







原文转自:https://gist.github.com/CMCDragonkai/10ab53654b2aa6ce55c11cfc5b2432a4
了解Linux可执行文件的内存布局
调试内存所需的工具:
- hexdump
- objdump
- readelf
- xxd
- gcore
- strace
- diff
- cat
我们将通过这个:https://sploitfun.wordpress.com/2015/02/10/understanding-glibc-malloc/和http://duartes.org/gustavo/blog/post/anatomy-of-a-program-in-memory/
实际上有很多C内存分配器。不同的内存分配器将以不同的方式布局内存。目前glibc的内存分配器是ptmalloc2。它是从dlmalloc分叉的。在fork之后,添加了线程支持,并于2006年发布。集成后,代码更改直接转换为glibc的malloc源代码本身。所以glibc的malloc有很多变化,与原版不同ptmalloc2。
glibc中的malloc在内部调用brk或者mmap系统调用来从OS获取内存。的brk系统调用通常用于增加堆的大小,而mmap将用于加载的共享库,线程,以及许多其他的事情创建新区域。它实际上切换到使用mmap而不是brk当请求的内存量大于MMAP_THRESHOLD。我们通过使用查看正在进行的调用strace。
在过去的使用中dlmalloc,当2个线程同时调用malloc时,只有一个线程可以进入临界区,内存块的freelist数据结构在所有可用线程之间共享。因此,内存分配是一种全局锁定操作。
但是在ptmalloc2中,当2个线程同时调用malloc时,会立即分配内存,因为每个线程都维护一个单独的堆,以及它们自己的freelist块数据结构
为每个线程维护单独的堆和空闲列表的行为称为“每线程竞技场”。
在上一个会话中,我们发现程序内存布局通常在:
User Stack
|
v
Memory Mapped Region for Shared Libraries or Anything Else
^
|
Heap
Uninitialised Data (.bss)
Initialised Data (.data)
Program Text (.text)
0
出于理解的目的,大多数调查内存的工具将低地址放在顶部,将高地址放在底部。
因此,更容易想到这样:
0
Program Text (.text)
Initialised Data (.data)
Uninitialised Data (.bss)
Heap
|
v
Memory Mapped Region for Shared Libraries or Anything Else
^
|
User Stack
问题是,我们没有正确掌握究竟发生了什么。上面的图表太简单,无法完全理解。
让我们编写一些C程序并研究它们的内存结构。
请注意,直接编译或汇编实际上都不会生成可执行文件。这是由链接器完成的,它接受编译/汇编产生的各种目标代码文件,解析它们包含的所有名称并生成最终的可执行二进制文件。http://stackoverflow.com/a/845365/582917
这是我们的第一个程序(使用gcc -pthread memory_layout.c -o memory_layout以下程序编译:
#包括 < stdio.h中> //标准IO
#包括 < stdlib.h中> // C标准库
#包括 < pthread.h > //线程
#包括 < unistd.h中> // UNIX标准库
#包括 < SYS / types.h > //用于linux的系统类型
// getchar基本上就像“读取”
//它提示用户输入
//在这种情况下,输入被丢弃
//这类似于“暂停”延续原语
//但是通过用户解决的暂停输入,我们立即扔掉!
void * thread_func( void * arg){
printf(“在线程1中的malloc之前\ n ”);
getchar();
char * addr =(char *)malloc(1000);
printf(“在malloc之后和在线程1之前释放之前\ n ”);
getchar();
free(addr);
printf(“在帖子1 \ n中释放后”);
getchar();
}
int main(){
char * addr;
printf(“欢迎使用每个线程竞技场示例:: %d \ n ”,getpid());
printf(“主线程中的malloc之前\ n ”);
getchar();
addr =(char *)malloc(1000);
printf(“在malloc之后和主线程之前释放\ n ”);
getchar();
free(addr);
printf(“在主线程中释放后\ n ”);
getchar();
//指向线程的指针1
pthread_t thread_1;
// pthread_ *函数在成功时返回0,其他数字在失败时返回
int pthread_status;
pthread_status = pthread_create(&thread_1,NULL,thread_func,NULL);
if(pthread_status!= 0){
printf(“线程创建错误\ n ”);
返回 - 1 ;
}
//从thread_1返回状态代码
void * thread_1_status;
pthread_status = pthread_join(thread_1,&thread_1_status);
if(pthread_status!= 0){
printf(“ Thread join error \ n ”);
返回 - 1 ;
}
返回 0 ;
}
getchar以上的用法是基本上暂停等待用户输入的计算。这允许我们在检查其内存布局时逐步执行该程序。
的用途pthread是用于创建POSIX线程,这是真正的内核线程被调度上的Linux操作系统。事情si,线程的使用对于检查过程内存布局如何用于许多线程很有意义。事实证明,每个线程都需要自己的堆和堆栈。
这些pthread函数很奇怪,因为它们在成功时返回基于0的状态代码。这是一项pthread操作的成功,它确实会对底层操作系统产生副作用。
正如我们在上面所看到的,参考错误模式有很多用途,也就是说,我们使用引用容器来存储额外的元数据或仅存储数据本身,而不是返回多个值(通过元组)。
现在,我们可以运行该程序./memory_layout(尝试使用Ctrl + Z暂停程序):
$ ./memory_layout
Welcome to per thread arena example::1255
Before malloc in the main thread
此时,程序暂停,我们现在可以通过查看来检查内存内容/proc/1255/maps。这是一个内核提供的虚拟文件,显示程序的确切内存布局。它实际上总结了每个内存部分,因此它有助于理解内存的布局方式,而无需查看特定的字节地址。

/ proc / $ PID / maps中的每一行描述进程中连续虚拟内存的区域。每行都有以下字段:
- address - 区域进程地址空间中的起始和结束地址
- perms - 描述如何访问页面,rwxp或者rwxs在s私有或共享页面的含义,如果进程试图访问权限不允许的内存,则会发生分段错误
- offset - 如果区域由文件映射使用mmap,则这是映射开始的文件中的偏移量
- dev - 如果区域是从文件映射的,这是文件所在的十六进制中的主要和次要设备编号,主要编号指向设备驱动程序,次编号由设备驱动程序解释,或次要编号是设备驱动程序的特定设备,如多个软盘驱动器
- inode - 如果区域是从文件映射的,则这是文件编号
- pathname - 如果区域是从文件映射的,这是文件的名称,有特殊区域的名称如[heap],[stack]和[vdso],[vdso]代表虚拟动态共享对象,其使用通过系统调用切换到内核模式
某些区域在路径名字段中没有任何文件路径或特殊名称,这些是匿名区域。匿名区域由mmap创建,但不附加到任何文件,它们用于杂项,如共享内存,不在堆上的缓冲区,pthread库使用匿名映射区域作为新线程的堆栈。
