







安装pyenv
1、下载文件
- 前往github地址,下载压缩包
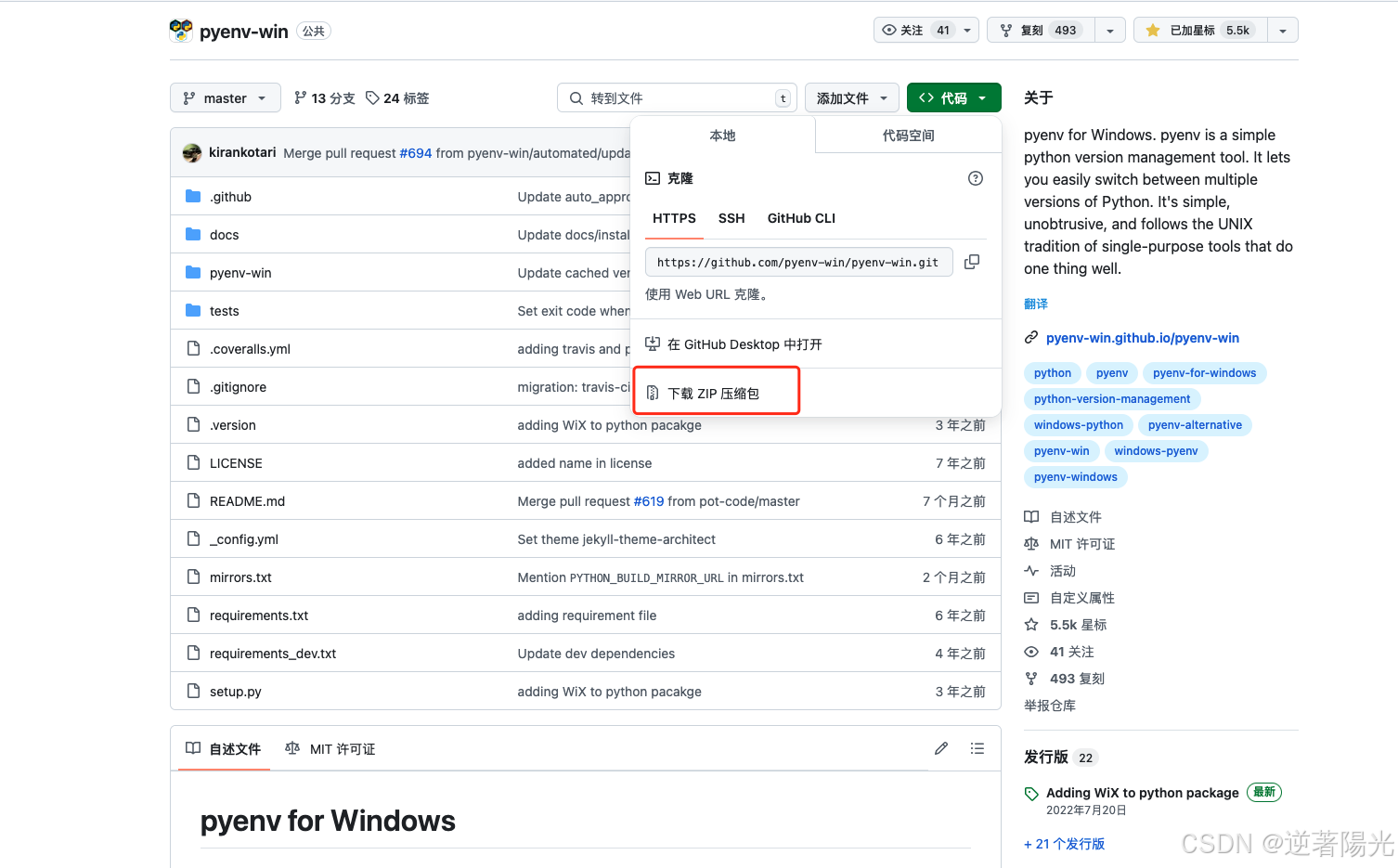
- 本地解压,文件夹重命名为.pyenv
2、环境配置
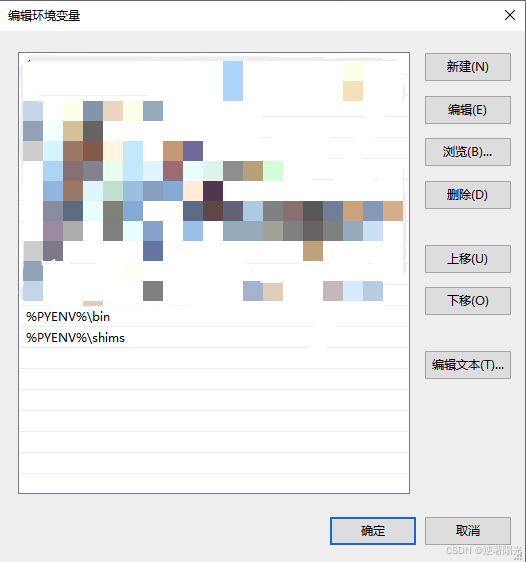
- 配置系统环境变量,新建PYENV系统环境,值为C:\.pyenv\pyenv-win

- 在系统变量PATH中添加%PYENV%\bin、%PYENV%\shims
3、测试
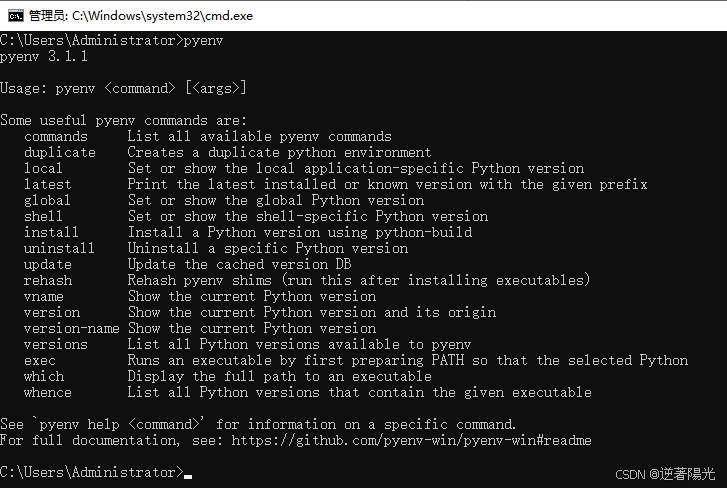
- cmd中测试,输入pyenv,显示如下则成功
安装cuda12.1
1、卸载cuda12.4
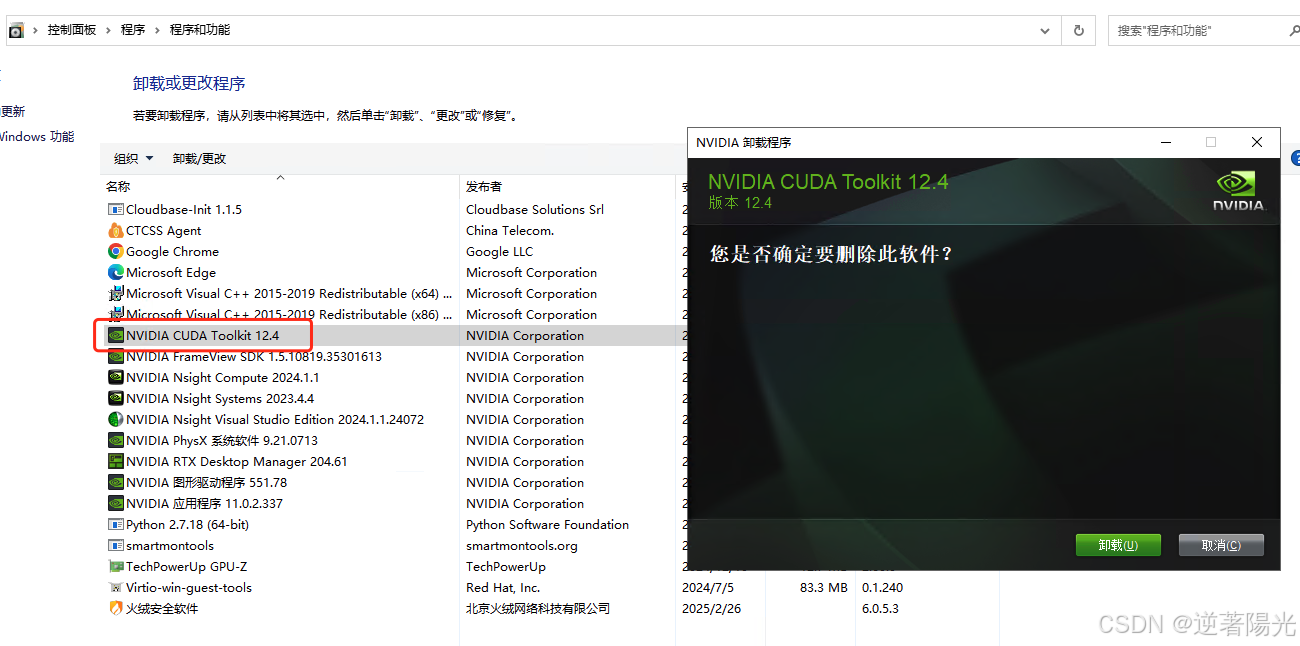
- 从控制面板-程序-程序和功能,卸载cuda12.4
- 检查环境变量中系统变量PATH是否还残存cuda的值,有则删除
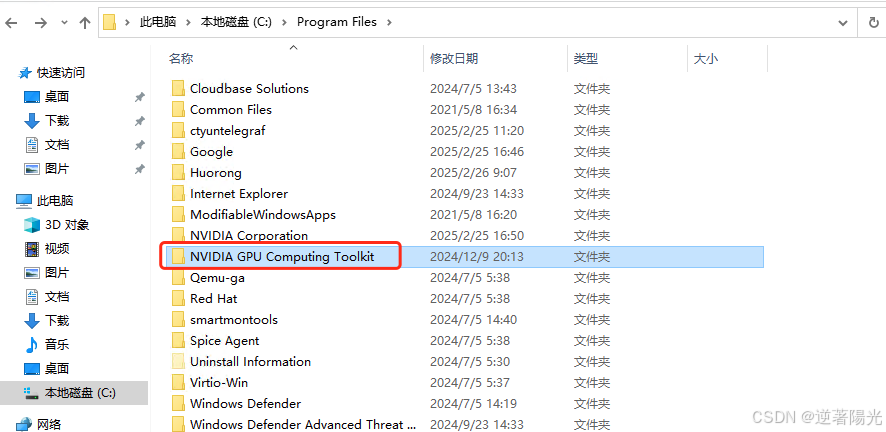
- 删除目录C:\Program Files\NVIDIA GPU Computing Toolkit
- 重启电脑
2、下载cuda12.1
- 按住键盘
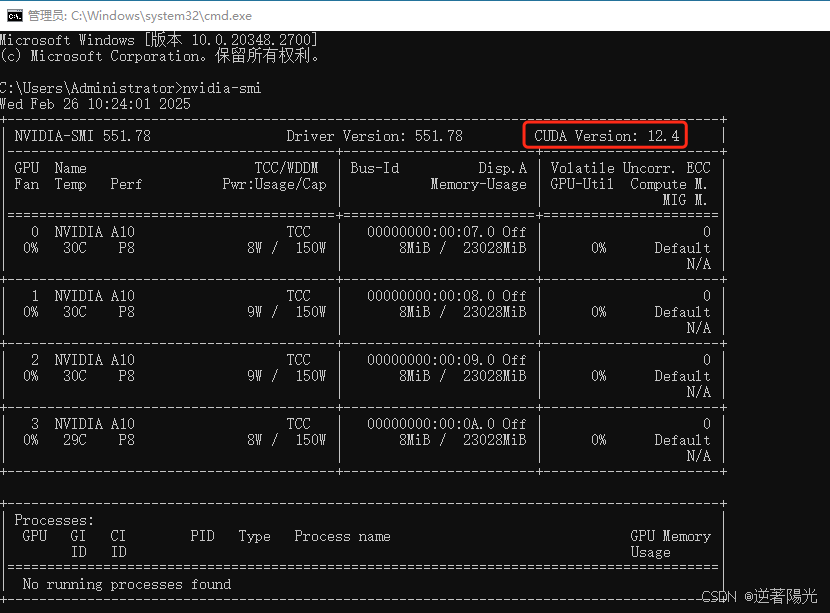
win+ R,进入cmd界面,输入nvidia-smi,可查看最高支持cuda版本
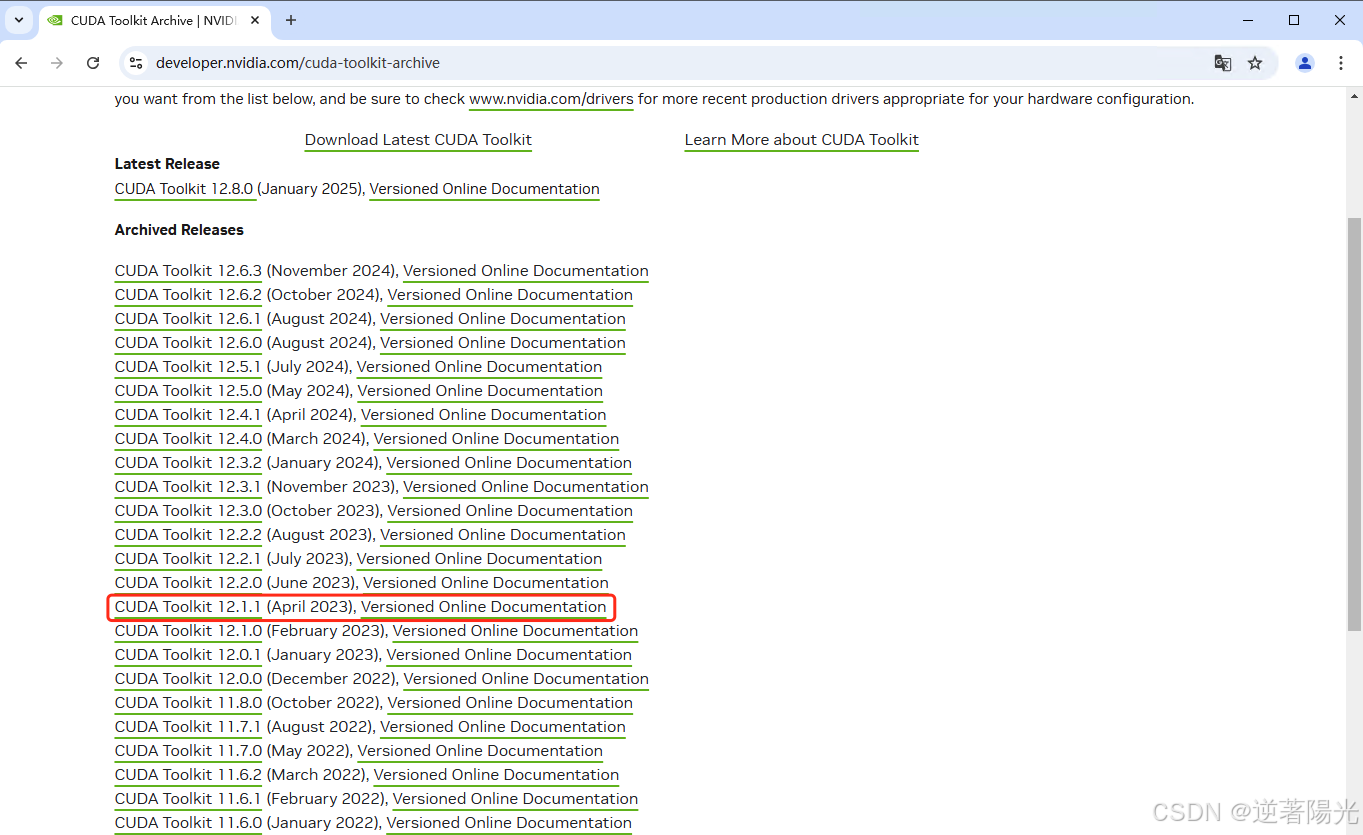
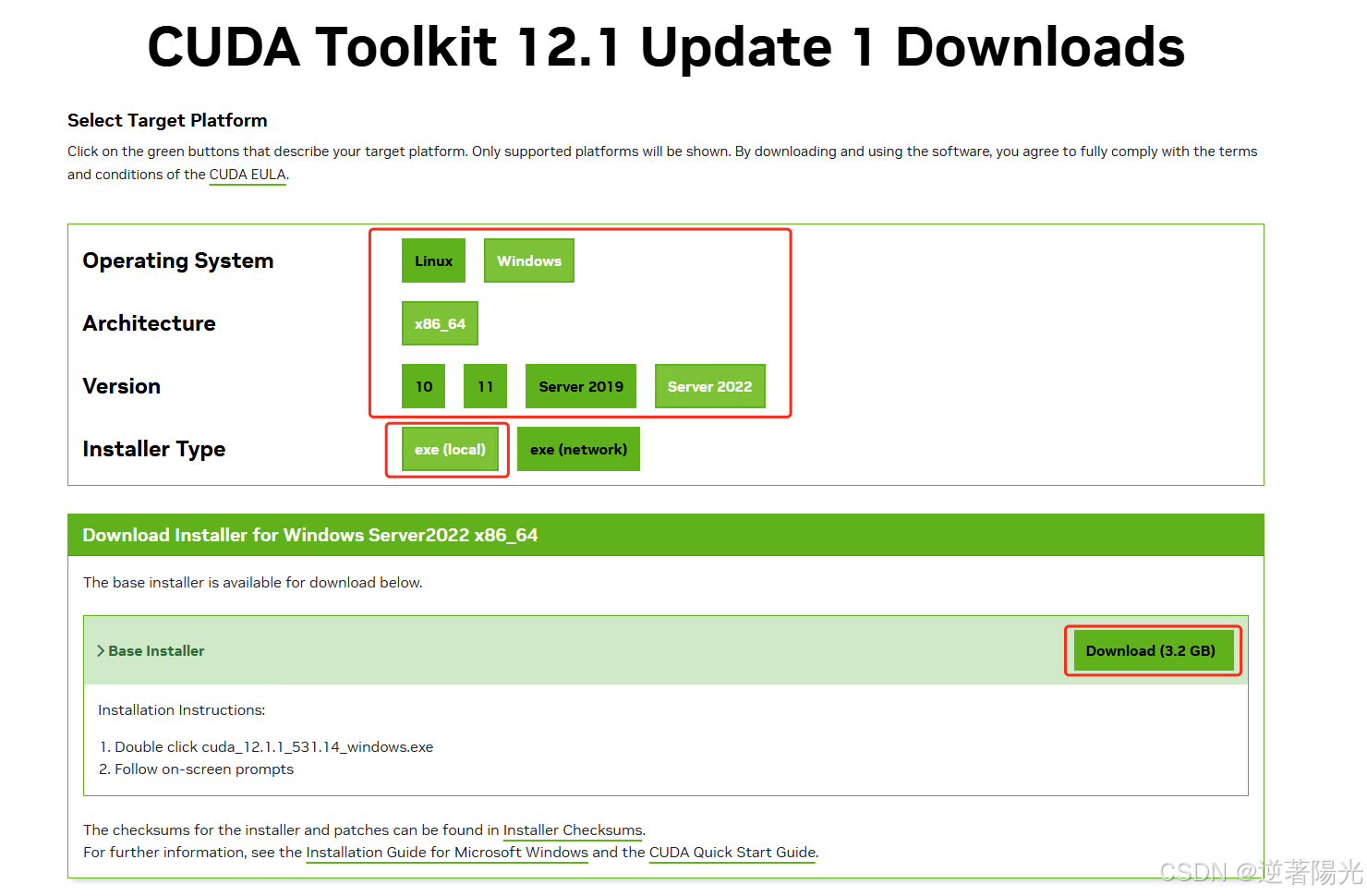
- 下载 CUDA Tooikit 12.1.1 版本,根据本机的实际情况选择,下载exe(local)
3、安装cuda12.1
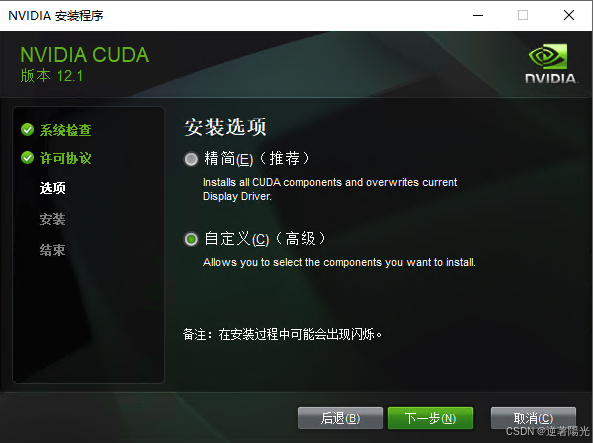
双击打开下载好的安装包,选择自定义安装
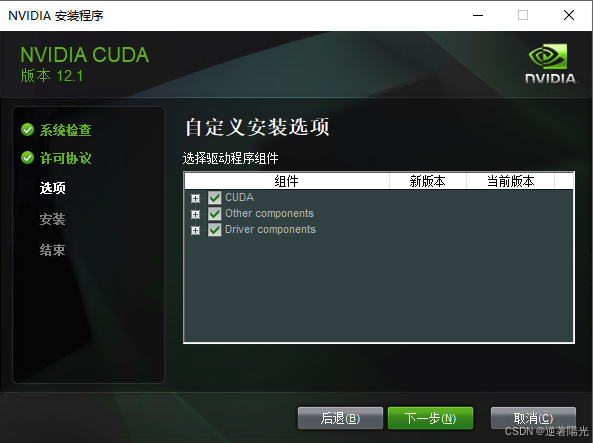
组件全选即可
勾选,即可安装
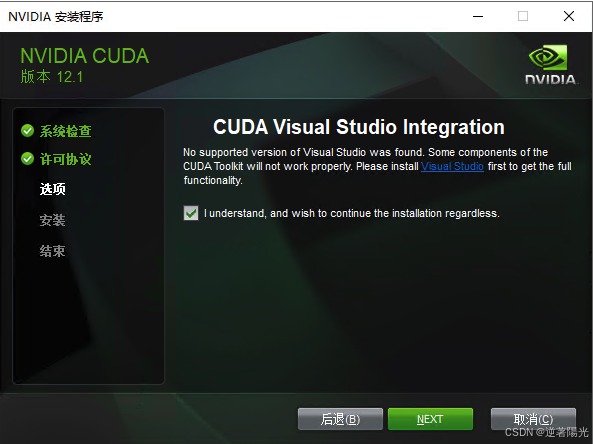
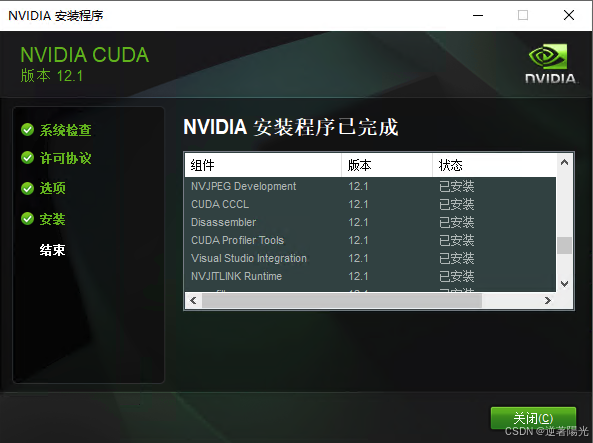
4、测试
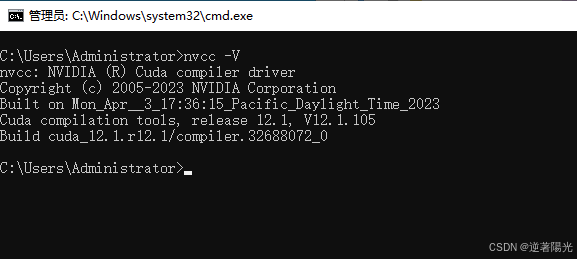
cmd界面,输入nvcc -V,可查看版本号
输入set cuda,可查看环境变量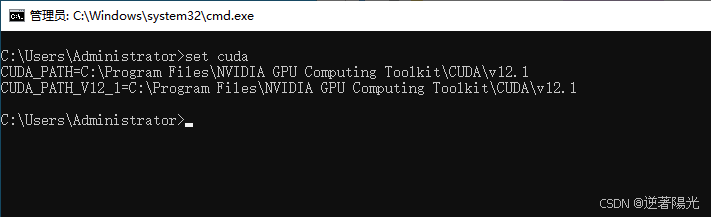
安装cuDNN
1、下载cuDNN
- 下载链接:cuDNN Archive | NVIDIA Developer
- 选择8.9.1版本
