







继续上周的Map介绍,上周介绍了AbstractMap和Map类,这次介绍HashMap和HashTable。从名字中可以看出来,两个类的实现都应该和哈希有关。这两个最本质的区别就是HashMap没有实现线程安全,而Hashtble是线程安全的。接下来讲一下具体的实现和一些方法。
一、实现方法:
两者的实现方法都是一样的,都是通过散列表的形式来进行组织的,在HashMap中,有一个Entry<K, V>[] 类型的table变量,该变量就是散列表,其实就是Entry的一个数组。其中还有size变量,代表当前表中Entry的数量;threshold代表当前表的阀值,当数量超过这个阀值,那么就要进行扩容;loadFactor变量代表装载因子,默认值为0.75;modCount变量表示添加删除的次数,作用是当用Iterator进行遍历时,如果在Iterator进行遍历的时候,modCount值发生改变,会跑出ConcurrentModificationException异常,从而终止遍历。在HashMap进行操作的时候,基本单位是Entry,Entry的属性如下:

图中可以看到,Entry有四个属性,key、value、next、hash。其中next为指向Entry的引用。在HashMap中,整体的组织结构如下图:
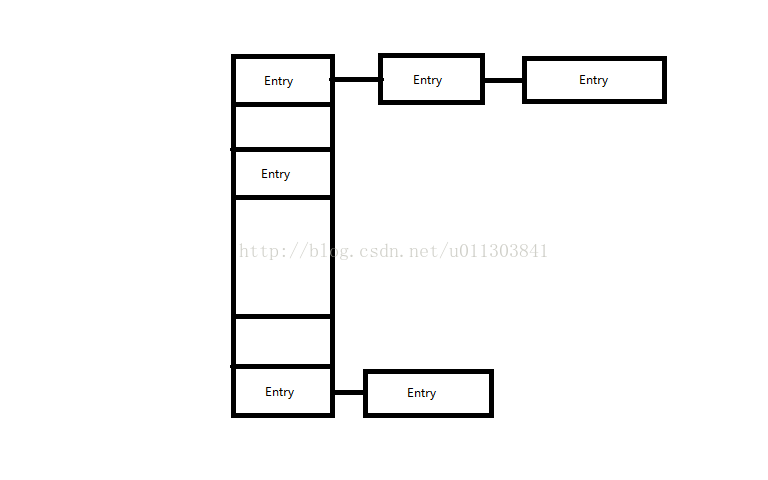
如图所示,在发生冲突的时候,是通过链表的形式附加上去的。
二:HashMap中具体的一些方法:
1. V put(K key, V value)方法:
首先看源代码:
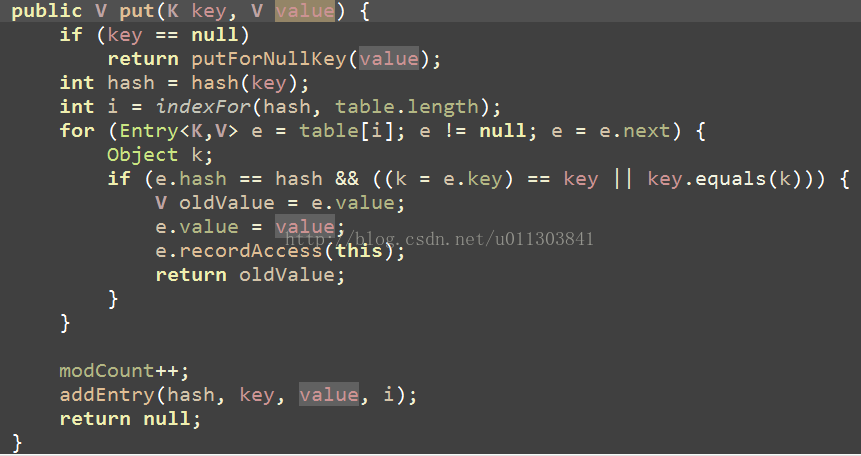
在这个方法中,首先判断key的值是否为null,如果为null的时候,那么就插入null值,在这里要提一下的是,在HashMap中允许key为null的现象,但是只允许存在一个,如果添加了两个key为null的键值对,那么第二个的值会覆盖第一个。插入的null值会在table[0]的位置下。然后获取key的值,indexFor()方法是计算当前hash值在table的位置,具体的方法是将hash值和(表的长度-1)按位与,这个是什么意思呢?是这样的, 在HashMap中规定table的长度为2的幂,所以这个就是取模的意思。然后找到该键值对在table数组的位置,然后开始沿着链表进行查找,如果找到了key值相同的,就把value值覆盖。在这里面有一个e.recordAccess(this); 这个方法是空的,什么都没干,应该是留着继承时扩展用的。如果没有找到的话,那么modCount++,关于modCount后面还会有介绍。然后调用方法addEntry(), addEntry()源码如下:
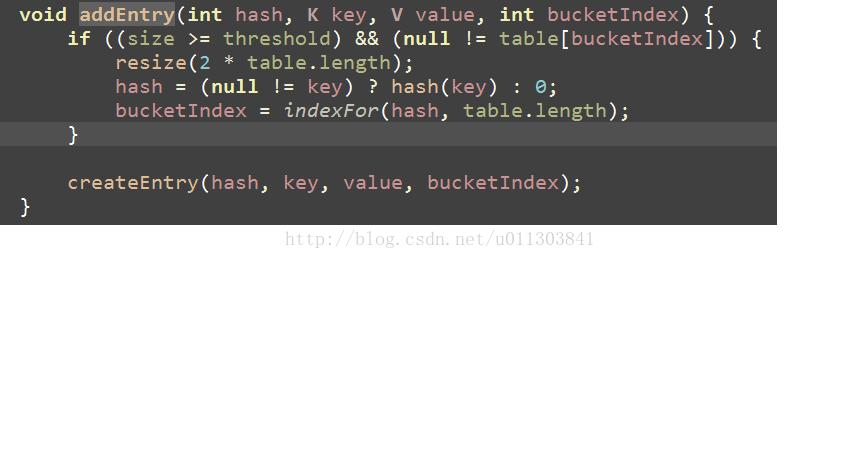
在这个方法中,他判断当前的数量是否已经达到阀值,如果已经达到了,那么就需要进行rehash操作,这时候就要将散列表扩容,扩容的原则是比目前所需要的size大的最小的2的幂次方,扩容完以后,然后会把之前在表中已经存在的元素,整个重新遍历一遍,重新放入,所以这个操作时非常耗费资源的。接下来调用了createEntry方法,在这个方法中,是把新添加的元素加到链表的最前端,至于为什么要加到最前端,我还不太了解。这样,整个put操作完成。