没有100%保证连续的虚拟内存意味着连续的物理内存。为此,您必须使用没有虚拟内存系统的操作系统。但是连续的虚拟内存确实等于连续的物理内存是一个很好的机会,至少没有指针追逐。仍处于硬件级别,有一种特殊的虚拟到物理内存转换设备。所以它仍然非常快。
使用该bc工具非常重要,因为我们需要在这里经常转换十六进制和十进制。我们可以使用它bc <<< 'obase=10; ibase=16; 4010000 - 4000000',它基本上4010000 - 4000000使用十六进制数字进行减法,然后将结果转换为十进制数10。
关于主要次要数字的旁注。您可以使用ls -l /dev | grep 252或lsblk | grep 252查找与major:minor数字对应的设备。哪里0d252 ~ 0xfc。
这列出了Linux设备驱动程序的所有主要和次要编号分配:http://www.lanana.org/docs/device-list/devices-2.6+.txt
它还显示240到254之间的任何东西都用于本地/实验用例。232 - 239也未分配。并保留255。我们现在可以确定有问题的设备是设备映射器设备。因此它使用保留用于本地/实验用途的范围。主要和次要数字最多只能达到255,因为它是单个字节中最大的十进制数。单个字节是:0b11111111或0xFF。单个十六进制数字是半字节。2个十六进制数字是一个字节。
首先要意识到的是,内存地址从低到高开始,但每次运行此程序时,许多区域都会有不同的地址。这意味着对于某些地区,地址不是静态分配的。这实际上是由于安全功能,通过随机化某些区域的地址空间,使攻击者更难以获取他们感兴趣的特定内存。但是有些区域总是固定的,因为你需要它们要修复,以便您知道如何加载程序。我们可以看到程序数据和可执行内存始终是固定的vsyscall。实际上可以创建人们称之为“PIE”(位置无关的可执行文件)的东西,它实际上甚至使程序数据和可执行内存也随机化,但是默认情况下不会启用它,并且它也会阻止编译程序静态地,强制它被链接(https://sourceware.org/ml/binutils/2012-02/msg00249.html)。此外,“PIE”可执行文件会引发一些性能问题(32位与64位计算机上的不同类型的问题)。某些区域的地址随机化称为“PIC”(位置无关代码),并且已在Linux上默认启用了相当长的一段时间。有关更多信息,请参阅:http://blog.fpmurphy.com/2008/06/position-independent-executables.html和http://eli.thegreenplace.net/2011/08/25/load-time-relocation-of-shared-libraries
可以使用gcc -fPIE -pie ./hello.c -o hello生成“PIE”可执行文件来编译上述程序。有一些关于nixpkgs的讨论,默认情况下为64位二进制文件编译为“PIE”,但由于严重的性能问题,32位二进制文件仍然是unPIEd。请参阅:https://github.com/NixOS/nixpkgs/issues/7220
顺便说一句:如果我们有一个工具可以检查/proc/$PID/maps并给出精确的人类可读字节大小,那不是很好吗?
让我们详细介绍每个地区。请记住,这仍然是程序的开始,没有malloc发生,所以没有[heap]区域。
0 - 400000 - 4194304 B - 4096 KiB ~ 4 MiB - NOT ALLOCATED
400000 - 401000 - 4096 B - 4 KiB
600000 - 601000 - 4096 B - 4 KiB
601000 - 602000 - 4096 B - 4 KiB
这是我们最初的记忆范围。我添加了一个额外的组件,从0地址开始并到达40 00 00地址。地址似乎是包容性的,右侧是独占的。但请记住,地址从0开始。因此,使用它bc <<< 'obase=10;ibase=16 400000 - 0'来获取该范围内的实际字节数而不添加或减去1 是合法的。在这种情况下,第一个未分配的区域大约为4 MiB。当我说未分配时,我的意思是它没有代表/proc/$PID/maps。这可能意味着两件事情中的任何一件,要么文件没有显示所有已分配的内存,要么它不认为这样的内存值得显示,或者实际上没有分配内存。
我们可以找出是否真的有记忆有,通过创建介于两者之间的指针内存地址0和400000,并尝试取消引用它。这可以通过将整数转换为指针来完成。我之前尝试过它,它会导致段错误,这意味着之间确实没有分配内存0-400000
#包括 < stdio.h中>
int main(){
// 0x0是十六进制文字,默认为有符号整数
//这里我们将它转换为一个void指针
//然后将它赋值给一个声明为void指针的值
//这是创建一个任意指针的正确方法C
void * addr =( void *) 0x0 ;
//为了打印出该指针存在的内容,我们必须取消引用指针
//但是C不知道如何处理void类型的值
//这意味着,我们重新设置了一个指向char指针的void指针
// char是一些任意字节,所以希望它是一个可打印的ASCII值
//实际上,我们不需要希望,因为我们已经使printf专门打印了char的十六进制表示,因此它不需要是一个可打印的ascii value
printf( “ 0x %x \ n ”,(( char *)addr)[ 0 ]); //打印0x0
printf(“ 0x %x \ n ”,(( char *)addr)[ 1 ]); //打印0x1
printf( “ 0x %x \ n ”,(( char *)addr)[ 2 ]); //打印0x2
}
运行上面给我们一个简单的segmentation fault。因此,证明这/proc/$PID/maps是给我们真相的,之间确实没有任何关系0-400000。
问题变成了,为什么这个大约有4个MiB差距?为什么不从0开始分配内存?那么这只是malloc和链接器实现者的任意选择。他们只是决定在64位ELF可执行文件上,非PIE可执行文件的入口点应该是0x400000,而对于32位ELF可执行文件,入口点是0x08048000。一个有趣的事实是,如果您生成与位置无关的可执行文件,则起始地址将改为0x0。
看到:
- http://stackoverflow.com/questions/7187981/whats-the-memory-before-0x08048000-used-for-in-32-bit-machine
- http://stackoverflow.com/questions/12488010/why-the-entry-point-address-in-my-executable-is-0x8048330-0x330-being-offset-of
- http://stackoverflow.com/questions/14314021/why-linux-gnu-linker-chose-address-0x400000
输入地址由链接编辑器在创建可执行文件时设置。加载程序将程序文件映射到ELF头指定的地址,然后将控制权转移到入口地址。
加载地址是任意的,但是使用SYSV for x86进行了标准化。每种架构都有所不同。上面和下面的内容也是任意的,并且通常在库和mmap()区域中链接。
它基本上意味着程序可执行文件在开始执行之前就被加载到内存中。可执行文件的入口点可以通过获取readelf。但这是另一个问题,为什么要给出的入口点readelf,而不是0x400000。事实证明,该入口点是考虑OS应该开始执行的实际点,而0x400000入口点和入口点之间的位置用于EHDR和PHDR,这意味着ELF头和程序头。我们稍后会详细研究这个问题。
$ readelf --file-header ./memory_layout | grep 'Entry point address'
Entry point address: 0x400720
接下来我们有:
400000 - 401000 - 4096 B - 4 KiB
600000 - 601000 - 4096 B - 4 KiB
601000 - 602000 - 4096 B - 4 KiB
正如您所看到的,我们有3个内存部分,每个部分都有4个KiB,并从中分配/home/vagrant/c_tests/memory_layout。
这些部分是什么?
