







hdfs-site.xml:
类似Linux上的文件句柄的限制,当datanode上的连接数超过配置时,datanode就会拒绝连接
提示 could only be replicated to 0 nodes instead
<property>
<name>dfs.datanode.max.xcievers</name>
<value>8192</value>
</property>指定journalNode集群在对NameNode的数据进行共享时,自己存储数据的磁盘路径
发现其默认每隔2分钟溢出成一个新的文件
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/jn/data</value>
</property>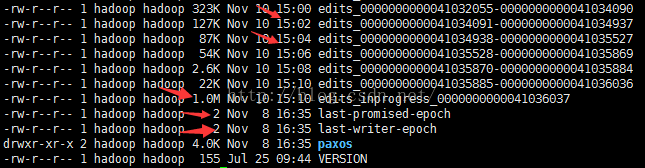
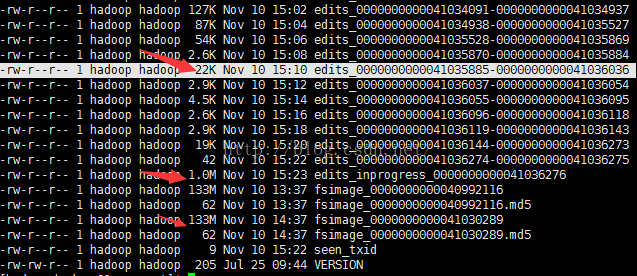
namenode 和 datanode的数据在本地磁盘上的备份
可看到namenode中的数据与journalnode中的数据是一致同步的
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/data/hadoop/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/data/hadoop/data</value>
</property>
core-site.xml:
垃圾箱(删除的数据会进入到垃圾箱,覆盖的数据不会)
可以通过手工删除.Trash/* 下的文件来达到清空回收站,也可以根据设置的时间定时删除
<property>
<name>fs.trash.interval</name>
<value>2880</value>
<description>save one day(2880 min---60*24*2)</description>
</property>














 1802
1802











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









