







最近开始了python爬虫的学习,这里带来利用python实现网易163邮箱个人收件箱列表信息的爬取的小项目,刚开始学习,写的不好的地方,望大神指正,诚恳学习。
主要内容
- 模拟163邮箱登录
- 获取登录后的收件箱页面
- 分析页面得到所有邮件的列表的信息
主要思路
经过对163邮箱的登陆过程的分析,其登陆过程需要:
- 手动登录获得登录过程的信息
- 分析登陆过程所需的参数
- 向登录界面发送登录请求,POST 一系列参数,获得响应,及登录的cookie
- 提取登录所需要的sid码
- 利用sid码和cookie重新请求,获得响应,重定向网页,获取页面信息
- 利用正则表达式提取相关信息
接下来为大家介绍详细的过程。
前期准备
首先我们打开网易邮箱的登录界面http://mail.163.com/,我用的是Firefox浏览器,右键查看元素或者f12打开设置里的启用持续日志这样我们就可以在登录后查看登陆过程提交的请求等参数,否则页面跳转就抓取不到这个信息。
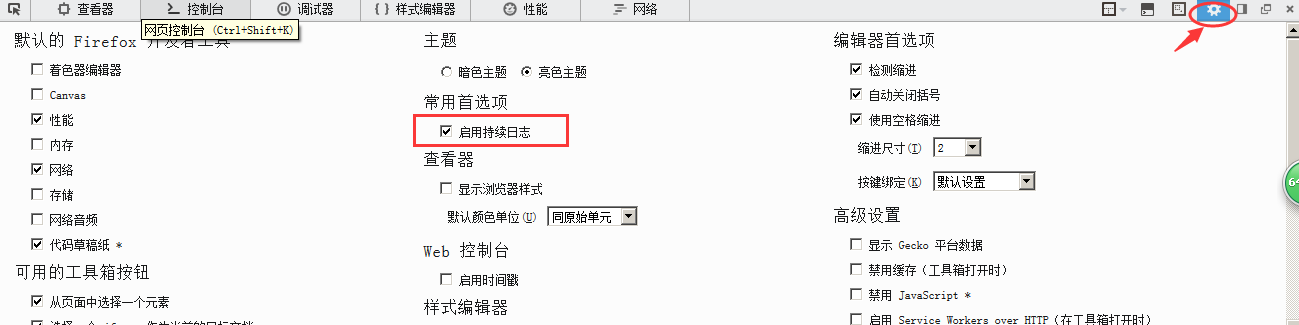
然后选择网络选项,这是时空的,然后输入账号密码登录,登陆后会发现网络选项中出现下图所示
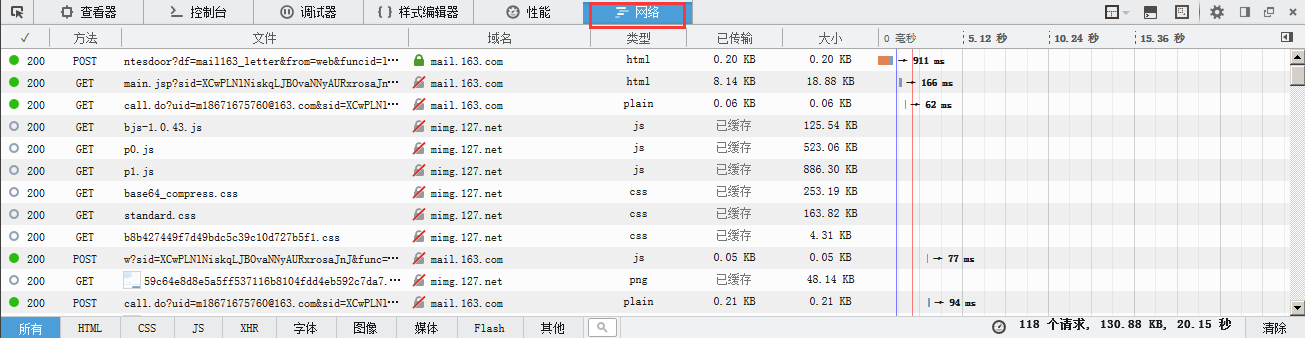
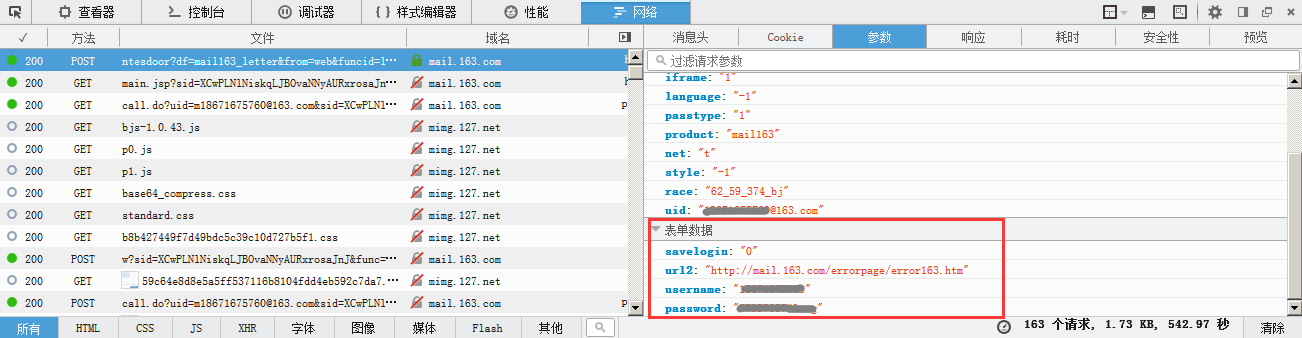
拉到最上边我们会发现一条post的日志,这就是登录时提交的参数信息。点击进入这条日志,就会显示消息头,请求网址,参数等。点击参数选项会看到一个表单数据,这个里边就记录了你提交的 用户名,密码,以及产生错误跳转的url。
这时细心的你可以看到地址栏的URL已经变了,而且在URL中有一串名为sid的参数
mail.163.com/js6/main.jsp?sid=XCwPLNlNiskqLJBOvaNNyAURxrosaJnJ&df=mail163_lette
这个sid码就是我们登录的关键,下面我来说明怎么得到这个sid码。
获取sid码
刚才我们选中了那个post日志,选择消息头,我们可以看到这次日志请求网址
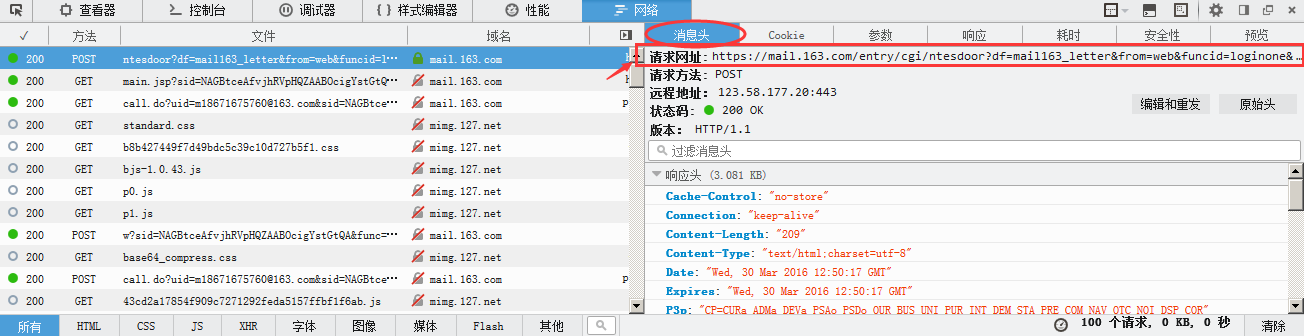
这里请求的网址和我们目前所在的网址并不一样,这说明我们登陆时经过了这么一个中转的网址,想看到这个网址下是什么,很简单,点开上面的响应选项你就可以看到这个网址下是什么内容。
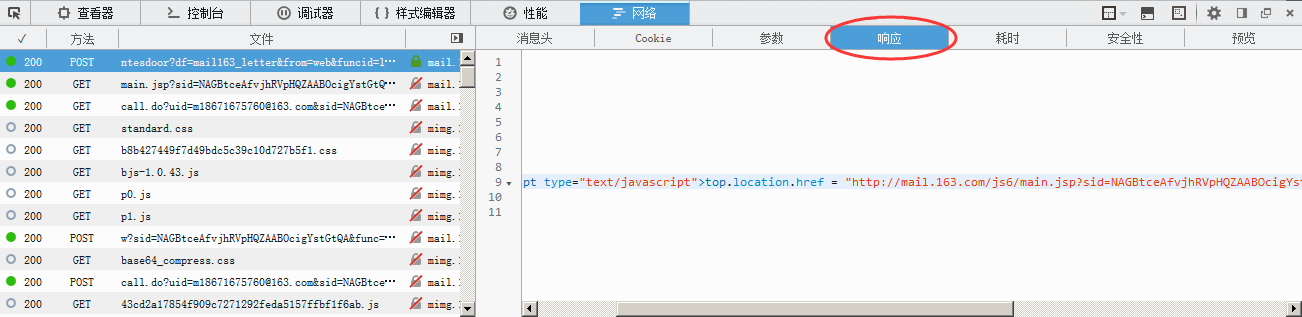
通过这个响应我们可以发现,我们提交的参数中并没有这个sid码,但是在响应中出现了这个sid码,因此这个sid码使我们登陆所需要的。但是这个sid码只在本次登录有效,并不能一劳永逸,所以我们每次登录都需要通过这个中转界面来获取这个sid码。这是我们就需要来获取这个页面的源码并提取这个sid码。下面附上我的代码。
# -*- coding:utf-8 -*-
import urllib
import urllib2
import re
import cookielib
#163邮箱类
class MAIL:
#初始化
def __init__(self):
#获取登录请求的网址,也就是上边提到的请求网址
self.loginUrl = "https://mail.163.com/entry/cgi/ntesdoor?df=mail163_letter&from=web&funcid=loginone&iframe=1&language=-1&passtype=1&product=mail163&net=t&style=-1&race=-2_42_-2_hz"