第一部分:“文本段”。
第二部分:“数据部分”。
第三部分:“BSS细分”。
文本段存储进程的二进制映像。例如,数据段存储由程序员初始化的静态变量static char * foo = "bar";。例如,BSS段存储未初始化的静态变量,这些变量用零填充static char * username;。
我们的程序现在非常简单,每个看起来都非常适合4 KiB。怎么这么完美!?
那么,Linux OS和许多其他操作系统的页面大小默认设置为4 KiB。这意味着最小可寻址存储器段是4 KiB。请参阅:https://en.wikipedia.org/wiki/Page_%28computer_memory%29
页面,内存页面或虚拟页面是固定长度的连续虚拟内存块,由页表中的单个条目描述。它是虚拟内存操作系统中内存管理的最小数据单元。
运行getconf PAGESIZE显示4096字节。
因此,这意味着每个段可能远小于4096字节,但它最多可填充4096个字节。
如前所示,可以创建一个任意指针,并打印出该字节存储的值。我们现在可以为上面显示的段执行此操作。
但是,嘿,我们可以做得更好。而不仅仅是黑客攻击个别字节。我们可以认识到这些数据实际上是按结构组织的。
什么样的结构?我们可以查看readelf源代码来揭示相关的结构。这些结构似乎不是标准C库的一部分,因此我们不能只包含一些东西来实现这一点。但代码很简单,所以我们可以复制和粘贴。请参阅:http://rpm5.org/docs/api/readelf_8h-source.html
看一下这个:
//用gcc编译-std = C99 -o elfheaders ./elfheaders.c
#包括 < stdio.h中>
#包括 < stdint.h >
//来自:http://rpm5.org/docs/api/readelf_8h-source.html
//这里我们只关注64位可执行文件,32位可执行文件有不同大小的标题
typedef uint64_t Elf64_Addr;
typedef uint64_t Elf64_Off;
typedef uint64_t Elf64_Xword;
typedef uint32_t Elf64_Word;
typedef uint16_t Elf64_Half;
typedef uint8_t Elf64_Char;
#定义 EI_NIDENT 16
//这个结构正好是64个字节
//这意味着它来自0x400000 - 0x400040
typedef struct {
Elf64_Char e_ident [EI_NIDENT]; // 16 B
Elf64_Half e_type; // 2 B
Elf64_Half e_machine; // 2 B
Elf64_Word e_version; // 4 B
Elf64_Addr e_entry; // 8 B
Elf64_Off e_phoff; // 8 B
Elf64_Off e_shoff; // 8 B
Elf64_Word e_flags; // 4 B
Elf64_Half e_ehsize; // 2 B
Elf64_Half e_phentsize; // 2 B
Elf64_Half e_phnum; // 2 B
Elf64_Half e_shentsize; // 2 B
Elf64_Half e_shnum; // 2 B
Elf64_Half e_shstrndx; // 2 B
Elf64_Ehdr;
//这个结构正好是56个字节
//这意味着它来自0x400040 - 0x400078
typedef struct {
Elf64_Word p_type; // 4 B
Elf64_Word p_flags; // 4 B
Elf64_Off p_offset; // 8 B
Elf64_Addr p_vaddr; // 8 B
Elf64_Addr p_paddr; // 8 B
Elf64_Xword p_filesz; // 8 B
Elf64_Xword p_memsz; // 8 B
Elf64_Xword p_align; // 8 B
} Elf64_Phdr;
int main(int argc,char * argv []){
//从objdump的检查和/ PROC / ID /地图,我们可以看到,这是加载到内存中的第一件事
//最早在虚拟存储器地址空间,对于64位的ELF可执行
//%LX需要64位十六进制,而%x仅适用于32位十六进制
Elf64_Ehdr * ehdr_addr =(Elf64_Ehdr *)0x400000 ;
printf(“魔术:0x ”);
for(unsigned int i = 0 ; i <EI_NIDENT; ++ i){
printf(“ %x ”,ehdr_addr-> e_ident [i]);
}
printf(“ \ n ”);
printf(“ Type:0x %x \ n ”,ehdr_addr-> e_type);
printf(“机器:0x %x \ n ”,ehdr_addr-> e_machine);
printf(“ Version:0x %x \ n ”,ehdr_addr-> e_version);
printf(“条目: %p \ n ”,(void *)ehdr_addr-> e_entry);
printf(“ Phdr Offset:0x %lx \ n ”,ehdr_addr-> e_phoff);
printf(“ Section Offset:0x %lx \ n ”,ehdr_addr-> e_shoff);
printf(“ Flags:0x %x \ n ”,ehdr_addr-> e_flags);
printf(“ ELF标题大小:0x %x \ n ”,ehdr_addr->e_ehsize);
printf(“ Phdr Header Size:0x %x \ n ”,ehdr_addr-> e_phentsize);
printf(“ Phdr Entry Count:0x %x \ n ”,ehdr_addr-> e_phnum);
printf(“ Section Header Size:0x %x \ n ”,ehdr_addr-> e_shentsize);
printf(“ Section Header Count:0x %x \ n ”,ehdr_addr-> e_shnum);
printf(“ Section Header Table Index:0x %x \ n ”,ehdr_addr-> e_shstrndx);