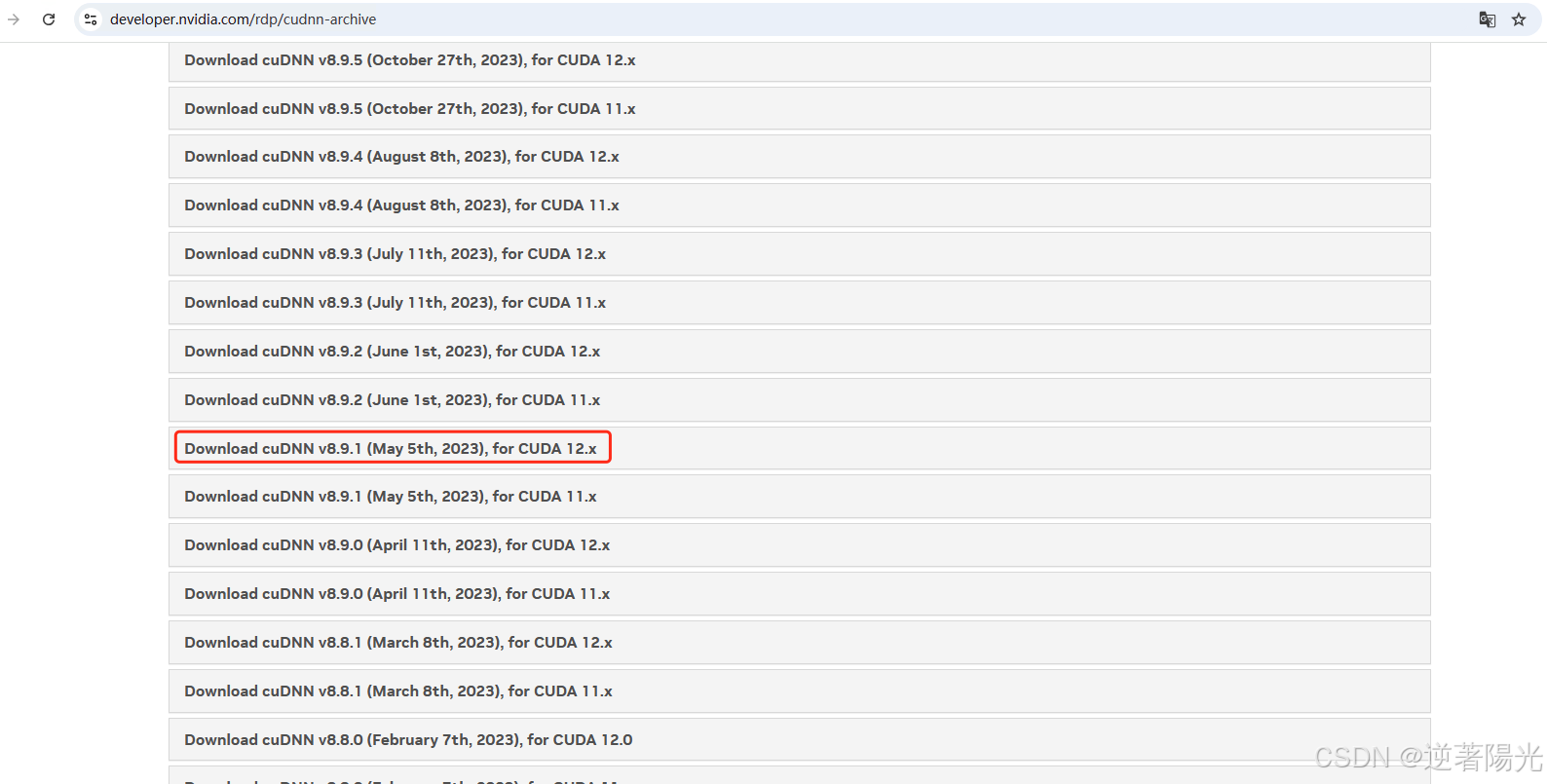
- 选择Zip文件下载
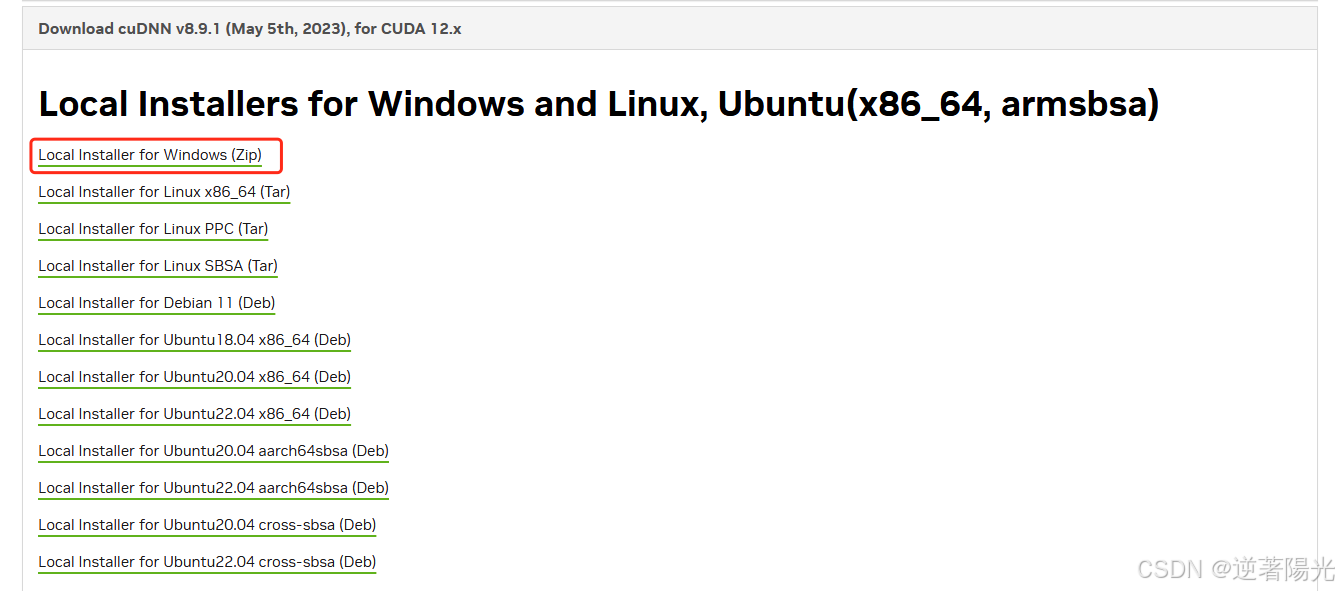
2、安装cuDNN
- 下载完成后进行解压
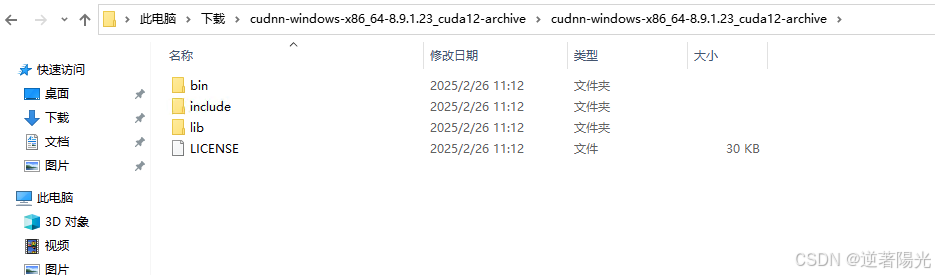
- 将bin、include、lib文件夹进行复制,粘贴到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\中,原先已存在bin、include、lib文件夹,不用管,直接粘贴
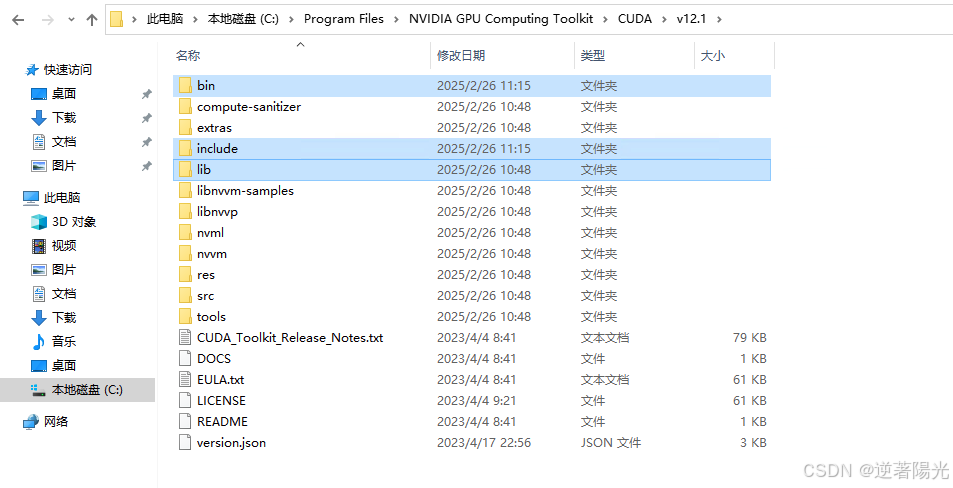
3、环境变量配置
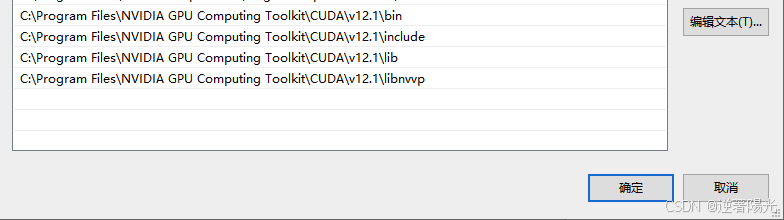
- 新增PATH环境变量
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\include
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\lib
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\libnvvp
4、测试
打开cmd,输入命令
cd C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\extras\demo_suitebandwidthTest.exe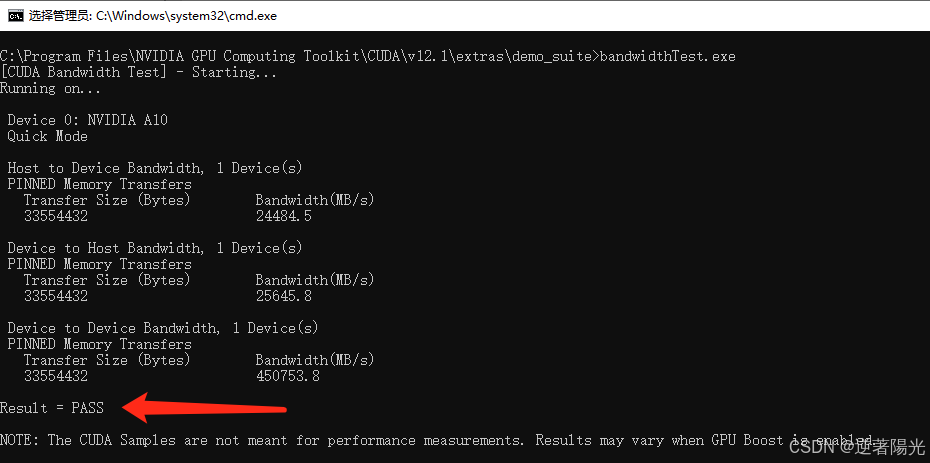
deviceQuery.exe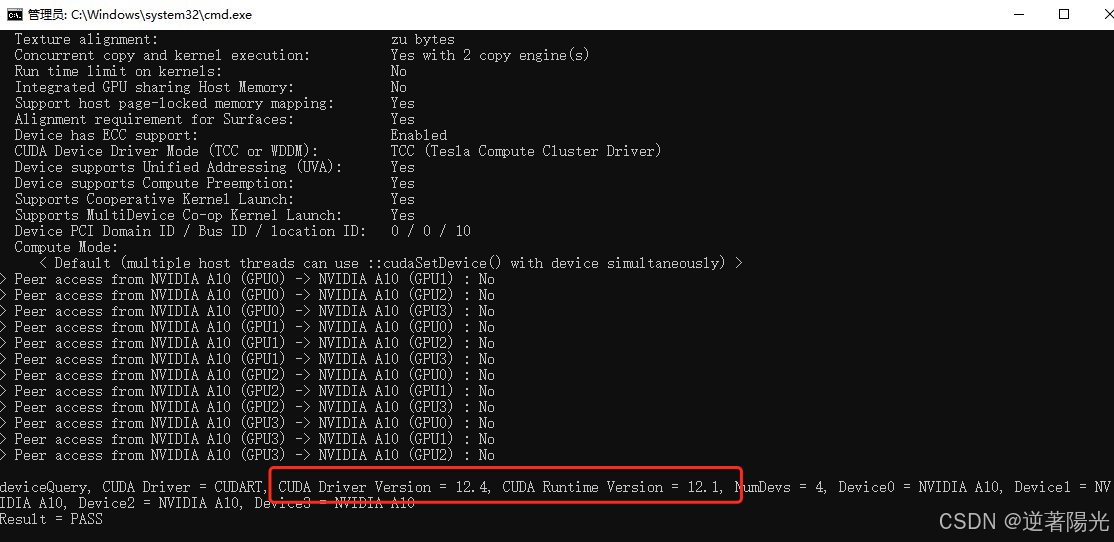
安装python 3.9.13
1、安装python
- 使用命令安装python 3.9.13
pyenv install 3.9.13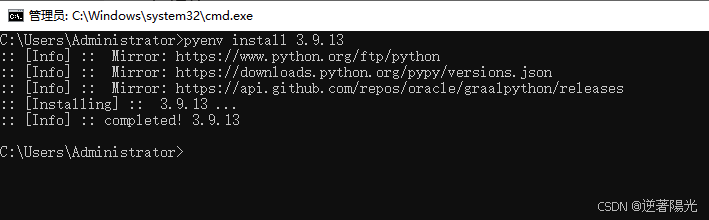
- 设置全局为python 3.9.13
pyenv global 3.9.13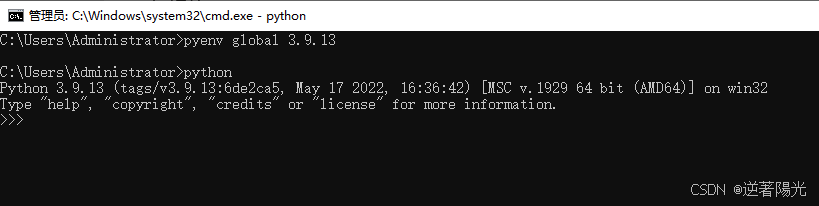
2、安装virtualenv
pip install virtualenv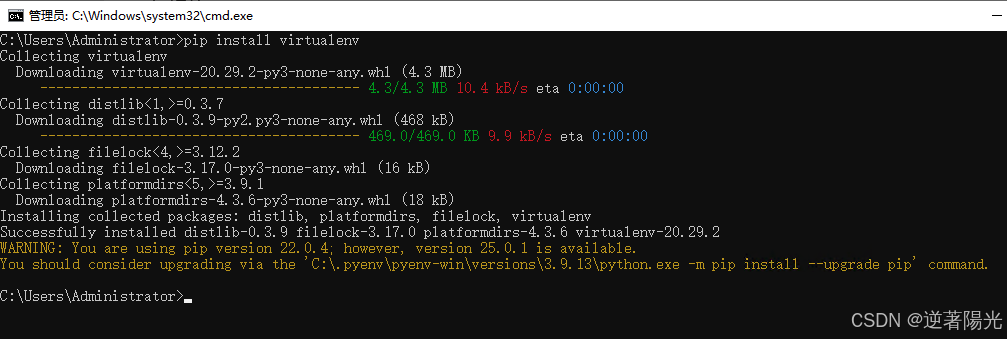
- 创建虚拟环境
python -m virtualenv C:\virtualenv\3.9.13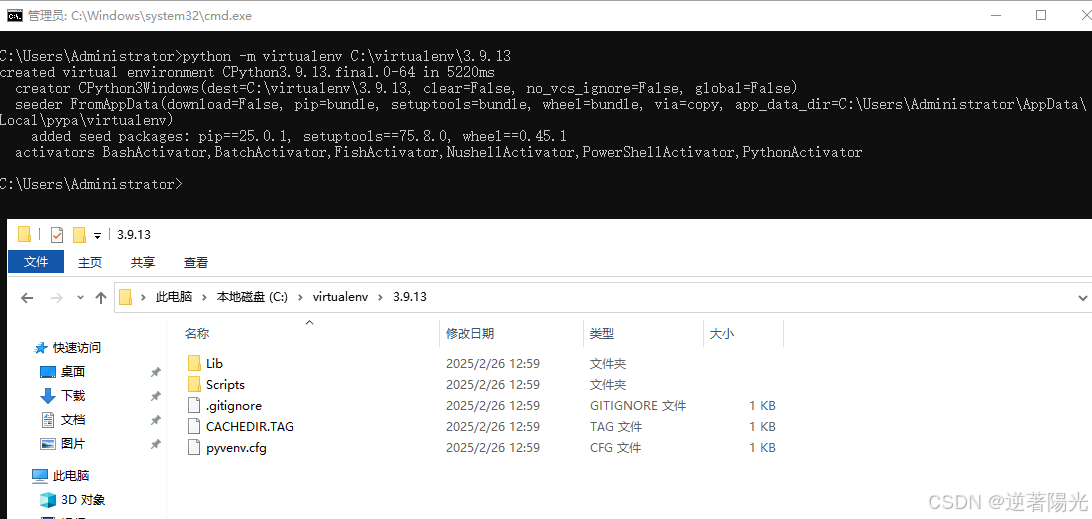
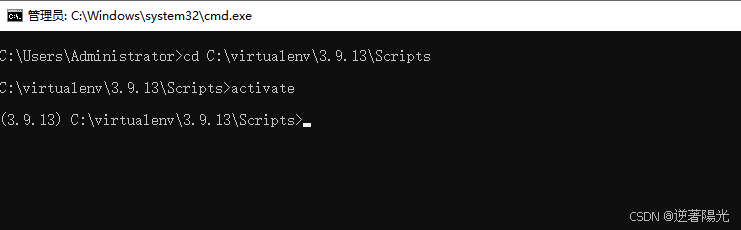
- 进入目录Scripts
