 5000
index => "monitor-%{+YYYY.MM.dd}" ## kibana的检索index
idle_flush_time => 10
}
}4、Logstash解析oracle数据库
input {
jdbc {
jdbc_driver_library => "ojdbc14.jar"
jdbc_driver_class => "Java::oracle.jdbc.driver.OracleDriver"
jdbc_connection_string => "jdbc:oracle:thin:@//cidpdev.gz.cvte.cn:1521/pdev_db" ## 此处是oracle12c的协议,oracle12c以下的协议是另外一种。注意:logstash协议前缀必须有jdbc
jdbc_user => "your username"
jdbc_password => "your password"
schedule => "* * * * *"
statement => "select * from comm_clog_option_log where TO_DATE(TO_CHAR(CRT_TIME,'yyyy-mm-dd HH24:MI:SS'),'yyyy-mm-dd HH24:MI:SS') - interval '8' hour > :sql_last_value"
type => "jdbc"
last_run_metadata_path => "logstash-oradb.lastrun"
}
}
filter {
date {
locale => "zh"
timezone => "Asia/Shanghai"
match => [ "CRT_TIME", "UNIX_MS" ]
}
}
output {
stdout{}
elasticsearch {
hosts => ["localhost:9200"]
flush_size => 5000
index => "cidpdev-%{+YYYY.MM.dd}" ## kibana的检索index
idle_flush_time => 10
}
}三、Kibana的使用
1、创建自己的索引(“Settings”)
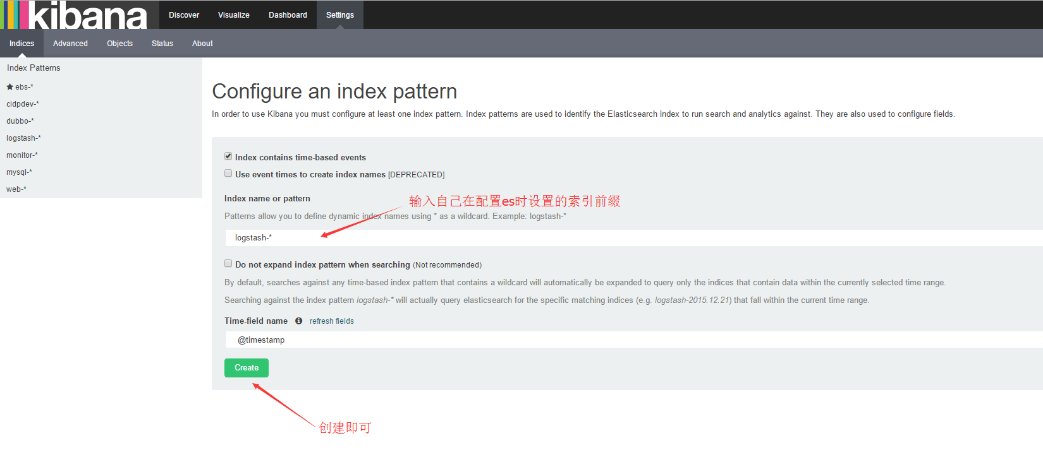
2、检索自己的数据(“Discover”)
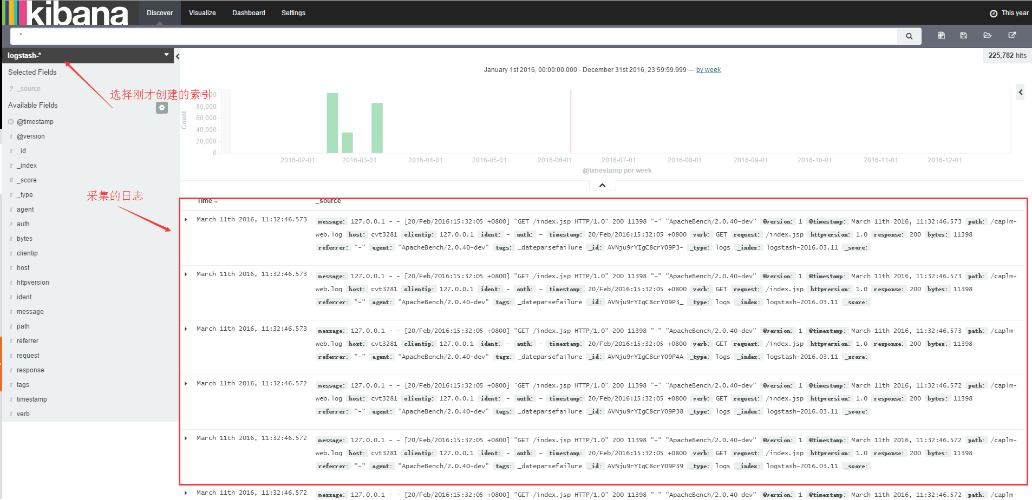
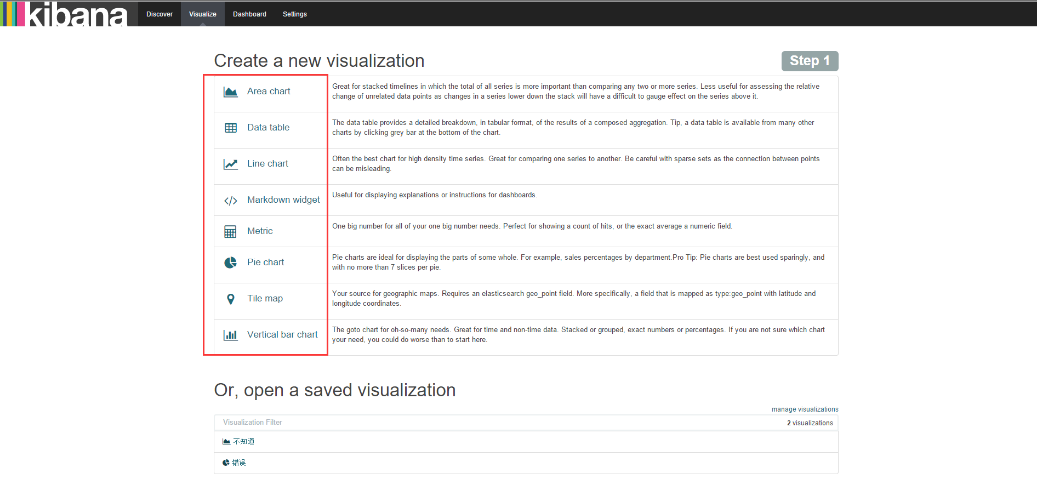
3、绘制数据图(“Visualize”)
四、那些坑
1、国内网上的配置大多比较旧,google上提问和官网查阅,但是官网例子也太简单;
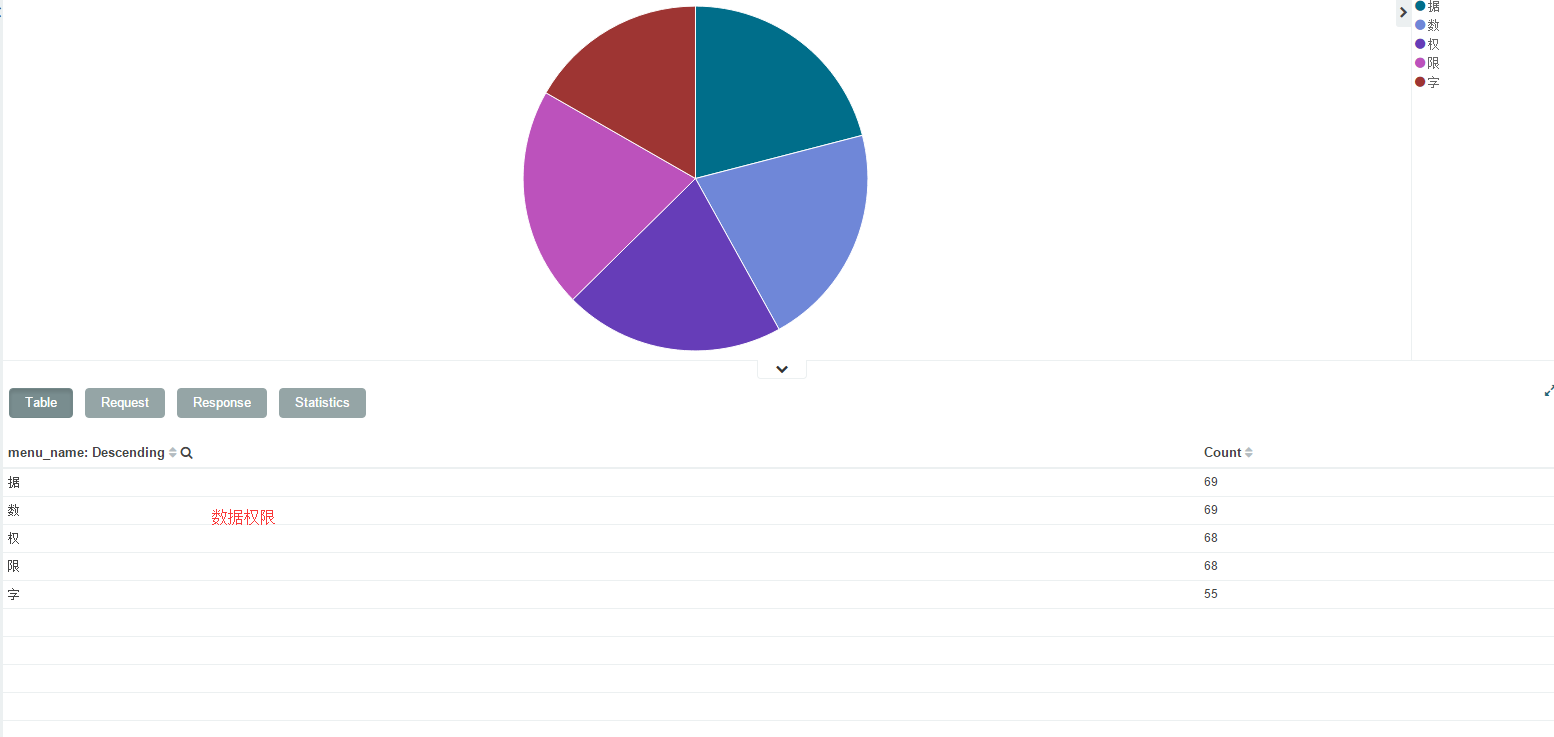
2、kibana使用中文进行统计分组的解析会单个字
3、常用网址
Logstash官方地址:
https://www.elastic.co/guide/en/logstash/current/index.html
ELK中文指南
https://www.gitbook.com/book/chenryn/kibana-guide-cn/details
在线正则校验
http://grokdebug.herokuapp.com/
ELK讨论社区
https://discuss.elastic.co/















 1152
1152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