Elf64_Phdr * phdr_addr =(Elf64_Phdr *)0x400040 ;
printf(“ Type: %u \ n ”,phdr_addr-> p_type); // 6 - PT_PHDR - 段类型
printf(“标志: %u \ n ”,phdr_addr-> p_flags); // 5 - PF_R + PF_X - rx权限等于chmod binary 101
printf(“ Offset:0x %lx \ n ”,phdr_addr-> p_offset); // 0x40 - 从第一个段所在的文件开头的字节偏移量
printf(“程序虚拟地址: %p \ n ”,(void *)phdr_addr-> p_vaddr); // 0x400040 - 第一个段位于内存
printf中的虚拟地址(“ Program Physical Address:%p \ n ”,(void *)phdr_addr-> p_paddr); // 0x400040 -在该第一区段位于存储器(不相干在Linux上)的物理地址
的printf(“加载文件大小:0X %LX \ n ”,phdr_addr-> p_filesz);// 504 - 从PHDR
printf 文件加载的字节数( “ Loaded mem size:0x %lx \ n ”,phdr_addr-> p_memsz); // 504 - 为PHDR
printf 加载到内存中的字节( “ Alignment: %lu \ n ”,phdr_addr-> p_align); // 8 - 使用模运算对齐(mod p_vaddr palign)===(mod p_offset p_align)
返回 0 ;
}
运行上面给出:
$ ./elfheaders
Magic: 0x7f454c46211000000000
Type: 0x2
Machine: 0x3e
Version: 0x1
Entry: 0x400490
Phdr Offset: 0x40
Section Offset: 0x1178
Flags: 0x0
ELF Header Size: 0x40
Phdr Header Size: 0x38
Phdr Entry Count: 0x9
Section Header Size: 0x40
Section Header Count: 0x1e
Section Header Table Index: 0x1b
Type: 6
Flags: 5
Offset: 0x40
Program Virtual Address: 0x400040
Program Physical Address: 0x400040
Loaded file size: 0x1f8
Loaded mem size: 0x1f8
Alignment: 8
将上述输出与:
$ readelf --file-header ./elfheaders
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x400490
Start of program headers: 64 (bytes into file)
Start of section headers: 4472 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 9
Size of section headers: 64 (bytes)
Number of section headers: 30
Section header string table index: 27
我们基本上只是写了自己的小readelf程序。
因此,它开始有意义地确定实际位于开头的是什么0x400000 - 0x401000,它是告诉操作系统如何使用该程序的所有ELF可执行标头,以及所有其他有趣的元数据。具体来说,这是关于程序的实际入口点(for ./elfheader:0x400490和for ./memory_layout:) 0x400720与实际内存开始之间的位置0x400000。有更多的程序标题要研究,但现在已经足够了。见:http://www.ouah.org/RevEng/x430.htm
但是操作系统从哪里获得这些数据呢?在将数据放入内存之前,它必须获取这些数据。事实证明答案很简单。它只是文件本身。
让我们使用它hexdump来查看文件的实际二进制内容,以及稍后用于objdump将其反汇编到程序集以了解机器代码。
显然启动内存地址,不会启动文件地址。因此0x400000,文件最有可能始于0x0。
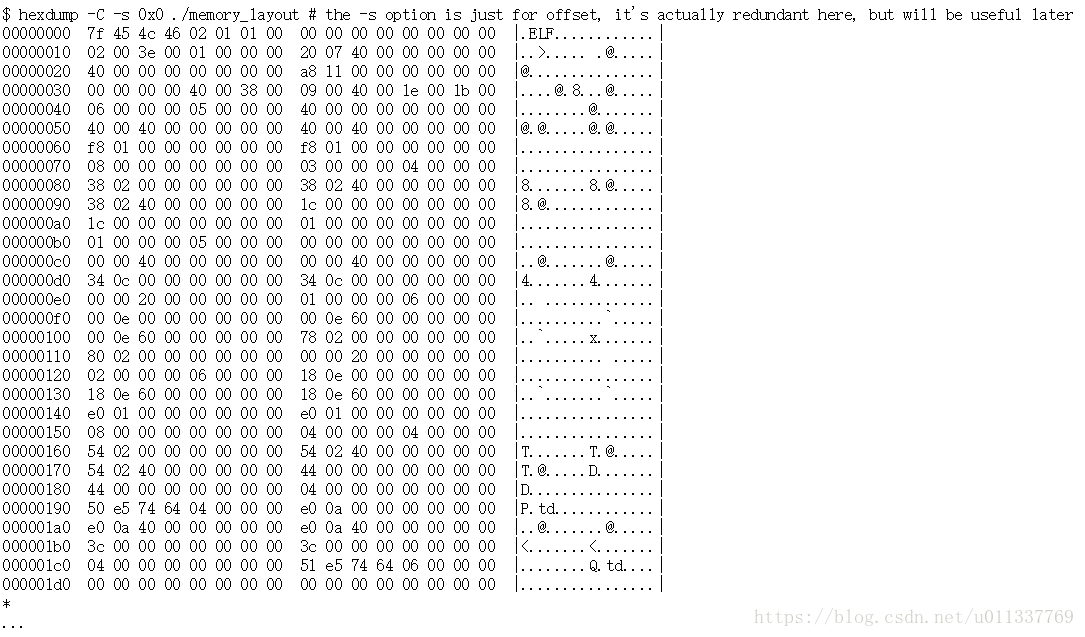
它是一段相当长的文本,所以将其融入其中less是一个好主意。注意,这*意味着“与上面的行相同”。
首先检查前16个字节:7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00。
注意这与下面显示的魔术字节是一样的readelf:
$ readelf -h ./memory_layout | grep Magic
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
事实证明,可以说,0x400000对于gccLinux上编译的非PIE 64位ELF可执行文件0x0,与实际可执行文件本身的起点完全相同。
文件头确实被加载到内存中。但我们可以判断整个文件是否已加载到内存中?我们先来检查文件大小。
$ stat memory_layout | grep Size
Size: 8932 Blocks: 24 IO Block: 4096 regular file
显示该文件是8932字节,大约是8.7 KiB。
我们的内存布局显示,从memory_layout可执行文件中映射出最多4 KiB + 4 KiB + 4 KiB 。
有足够的空间,当然足以适应文件的全部内容。
但我们可以通过迭代整个内存内容来证明这一点,并检查内存中的相关偏移量,看它们是否与文件中的内容相匹配。
为此,我们需要进行调查/proc/$PID/mem。但是,它不是一个普通的文件,你可以从中获取,但你必须做一些有趣的系统调用来从中获取一些输出。没有标准的unix工具可以从中读取,而是我们需要编写一个C程序来读取它。这里有一个示例程序:http://unix.stackexchange.com/a/251769/56970
幸运的是,有一个叫做的东西gdb,我们可以gcore用来将进程的内存转储到磁盘上。它需要超级用户权限,因为我们实际上是访问进程的内存,而内存通常是隔离的!