cd C:\virtualenv\3.9.13\Scripts- 运行activate进入虚拟环境
安装pytorch 2.4.1
1、安装pytorch 2.4.1
- 进入pytorch官网:PyTorch
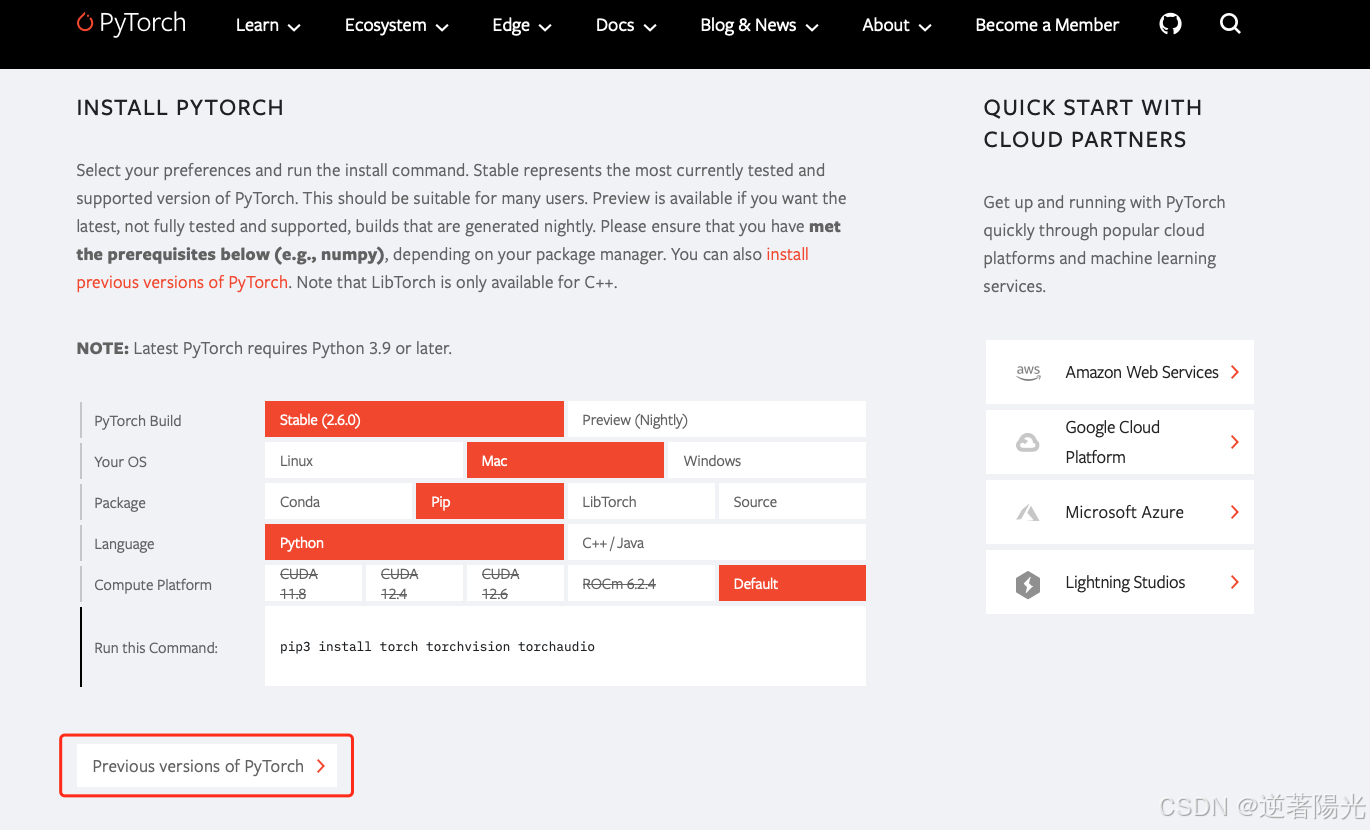
- 找到 v2.4.1 ,使用pip安装
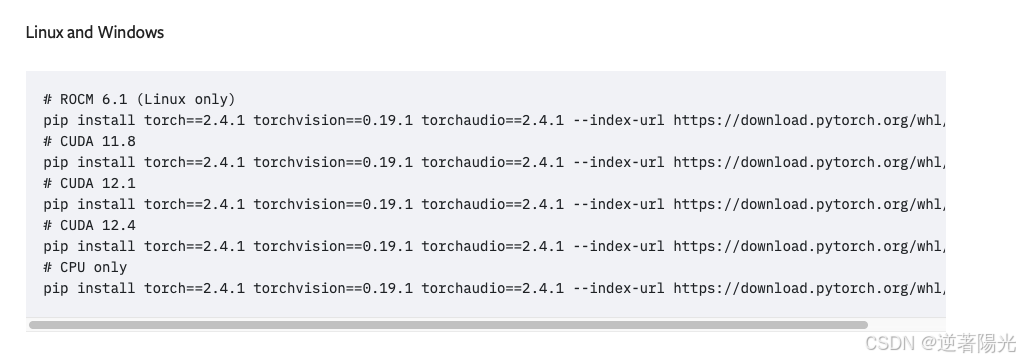
# ROCM 6.1 (Linux only)
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/rocm6.1
# CUDA 11.8
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu118
# CUDA 12.1
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121
# CUDA 12.4
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu124
# CPU only
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cpu- 根据cuda 12.1,选择命令安装
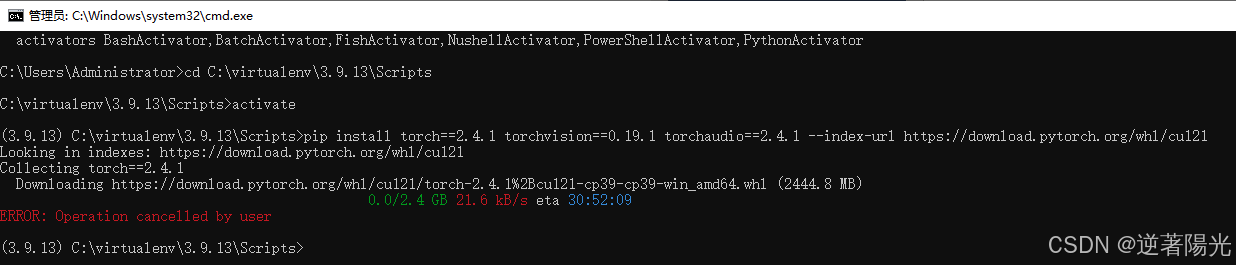
- pip速度太慢,直接访问网站下载:https://download.pytorch.org/whl/cu121
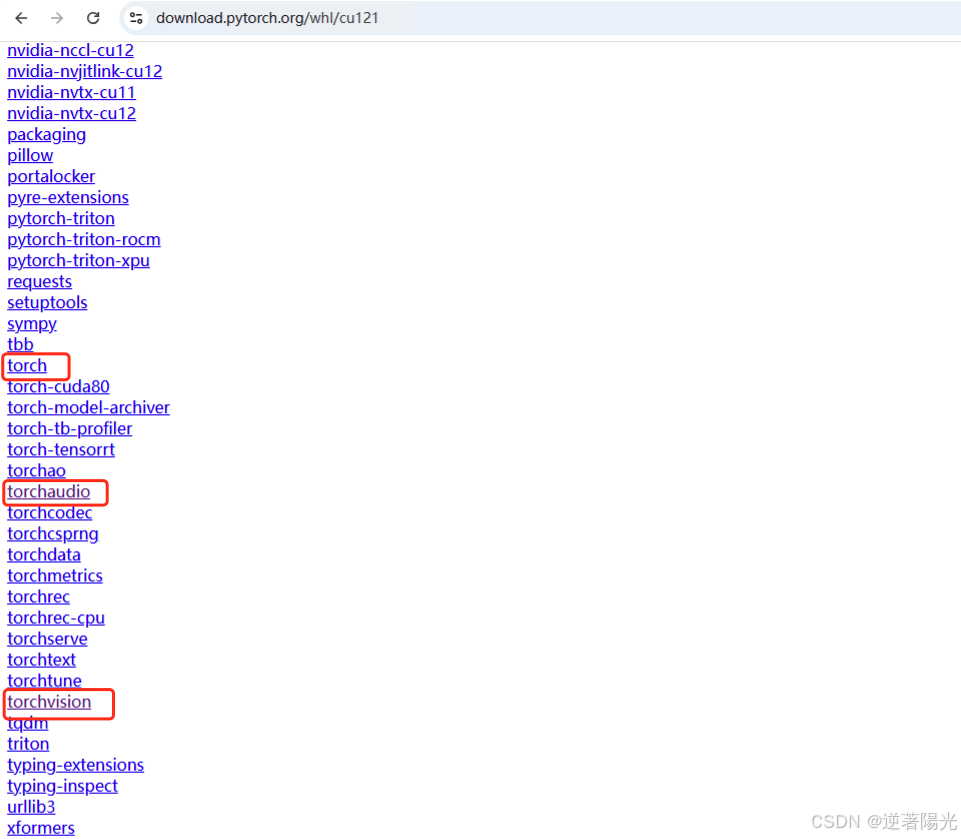
- 根据系统和python版本选择文件,windows + python 3.9.13,则
- torch:torch 版本为 2.4.1,cu 为 cuda 版本 12.1,cp 为 python版本 3.9,系统为win
torch-2.4.1+cu121-cp39-cp39-win_amd64.whl- torchvision:torchvision 版本为 0.19.1,cu 为 cuda 版本 12.1,cp 为 python版本 3.9,系统为win
torchvision-0.19.1+cu121-cp39-cp39-win_amd64.whl- torchaudio:torchaudio 版本为 2.4.1,cu 为 cuda 版本 12.1,cp 为 python版本 3.9,系统为win
torchaudio-2.4.1+cu121-cp39-cp39-win_amd64.whl
- 下载完成后再使用pip进行安装
cd C:\Users\Administrator\Downloads