#设置代理,以防止本地IP被封
self.proxyUrl = "http://202.106.16.36:3128"
#初始化sid码
self.sid = ""
#第一次登陆所需要的请求头request headers,这个在消息头里的请求头有
self.loginHeaders = {
'Host':"mail.163.com",
'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0",
'Accept':"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
'Accept-Language':"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
'Accept-Encoding':"gzip, deflate, br",
'Referer':"http://mail.163.com/",
'Connection':"keep-alive",
}
#设置用户名和密码,输入自己的账号密码
self.username = '*******'
self.pwd = '*******'
#post所包含的参数也就是参数里的表单数据
self.post = {
'savelogin':"0",
'url2':"http://mail.163.com/errorpage/error163.htm",
'username':self.username,
'password':self.pwd
}
#对post编码转换
self.postData = urllib.urlencode(self.post)
#设置代理
self.proxy = urllib2.ProxyHandler({'http':self.proxyUrl})
#设置cookie对象,会在登录后获取登录网页的cookie
self.cookie = cookielib.LWPCookieJar()
#设置cookie处理器
self.cookieHandler = urllib2.HTTPCookieProcessor(self.cookie)
#设置登录时用到的opener,相当于我们直接打开网页用的urlopen
self.opener = urllib2.build_opener(self.cookieHandler,self.proxy,urllib2.HTTPHandler)
#模拟登陆并获取sid码
def loginPage(self):
#发出一个请求
request = urllib2.Request(self.loginUrl,self.postData,self.loginHeaders)
#得到响应
response = self.opener.open(request)
#需要将响应中的内容用read读取出来获得网页代码,网页编码为utf-8
content = response.read().decode('utf-8')
#打印获得的网页代码
print content
#生成邮箱爬虫对象
mail = MAIL()
#调用loginPage方法来获取网页内容
mail.loginPage()
登陆成功的话可以看到输出的结果为
<html><head><script type="text/javascript">top.location.href = "http://mail.163.com/js6/main.jsp?sid=DCTmVAgAnZBmwWWqcjAAXXreaiJVaZYk&df=mail163_letter";</script></head><body></body></html>这里做一点说明:
- 上面需要填入自己的账号密码,代理设置中很多代理不能用,这个亲测可用
这样我们就得到了中转界面的页面代码,里边就有我们需要的sid码。如何提取这个sid码呢?我们就需要用正则表达式来匹配他。相应的提取代码如下,把其加入到loginPage中即可
#构建抓取sid码的正则表达式
sidpattern = re.compile('sid=(.*?)&',re.S)
#获取并储存sid码,打印出来
result = re.search(sidpattern,content)
self.sid = result.group(1)
print self.sidPS:正则表达式中 .*? 是一个很好用的组合,re.S是点任意匹配模式。
这样我们就成功抓取到了sid码,并且得到了登录时所需要的cookie。下一步要用抓取到的sid码来登录邮箱
登录邮箱
获取到了sid码之后我们就能登录邮箱了。
进入收件箱,点开响应选项,找到所有的post的日志,我们会发现有一个日志中的响应会是我们的邮件信息,这个就是我们需要的登陆的参数和信息:
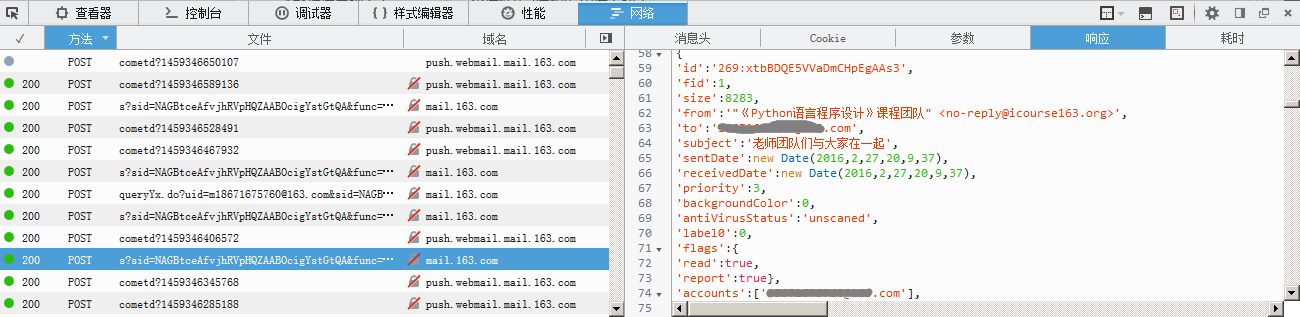
点开消息头这个请求的网址就是我们收件箱的地址,并且这个请求网址中有我们刚提取出来的sid码,所以我们只需要重定向到这个网址就能获得我们收件箱的页面信息了。这里我们只需要重置请求头,利用上边已获得的cookie和sid码重新请求就行了,下面附上代码:
#通过sid码获得邮箱收件箱信息
def messageList(self):
#重定向的网址,用获取到的sid码替换
listUrl = 'http://mail.163.com/js6/s?sid=%s&func=mbox:listMessages&TopTabReaderShow=1&TopTabLofterShow=1&welcome_welcomemodule_mailrecom_click=1&LeftNavfolder1Click=1&mbox_folder_enter=1'%self.sid
#新的请求头
Headers = {
'Host':"mail.163.com",
'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0",
'Accept':"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
'Accept-Language':"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
'Accept-Encoding':"gzip, deflate, br",
'Referer':"http://mail.163.com/js6/main.jsp?sid=%s&df=mail163_letter"%self.sid,
'Connection':"keep-alive"
}
#发出请求并获得响应
request = urllib2.Request(listUrl,headers = Headers)
print listUrl
response = self.opener.open(request)
#提取响应的页面内容
content = response.read().decode('utf-8')
return content当然我们也可以打印出相应的内容以方便我们做后续的处理
print content这样我们就得到了收件箱页面的邮件列表信息,下边来解析这页代码。