$ sudo gcore 1255
Program received signal SIGTTIN, Stopped (tty input).
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
0x00007f849c407350 in read () from /lib/x86_64-linux-gnu/libc.so.6
Saved corefile core.1255
[1]+ Stopped ./memory_layout
这会生成一个名为的文件core.1255。这个文件是内存转储,所以要查看它,我们必须使用hexedit。
$ hexdump -C ./core.1255 | less
现在我们拥有了整个内存内容。让我们尝试将它与可执行文件本身进行比较。在我们能够做到这一点之前,我们必须将二进制文件转换为可打印的ASCII。基本上是ASCII装甲二进制程序。的xxd原因是为了这个目的更好的hexdump为我们提供了|字符时,我们使用它可以给混乱的输出diff。
$ xxd ./core.1255 > ./memory.hex
$ xxd ./memory_layout > ./file.hex
我们马上可以看到2种尺寸不一样。在./memory.hex〜1.1 MIB是远远大于较大./file.hex〜37 KIB。这是因为内存转储还包含所有共享库和匿名映射的区域。但我们并不期望它们是相同的,只是整个文件本身是否存在于内存中。
现在可以使用两种文件进行比较diff。
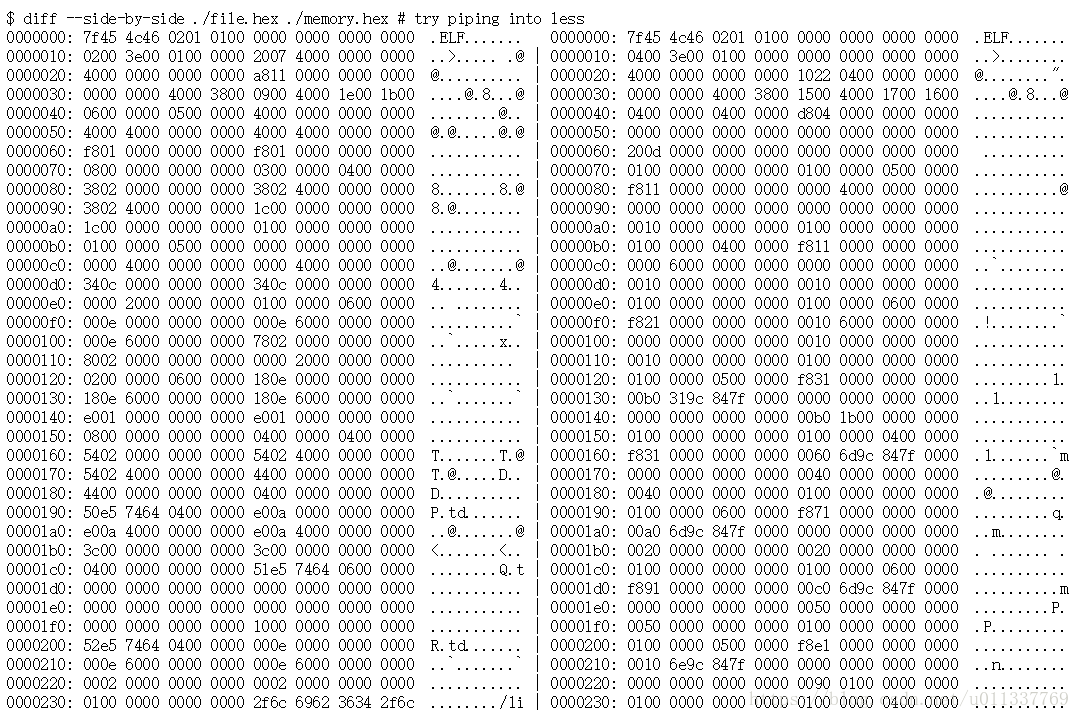
这告诉我们,即使存储器内容和文件内容之间存在一些相似之处,它们也不完全相同。事实上,我们看到从17个字节开始的2个转储之间的偏差,这只是通过ELF魔术字节。
这表明即使存在从文件到内存的映射,它也不是完全相同的字节。无论是那个,还是转储和十六进制转换中的某个地方,字节都被改变了。现在很难说出来。
无论如何,我们还可以使用它objdump来反汇编可执行文件,以查看文件中存在的实际汇编指令。需要注意的一点是,objdump使用程序的虚拟内存地址,就像要执行一样。它没有使用文件中的实际地址。由于我们知道了内存区域/proc/$PID/maps,我们可以检查第一个400000 - 401000区域。
$ objdump --disassemble-all --start-address=0x000000 --stop-address=0x401000 ./memory_layout # use less of course
./memory_layout: file format elf64-x86-64
Disassembly of section .interp:
0000000000400238 <.interp>:
400238: 2f (bad)
400239: 6c insb (%dx),%es:(%rdi)
40023a: 69 62 36 34 2f 6c 64 imul $0x646c2f34,0x36(%rdx),%esp
400241: 2d 6c 69 6e 75 sub $0x756e696c,%eax
400246: 78 2d js 400275 <_init-0x3d3>
400248: 78 38 js 400282 <_init-0x3c6>
40024a: 36 ss
40024b: 2d 36 34 2e 73 sub $0x732e3436,%eax
400250: 6f outsl %ds:(%rsi),(%dx)
400251: 2e 32 00 xor %cs:(%rax),%al
Disassembly of section .note.ABI-tag:
0000000000400254 <.note.ABI-tag>:
400254: 04 00 add $0x0,%al
400256: 00 00 add %al,(%rax)
400258: 10 00 adc %al,(%rax)
40025a: 00 00 add %al,(%rax)
40025c: 01 00 add %eax,(%rax)
40025e: 00 00 add %al,(%rax)
400260: 47 rex.RXB
400261: 4e 55 rex.WRX push %rbp
400263: 00 00 add %al,(%rax)
400265: 00 00 add %al,(%rax)
400267: 00 02 add %al,(%rdx)
400269: 00 00 add %al,(%rax)
...