pip install "torch-2.4.1+cu121-cp39-cp39-win_amd64.whl"
pip install "torchaudio-2.4.1+cu121-cp39-cp39-win_amd64.whl"
pip install "torchvision-0.19.1+cu121-cp39-cp39-win_amd64.whl"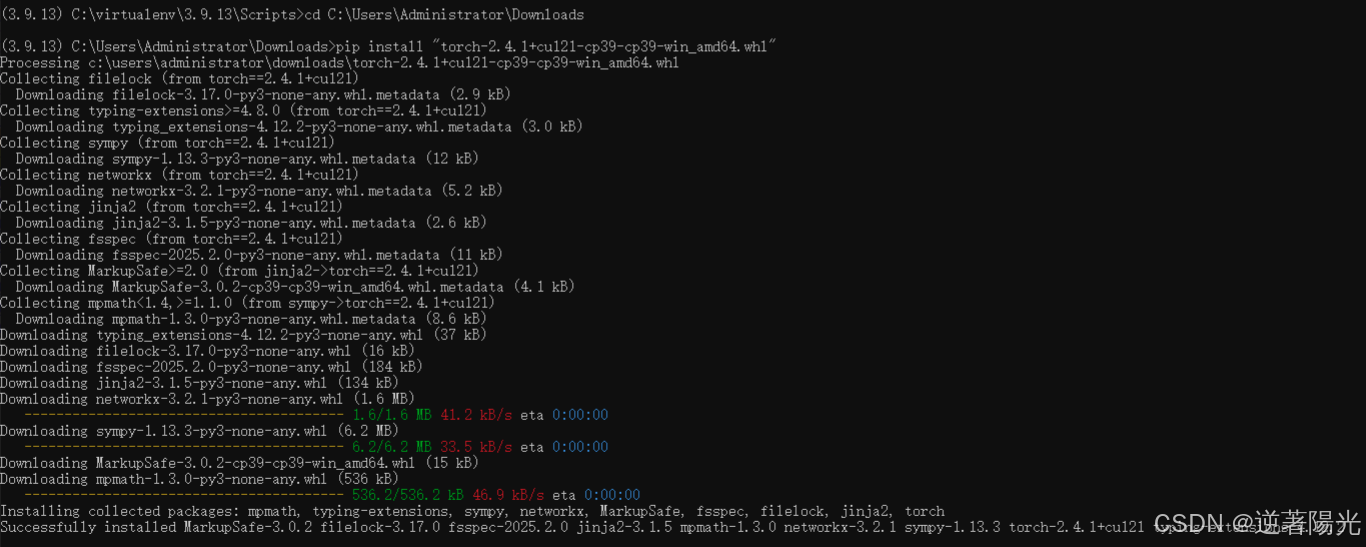

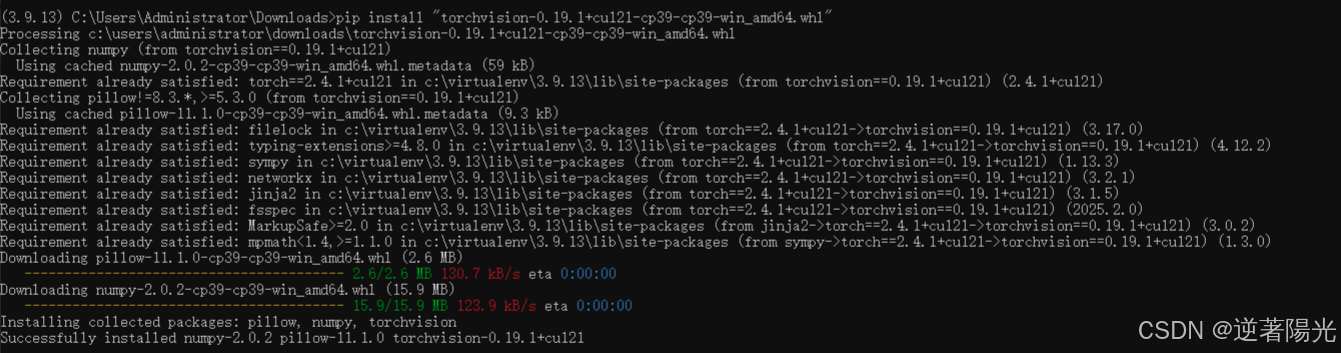
2、测试
- 使用python脚本进行测试
import torch
print(f"torch.version: {torch.__version__}")
print(f"torch.cuda: {torch.cuda.is_available()}")
print(f"cuda.version: {torch.version.cuda}")
安装flash-attn
1、安装
- 使用pip安装flash-attn
pip install flash_attn2、错误
错误1
出现如下错误:ERROR: Could not install packages due to an OSError: [Errno 2] No such file or directory: 'C:\\Users\\Administrator\\AppData\\Local\\Temp\\2\\pip-install-mo41p1_0\\flash-attn_dfa6bf1afef946118ff1145226cce6f5\\csrc/composable_kernel/client_example/24_grouped_conv_activation/grouped_convnd_fwd_scaleadd_scaleadd_relu/grouped_conv_fwd_scaleadd_scaleadd_relu_bf16.cpp'
HINT: This error might have occurred since this system does not have Windows Long Path support enabled. You can find information on how to enable this at https://pip.pypa.io/warnings/enable-long-paths

- 这个是由于 Windows 文件路径长度限制引起的。Windows 默认的文件路径长度限制是 260 个字符,当路径超过这个长度时,就会出现这样的错误。
解决办法
启用 Windows 长路径支持:
- Windows 10 及以上版本支持长路径,但需要手动启用。
- 启用步骤如下:
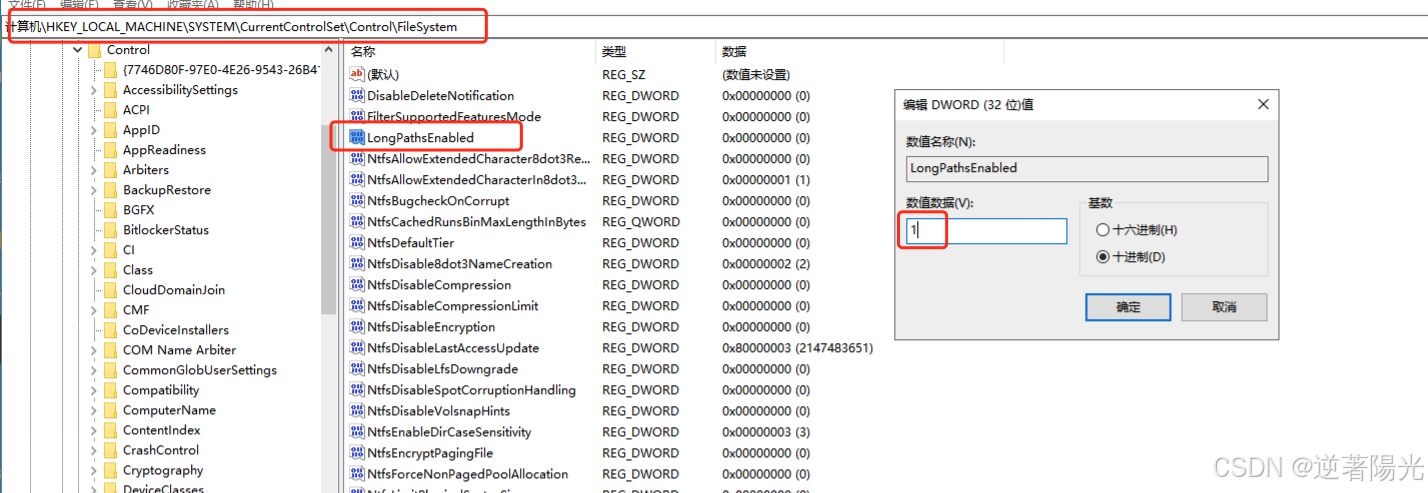
- 打开 注册表编辑器(按
Win + R,输入regedit,回车)。 - 导航到
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\FileSystem。 - 找到
LongPathsEnabled项(如果没有,右键新建一个DWORD值,命名为LongPathsEnabled)。 - 将
LongPathsEnabled的值设置为1。 - 重启电脑。
错误2
- 重启之后可以正常运行pip命令,但是出现了新的错误
ERROR: Could not find a version that satisfies the requirement psutil (from versions: none)
ERROR: No matching distribution found for psutil
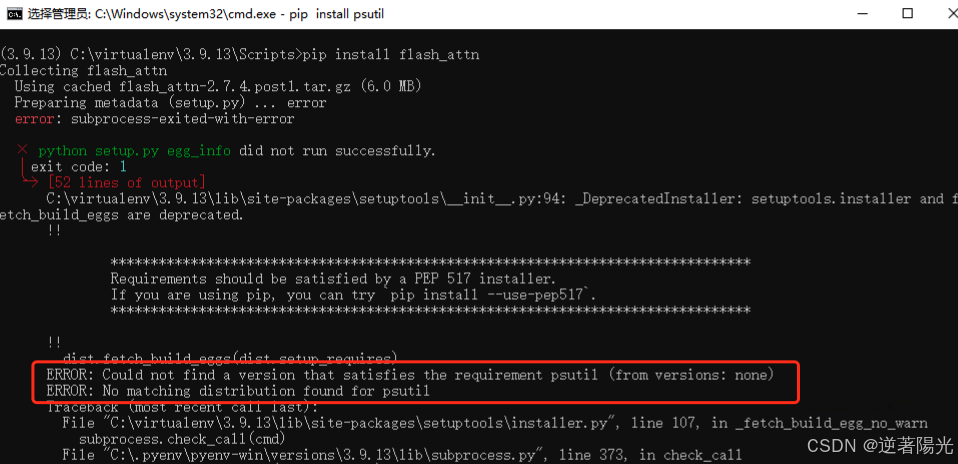
解决办法
pip install psutil
错误3
C:\virtualenv\3.9.13\lib\site-packages\torch\utils\cpp_extension.py:380: UserWarning: Error checking compiler version for cl: [WinError 2] 系统找不到指定的文件。
warnings.warn(f'Error checking compiler version for {compiler}: {error}')
building 'flash_attn_2_cuda' extension
error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for flash_attn
Running setup.py clean for flash_attn
Failed to build flash_attn
ERROR: Failed to build installable wheels for some pyproject.toml based projects (flash_attn)
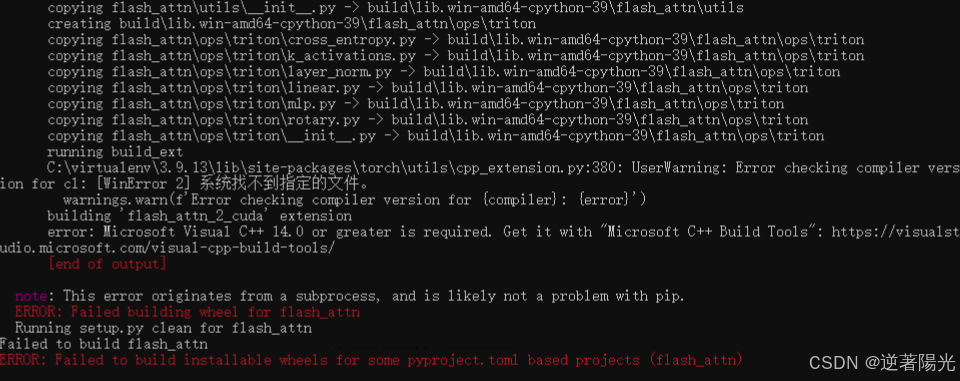
- 这个是由于缺少 Microsoft Visual C++ 14.0 或更高版本,
flash_attn是一个需要编译的 Python 包,而编译过程依赖于 Visual C++ 构建工具。
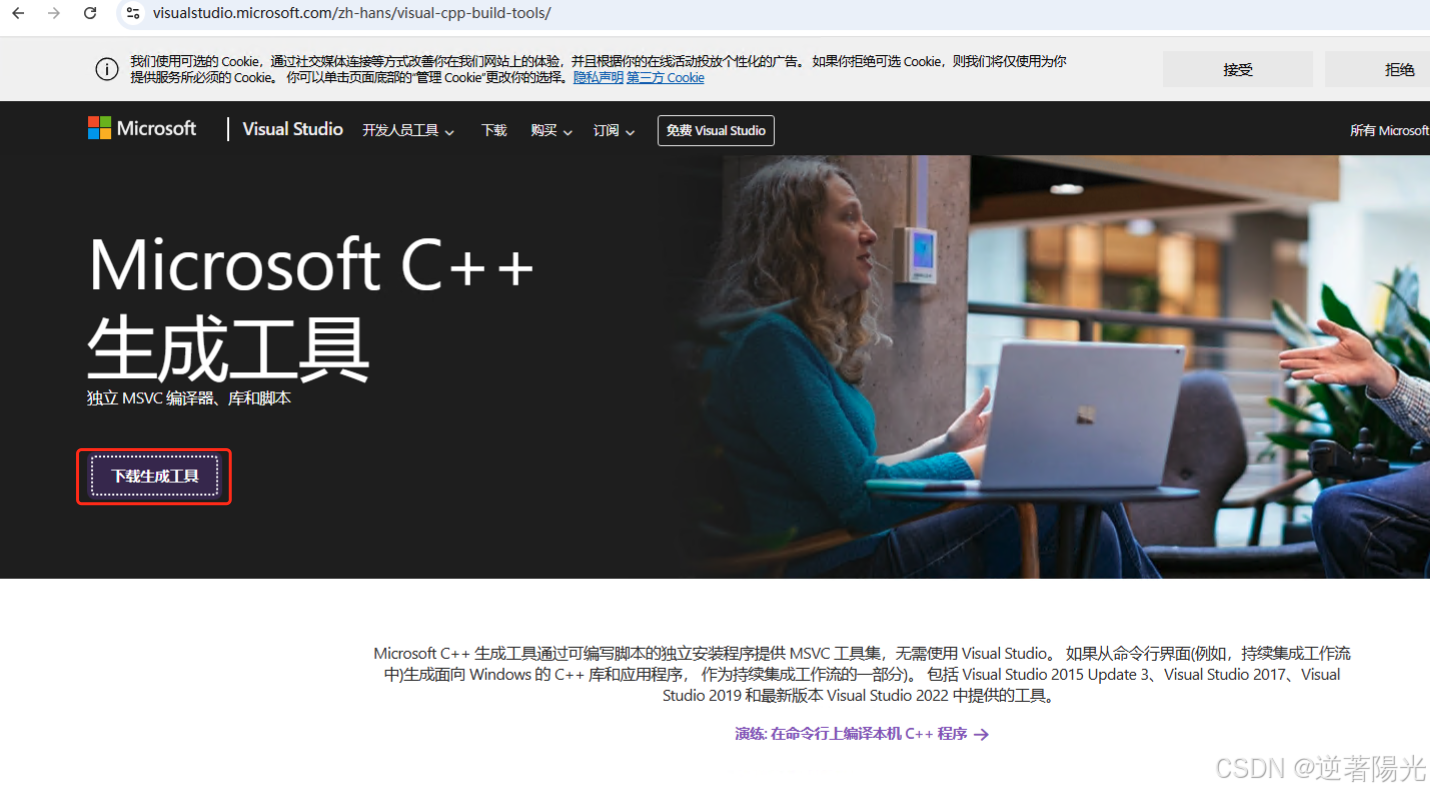
