







写好的爬虫,现在就让他跑起来,把数据load到数据库
具体操作:
1.安装python 链接mysql的库:pip install PyMySql
2.新建数据库及表:
DROP TABLE IF EXISTS `news`;
CREATE TABLE `news` (
`newsid` varchar(255) DEFAULT NULL,
`title` varchar(255) DEFAULT NULL,
`newssource` varchar(255) DEFAULT NULL,
`dt` varchar(255) DEFAULT NULL,
`article` mediumtext,
`editor` varchar(255) DEFAULT NULL,
`id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=22 DEFAULT CHARSET=utf8;3.操作数据库方法:
import pymysql
def connDB():
#连接数据库
conn=pymysql.connect(host='localhost',user='root',passwd='',db='pythod_pacong',charset='utf8')
cur=conn.cursor()
return (conn,cur)
def exeUpdate(conn,cur,sql):
#更新语句,可执行Update,Insert语句
sta=cur.execute(sql)
conn.commit()
return (sta)
def exeQuery(cur,sql):
#查询语句
cur.execute(sql)
result = cur.fetchone()
return (result)
def connClose(conn,cur):
#关闭所有连接
cur.close()
conn.close()4.开始爬虫load数据入库:
connDB1 = connDB()
sql = "insert into news(newsid,title,newssource,dt,article,editor) values"
urls = getNewsURLs('http://news.sina.com.cn/china/')
for url in urls:
sql1 = sql+ '("'+ getNewsDetail(url)["newsid"] +'","'+getNewsDetail(url)["title"]+'","'+getNewsDetail(url)["newssource"]+'","'+getNewsDetail(url)["dt"]+'","' +getNewsDetail(url)["article"] +'","' + getNewsDetail(url)["editor"] + '")'
print(exeUpdate(connDB1[0],connDB1[1],sql1))
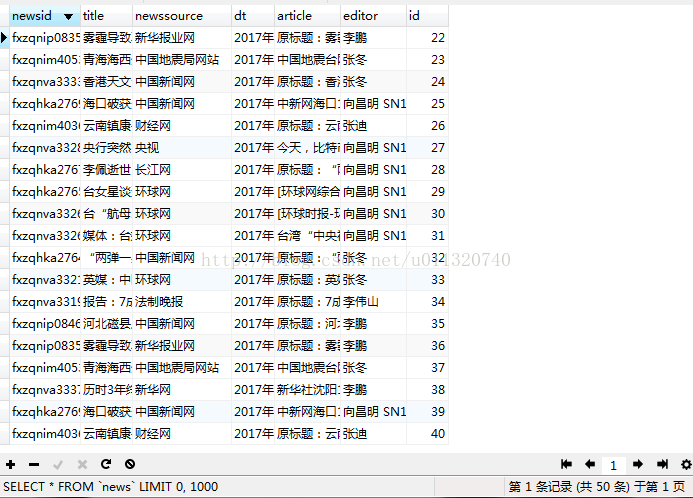
connClose(connDB1[0],connDB1[1])5.爬取结果如下:














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