2. remove(K key)
在remove()方法中,首先根据key值计算hash值,然后根据indexFor()取模,找到在table表中的位置,然后开始查找链表,如果找到该元素,那么就把他前面的那个元素的指针指向他后面的那个元素,然后size--, modCount++。
3. entrySet()
在调用这个方法的时候,会返回一个EntrySet的类实例,这个类是继承AbstractSet抽象类的,在该类中实现了一些方法,比如contains(),remove(), size(), 这些方法的内部其实都是调用了HashMap本身的方法,所以没有什么好讲的,在这里面还有一个方法,叫做iterator(), 这个方法是返回一个EntryIterator的实例,这个就是一个迭代器,用来访问HashMap里面的元素,该类继承HashIterator抽象类,在HashIterator类中,有四个变量,next、expectedModCount、index、current。这四个变量分别是指向Entry的引用、和modCount相对应的、当前所在的table索引和当前的位置,当调用next()方法时,首先会找到table数组的第一个有元素的位置,然后再根据链表往下查找,一直到结束,这样就遍历了整个Map。
三:fast-fail机制
在HashMap里面有一个叫做fast-fail的机制,那么这个机制到底是什么呢? 之前有讲到一个变量叫做modCount,在每次添加或者删除元素的时候,这个值都会+1。在每次调用iterator()获取迭代器访问Map的时候,首先会进行复制,将modCount的值赋值到expectedModCount里面,然后当每次调用next()的时候,首先会检查当前的modCount值是否和之前传递进来的一致,如果不一致,那么程序就会直接抛出ConcurrentModificationException异常,这样讲可能不太理解。因为在HashMap每次增加元素的时候都先会去检查当前的大小是否超过阀值,如果超过阀值,会将table扩容,并且所有的元素都将进行重新排序!这个以为着,之前的引用都将失效,所以为了避免发生这个情况,在这里直接抛出异常。如果你在调用iterator()方法获取迭代器后,再在Map中增加元素,那么下次调用iterator.next(),就会抛出异常。
关于HashTable,其中的实现机理和HashMap是一样的,就是在操作的时候,对于数组进行加锁,增加了线程安全,但是效率上面会有锁下降,目前HashTable的应用范围比较少,如果需要用线程安全,ConcurrentHashMap在性能上比HashTable更好。















 915
915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