解决办法
- 安装 Microsoft C++ 构建工具
- 下载地址:Microsoft C++ 生成工具 - Visual Studio
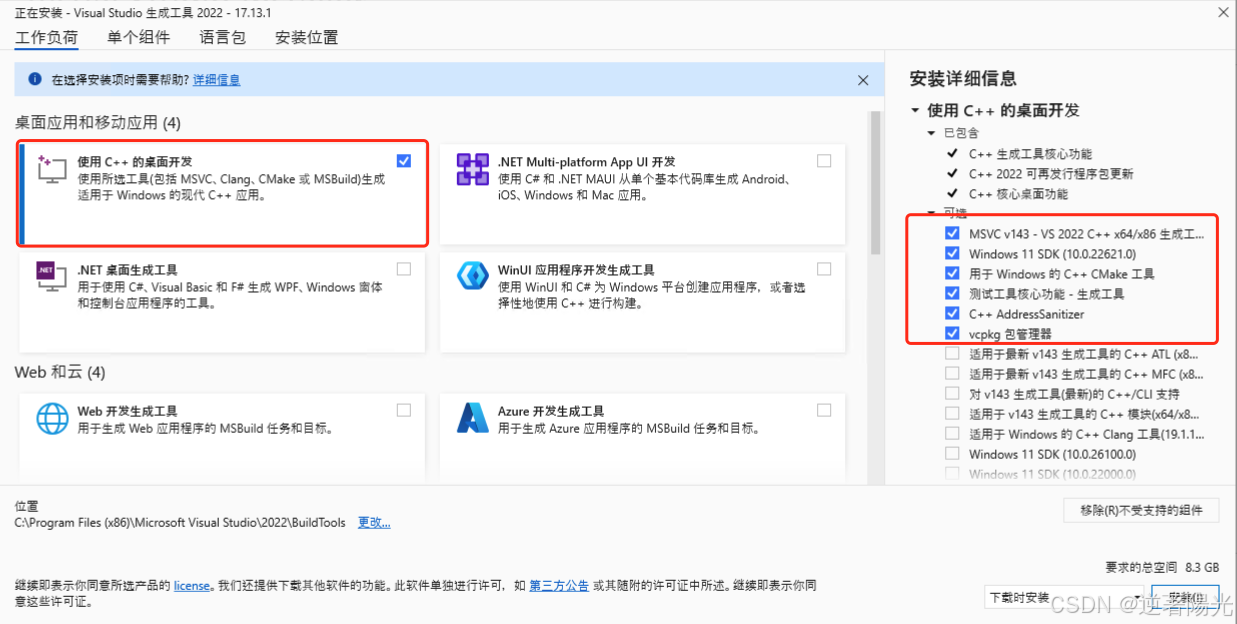
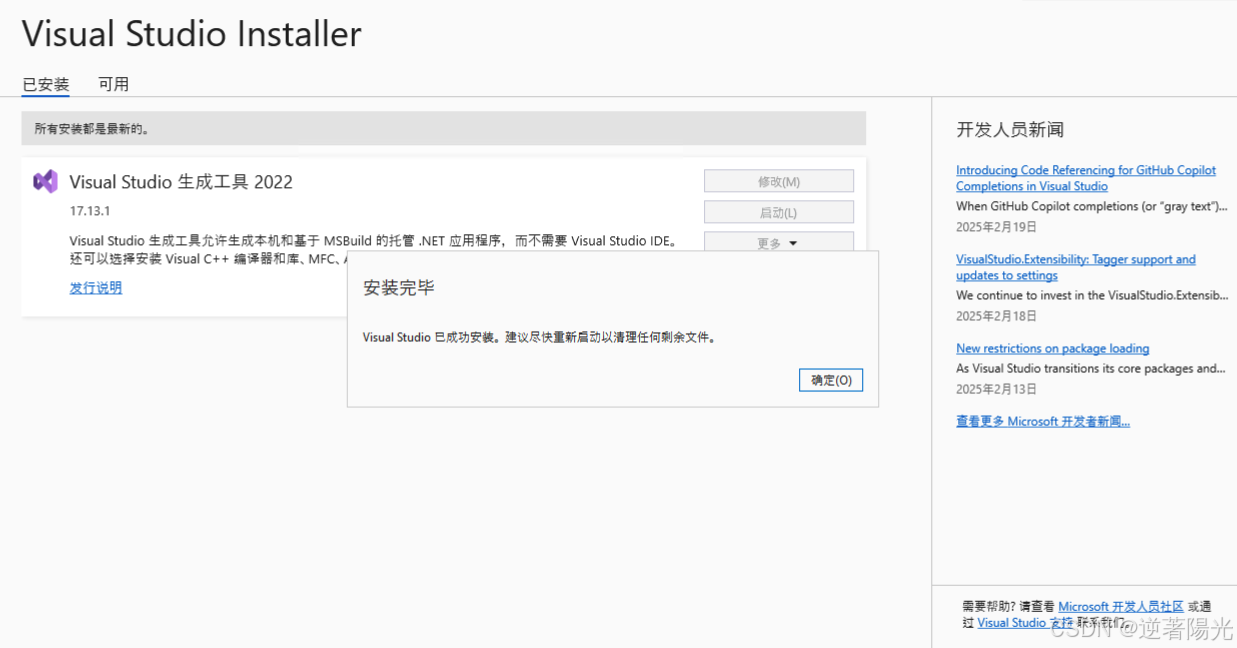
- 突破vs2022与cuda版本限制
修改文件C:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools\VC\Tools\MSVC\14.43.34808\include\yvals_core.h
第920行,将
#if __CUDACC_VER_MAJOR__ < 12 || (__CUDACC_VER_MAJOR__ == 12 && __CUDACC_VER_MINOR__ < 4)修改为
#if __CUDACC_VER_MAJOR__ < 10 || (__CUDACC_VER_MAJOR__ == 10 && __CUDACC_VER_MINOR__ < 1)错误4
RuntimeError: Error compiling objects for extension
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for flash-attn
Running setup.py clean for flash-attn
Failed to build flash-attn
ERROR: Failed to build installable wheels for some pyproject.toml based projects (flash-attn)

- 可能是由于网络问题,无法下载包
解决办法
从github下载whl包
下载地址:https://github.com/Dao-AILab/flash-attention
选择cuda 12.1 、python 3.9、win系统的whl包进行下载,即“flash_attn-2.3.0+cu121-cp39-cp39-win_amd64.whl”
现在github已经下载不到windows版本的包了,建议更换为flash_attn-2.7.4.post1-cp39-cp39-win_amd64.whl,测试也是没有问题的。
https://download.csdn.net/download/u011364318/90734842
下载完成后使用
pip install flash_attn-2.7.4.post1-cp39-cp39-win_amd64.whl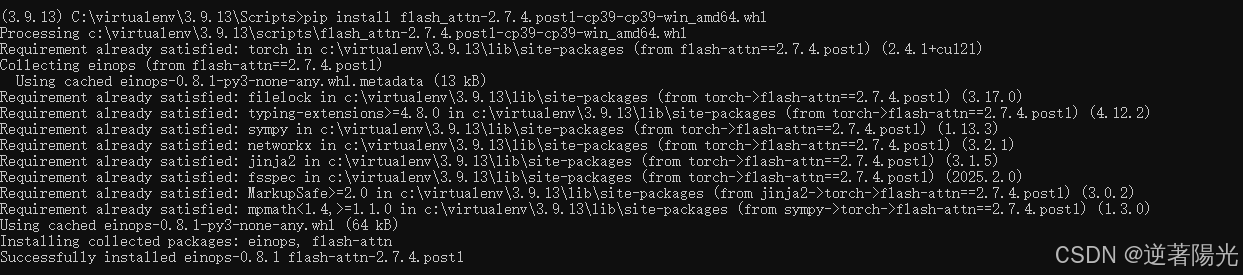