与gcore手动取消引用任意指针不同,我们可以看到objdump不能或不会向我们显示内存内容400000 - 400238。相反,它开始显示400238。这是因为来自的东西400000 - 400238不是汇编指令,它们只是元数据,因此objdump不会打扰它们,因为它是为了转储汇编代码而设计的。另一件需要理解的是,elipsis ...(在上面的例子中未显示)(不要与我自己的...意思相混淆输出是一个摘录)意味着空字节。该objdump显示逐字节机器代码及其反编译的等效汇编指令。这是一个反汇编程序,因此输出程序集并不完全是人类写的东西,因为可以进行优化,并且丢弃了大量的语义信息。重要的是要注意右边的十六进制地址表示起始字节地址,如果右边有多个十六进制字节数字,则表示它们作为单个汇编指令连接起来。所以两者之间的差距400251 - 400254由3个十六进制字节表示2e 32 00。
让我们跳到一个有趣的地方,比如0x400720报道的实际“入口点” readelf --file-header ./memory_layout。
$ objdump --disassemble-all --start-address=0x000000 --stop-address=0x401000 ./memory_layout | less +/400720
...
Disassembly of section .text:
0000000000400720 <_start>:
400720: 31 ed xor %ebp,%ebp
400722: 49 89 d1 mov %rdx,%r9
400725: 5e pop %rsi
400726: 48 89 e2 mov %rsp,%rdx
400729: 48 83 e4 f0 and $0xfffffffffffffff0,%rsp
40072d: 50 push %rax
40072e: 54 push %rsp
40072f: 49 c7 c0 a0 09 40 00 mov $0x4009a0,%r8
400736: 48 c7 c1 30 09 40 00 mov $0x400930,%rcx
40073d: 48 c7 c7 62 08 40 00 mov $0x400862,%rdi
400744: e8 87 ff ff ff callq 4006d0 <__libc_start_main@plt>
400749: f4 hlt
40074a: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)
...
向上滚动,我们看到objdump将此报告为实际.text部分,并且在400720此处,这是程序的入口点。我们这里有的是由CPU执行的真正的第一个“过程”,即函数背后的main功能。当你避开运行时库以生成一个独立的C可执行文件时,我认为你可以直接在C中使用它。这里的程序集是x86 64位程序集(https://en.wikipedia.org/wiki/X86_assembly_language),我想这是为了在向后兼容的Intel / AMD 64位处理器上运行。我不知道这个特定的程序集,所以我们稍后将在http://www.cs.virginia.edu/~evans/cs216/guides/x86.html中进行研究。
那么我们的其他两个部分(我们可以看到有一个跳过401000 - 600000,这也可以是链接器实现中的任意选择):
600000 - 601000 - 4096 B - 4 KiB
601000 - 602000 - 4096 B - 4 KiB
$ objdump --disassemble-all --start-address=0x600000 --stop-address=0x602000 ./memory_layout | less
现在谈的不多。它似乎0x600000包含更多的数据和汇编。但实际的地址.data和.bss似乎是:
Disassembly of section .data:
0000000000601068 <__data_start>:
...
0000000000601070 <__dso_handle>:
...
Disassembly of section .bss:
0000000000601078 <__bss_start>:
...
事实证明,我们没有任何东西.data和.bss。这是因为我们的./memory_layout.c程序中没有任何静态变量!
总结一下,我们对内存布局的初步了解是:
0
Program Text (.text)
Initialised Data (.data)
Uninitialised Data (.bss)
Heap
|
v
Memory Mapped Region for Shared Libraries or Anything Else
^
|
User Stack
现在我们意识到它实际上是:
0
Nothing here, because it was just an arbitrary choice by the linker
ELF and Program and Section Headers - 0x400000 on 64 bit
Program Text (.text) - Entry Point as Reported by readelf
Nothing Here either
Some unknown assembly and data - 0x600000
Initialised Data (.data) - 0x601068
Uninitialised Data (.bss) - 0x601078
Heap
|
v
Memory Mapped Region for Shared Libraries or Anything Else
^
|
User Stack
好的,继续吧。在我们的可执行文件内存之后,我们有一个巨大的跳跃601000 - 7f849c31b000。

这大概是127 Tebibytes的一大步。为什么地址空间如此大的跳跃?这就是malloc实现的用武之地。本文档https://github.com/torvalds/linux/blob/master/Documentation/x86/x86_64/mm.txt以这种方式显示了内存的结构:

我们可以看到,Linux的内存映射保留了第一个0000000000000000 - 00007fffffffffff用户空间内存。事实证明,47位足以保留大约128 TiB。http://unix.stackexchange.com/a/64490/56970
好吧,如果我们看看这些内存的第一个和最后一个:
7f849c31b000-7f849c4d6000 r-xp 00000000 fc:00 1579071 /lib/x86_64-linux-gnu/libc-2.19.so
...