3、测试
- 单显卡测试代码
import torch
from flash_attn import flash_attn_func
import time
def test_flash_attention():
# 设置随机种子以确保结果可重现
torch.manual_seed(0)
# 生成随机测试数据
batch_size = 2
seq_len = 1024
num_heads = 8
head_dim = 64
# 创建随机查询、键和值张量
q = torch.randn(batch_size, seq_len, num_heads, head_dim, device='cuda', dtype=torch.float16)
k = torch.randn(batch_size, seq_len, num_heads, head_dim, device='cuda', dtype=torch.float16)
v = torch.randn(batch_size, seq_len, num_heads, head_dim, device='cuda', dtype=torch.float16)
try:
# 测试 Flash Attention
start_time = time.time()
output = flash_attn_func(q, k, v, causal=True)
flash_time = time.time() - start_time
print("Flash Attention 测试成功!")
print(f"输出张量形状: {output.shape}")
print(f"运行时间: {flash_time:.4f} 秒")
print("\n张量设备位置:", output.device)
print("张量数据类型:", output.dtype)
return True
except Exception as e:
print("Flash Attention 测试失败")
print("错误信息:", str(e))
return False
if __name__ == "__main__":
if torch.cuda.is_available():
print("CUDA 可用")
print("GPU:", torch.cuda.get_device_name(0))
test_flash_attention()
else:
print("错误: 需要 CUDA 支持才能运行 Flash Attention")
- 多显卡测试代码
import torch
from flash_attn import flash_attn_func
import time
def test_flash_attention_multi_gpu():
batch_size = 2
seq_len = 1024
num_heads = 8
head_dim = 64
num_gpus = torch.cuda.device_count()
if num_gpus < 2:
print("GPU 数量不足,直接在单 GPU 上运行")
device = 'cuda:0'
else:
print(f"检测到 {num_gpus} 张 GPU,手动分配计算")
# 将数据分配到多个 GPU
q_list, k_list, v_list = [], [], []
for i in range(num_gpus):
device = f'cuda:{i}'
q_list.append(torch.randn(batch_size, seq_len, num_heads, head_dim, device=device, dtype=torch.float16))
k_list.append(torch.randn(batch_size, seq_len, num_heads, head_dim, device=device, dtype=torch.float16))
v_list.append(torch.randn(batch_size, seq_len, num_heads, head_dim, device=device, dtype=torch.float16))
outputs = []
start_time = time.time()
for i in range(num_gpus):
q, k, v = q_list[i], k_list[i], v_list[i]
with torch.cuda.device(f'cuda:{i}'):
output = flash_attn_func(q, k, v, causal=True)
outputs.append(output.cpu()) # 先取到 CPU 以便合并
flash_time = time.time() - start_time
print("Flash Attention 多 GPU 测试成功!")
print(f"每个 GPU 计算的输出形状: {outputs[0].shape}")
print(f"总运行时间: {flash_time:.4f} 秒")
if __name__ == "__main__":
test_flash_attention_multi_gpu()


















 1330
1330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