7fffb5dfe000-7fffb5e00000 r-xp 00000000 00:00 0 [vdso]
看起来这些区域几乎处于为用户空间存储器保留的128 TiB范围的最底部。考虑到有一个127 TiB间隙,这基本上意味着我们的malloc使用0000000000000000 - 00007fffffffffff两端的用户空间范围。从低端开始,它会向上扩展堆(在地址编号中向上)。在高端时,它会向下增加堆栈(在地址编号中向下)。
同时,堆栈实际上是内存的固定部分,因此它实际上不能像堆一样增长。在高端,但低于堆栈,我们看到为共享库和共享库可能使用的匿名缓冲区分配了大量内存区域。
我们还可以查看可执行文件正在使用的共享库。这确定了在启动时哪些共享库也将加载到内存中。但请记住,库和代码也可以动态加载,链接器无法看到。顺便说一下ldd,“列出动态依赖关系”。
$ ldd ./memory_layout
linux-vdso.so.1 => (0x00007fff1a573000)
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007f361ab4e000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f361a788000)
/lib64/ld-linux-x86-64.so.2 (0x00007f361ad7a000)
你会注意到,如果你ldd多次运行,每次打印共享库的不同地址。这对应于多次重新运行程序并检查/proc/$PID/maps它还显示共享库的不同地址。这是由于上面讨论的“PIE”位置无关代码。基本上每次使用ldd它都会调用链接器,链接器会执行地址随机化。有关地址空间随机化背后原因的更多信息,请参阅:ASLR。您还可以通过运行检查内核是否已启用ASLR cat /proc/sys/kernel/randomize_va_space。
我们可以看到实际上有4个共享库。该vdso库不是从文件系统加载的,而是由OS提供的。
另外:/lib64/ld-linux-x86-64.so.2 => /lib/x86_64-linux-gnu/ld-2.19.so,它是一个符号链接。
最后我们在最后几个地区:
7fffb5d61000-7fffb5d82000 rw-p 00000000 00:00 0 [stack]
7fffb5dfe000-7fffb5e00000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
以下是每个地区的相关尺寸:
7fffb5d61000 - 7fffb5d82000 - [stack] - 135168 B - 132 KiB
7fffb5dfe000 - 7fffb5e00000 - [vdso] - 8192 B - 8 KiB
ffffffffff600000 - ffffffffff601000 - [vsyscall] - 4096 B - 4 KiB
我们的初始堆栈大小分配为132 KiB。我怀疑这可以通过运行时或编译器标志来改变。
那是什么vdso和vsyscall?两者都是允许更快系统调用的机制,即在用户空间和内核空间之间没有上下文切换的系统调用。在vsyscall现在已经换成了vdso,但vsyscall留给有兼容性的原因。主要区别在于:
- vsyscall- ffffffffff600000即使启用了PIC或PIE,也始终固定为最大尺寸为8 MiB
- vdso - 没有修复,但行为像共享库,因此其地址受ASLR(地址空间布局随机化)的影响
- vsyscall- 提供3个系统调用: gettimeofday( 0xffffffffff600000),time(0xffffffffff600400),getcpu(0xffffffffff600800),即使它ffffffffff600000 - ffffffffffdfffff在64位ELF可执行文件中给出了Linux 的保留范围8 MiB。
- vdso-提供了4个系统调用:__vdso_clock_gettime,__vdso_getcpu,__vdso_gettimeofday和__vdso_time,然而更多的系统调用可以被添加到vdso在未来。
有关更多信息vdso,并vsyscall请参阅:https://0xax.gitbooks.io/linux-insides/content/SysCall/syscall-3.html
值得指出的是,现在我们已经超过了为用户空间内存保留的128 TiB,我们现在正在查看由操作系统提供和管理的内存段。如下所示:https://github.com/torvalds/linux/blob/master/Documentation/x86/x86_64/mm.txt这些部分是我们正在讨论的内容。
ffff800000000000 - ffff87ffffffffff (=43 bits) guard hole, reserved for hypervisor
ffff880000000000 - ffffc7ffffffffff (=64 TB) direct mapping of all phys. memory
ffffc80000000000 - ffffc8ffffffffff (=40 bits) hole
ffffc90000000000 - ffffe8ffffffffff (=45 bits) vmalloc/ioremap space
ffffe90000000000 - ffffe9ffffffffff (=40 bits) hole
ffffea0000000000 - ffffeaffffffffff (=40 bits) virtual memory map (1TB)
... unused hole ...
ffffec0000000000 - fffffc0000000000 (=44 bits) kasan shadow memory (16TB)
... unused hole ...
ffffff0000000000 - ffffff7fffffffff (=39 bits) %esp fixup stacks
... unused hole ...
ffffffef00000000 - ffffffff00000000 (=64 GB) EFI region mapping space
... unused hole ...
ffffffff80000000 - ffffffffa0000000 (=512 MB) kernel text mapping, from phys 0
ffffffffa0000000 - ffffffffff5fffff (=1525 MB) module mapping space
ffffffffff600000 - ffffffffffdfffff (=8 MB) vsyscalls
ffffffffffe00000 - ffffffffffffffff (=2 MB) unused hole
在上述部分中,我们目前只看到该vsyscall地区。其余的还没有出现。
现在让我们继续该程序,并分配我们的第一个堆。我们/proc/$PID/maps现在(注意地址已经改变,因为我重新编写了程序):
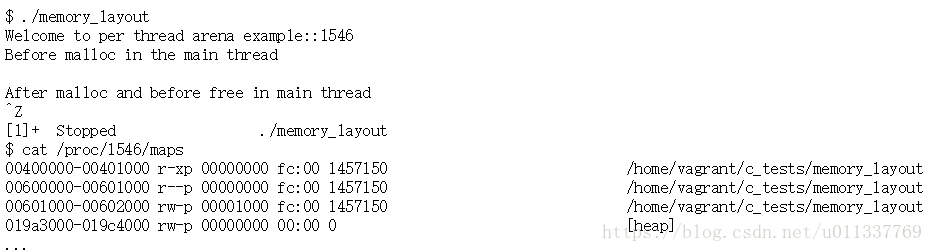
我们现在看到我们的第一个[heap]区域 它确切地说:135168 B - 132 KiB。(目前与我们的堆栈大小相同!)记住我们特别分配了1000个字节:addr = (char *) malloc(1000);在开头。那么一个1000字节怎么变成132千比特?正如我们之前所说的,任何小于MMAP_THRESHOLD使用brk系统调用的东西。似乎使用填充大小调用brk/ sbrk,以减少系统调用的数量和上下文切换的数量。大多数程序最有可能需要超过1000字节的堆,因此系统也可以填充brk调用以缓存一些堆内存,并且只有在耗尽132 KiB的填充堆后才会出现新的brk或mmap增加堆的调用。填充计算完成:
/* Request enough space for nb + pad + overhead */
size = nb + mp_.top_pad + MINSIZE;
凡mp_.top_pad被默认设置为128 * 1024 = 128昆明植物研究所。我们仍然有4个KiB差异。但请记住,我们的页面大小getconf PAGESIZE为4096,意味着每页为4 KiB。这意味着在我们的程序中分配1000字节时,分配的整页为4 KiB。并且4 KiB + 128 KiB是132 KiB,这是我们堆的大小。此填充不是固定大小的填充,而是总是添加到通过brk/ 分配的数量的填充sbrk。这意味着默认情况下128 KiB总是会添加到您尝试分配的内存中。然而,这个填充仅适用于brk/ sbrk,而不是mmap,记住过去MMAP_THRESHOLD,mmap从brk/ 接管sbrk。这意味着将不再应用填充。但是我不确定是否MMAP_THRESHOLD在填充之前或填充之后检查。它似乎应该在填充之前。
可以通过调用来更改填充大小mallopt(M_TOP_PAD, 1);,将其更改M_TOP_PAD为1字节。Mallocing 1000 Bytes现在只会创建一个4 KiB的页面。
有关更多信息,请参阅:http://stackoverflow.com/a/23951267/582917
当分配等于或大于?时,为什么旧的brk/ sbrk被更新的替换?那么/ 调用只允许连续增加堆的大小。如果你只是用于小事情,它应该能够在堆中连续分配,当它到达堆端时,堆可以扩展而没有任何问题。但是对于更大的allocatiosn,使用了,并且这个堆空间确实需要与/ heap空间连续地连接。所以它更灵活。在这种情况下,小型对象的内存碎片会减少。另外,通话更加灵活,从而使/ 可以实现,而mmapMMAP_THRESHOLDbrksbrkmallocmmapbrksbrkmmapbrksbrkmmapmmap无法用brk/ 实现sbrk。brk/的一个限制sbrk是,如果未释放brk/ sbrkheap空间中的顶部字节,则不能减小堆大小。
让我们看一个分配超过的简单程序MMAP_THRESHOLD(它也可以被覆盖使用mallopt):
#包括 < stdlib.h中>
#包括 < stdio.h中>
int main(){
printf(“查看/ proc / %d / maps \ n ”,getpid());
//分配200 KiB,强制使用mmap而不是brk
char * addr =( char *) malloc( 204800);
getchar();
free(addr);
返回 0 ;
}
运行上面的代码strace给我们:

mmap(NULL, 208896, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f3b11972000
它实际上是204800 B + 4096 B = 208 896 B.我不确定为什么要添加额外的4 KiB,因为200 KiB可以被4 KiB的页面大小完全整除。这可能是另一个特点。需要注意的一点是,没有任何明显的方法可以确定我们的程序的系统调用超过其他一些系统调用,但我们可以查看调用的上下文,即前一行和后续行以查找确切的控制流。使用像这样的东西getchar也可以暂停strace。在最终被调用之前,在映射204800个字节之后,可以考虑进行fstat另一个mmap调用getchar。我不知道这些调用来自哪里,所以在将来,我们应该寻找一些简单的方法来标记系统调用,以便我们可以更快地找到它们。该strace告诉我们这个内存映射区域被映射到0x7f3b11972000。看看这个过程/proc/$PID/maps:
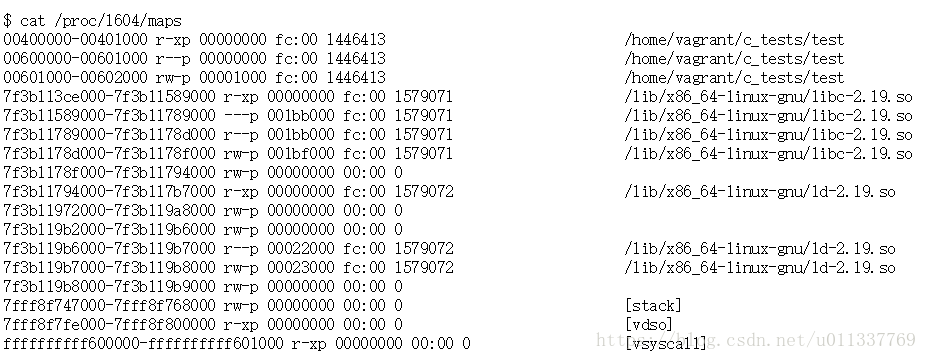
7f3b11972000-7f3b119a8000 rw-p 00000000 00:00 0
如您所见,当malloc切换到使用时mmap,获取的区域不是所谓[heap]区域的一部分,该区域仅由brk/ sbrkcalls提供。它没有标签!我们还可以看到,这种堆不与brk/ sbrkheap 放在同一区域,我们理解它是从低端开始并在地址空间中向上增长。相反,这个mmapped堆与共享库位于同一区域,将其置于保留用户空间地址范围的高端。然而,如图所示的这个区域/proc/$PID/maps实际上是221184 B - 216 KiB。它从208896年正好是12 KiB。另一个谜!为什么我们有不同的字节大小,即使mmap在被strace称为完全208896?
看另一个mmap电话也表明相应的区域/proc/$PID/maps有12 KiB的差异。这里12 KiB可能代表某种内存映射开销,malloc用它来跟踪或理解这里可用的内存类型。或者它也可以是额外的填充。所以我们可以在这里说,有些东西一直在为我们的mmapping添加12 KiB,而且我的200 KiB还增加了4 KiB malloc。
顺便说一句,还有一个工具叫做binwalk,它对于检查可能包含多个可执行文件和元数据的固件映像非常有用。记住,事实上你可以将文件嵌入到可执行文件中。这有点像病毒的工作方式。我用它来检查NixOS的initrd并弄清楚它是如何构造的。与它结合使用dd可以轻松切割和切割和拼接二进制blob!
此时,我们可以继续从原始程序中调查堆,并且线程也是如此。但我现在停在这里。














 3543
3543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