提取邮件列表基本信息
输出刚才的内容我们会得到像下面这样的结果
...
<object>
<string name="id">48:1tbiMA34VVWBT7UDcQAAsM</string>
<int name="fid">1</int>
<int name="size">10183</int>
<string name="from">"网易邮件中心" <mail@service.netease.com></string>
<string name="to">"xxxxxxxxxxx.com" <xxxxxxxxx@163.com></string>
<string name="subject">丙申猴年,你的大圣,可会归来?</string>
<date name="sentDate">2016-01-23 12:30:37</date>
<date name="receivedDate">2016-01-23 12:30:37</date>
<int name="priority">3</int>
<int name="backgroundColor">0</int>
<string name="antiVirusStatus">unscaned</string>
<int name="label0">0</int>
<object name="flags">
<boolean name="read">true</boolean></object>
<object name="ctrls">
<string name="RulesType">ntessys</string></object>
<string name="hmid"><2134498648.1996962.1453523436698.JavaMail.mail@service.netease.com></string></object>
<object>
...这些代码段就是我们收件箱的基本信息,每个 object 标签中都包含了一个邮件的发件方、收件方、邮件主题、收发时间等信息。我们要做的就是利用正则表达式把这些信息提取出来(当然也可以用beautifulsoup来提取),并输出。每个标签中的内容都一样,故正则表达式及代码如下:
#获取邮件信息
def getmail(self):
#先获得收件箱列表页面内容
messages = self.messageList()
#信息提取的正则表达式
pattern = re.compile('<string name="from">"(.*?)".*?name="to">(.*?)<.*?name="subject">(.*?)<.*?name="sentDate">(.*?)<.*?name="receivedDate">(.*?)</date>',re.S)
#re模块中的findall会找出所有匹配的字符串,返回一个列表
mails = re.findall(pattern,messages)
#遍历列表输出中相应项的内容,每个(.*?)对应了相应的项
for mail in mails:
print '-'*50
print '发件人',mail[0],'主题',mail[2],'发送时间',mail[3]
print '收件人',mail[1],u'接收时间',mail[4]这样就可以输出收件箱所有邮件列表的基本信息。
下面附上完整代码:
# -*- coding:utf-8 -*-
import urllib
import urllib2
import re
import cookielib
#163邮箱类
class MAIL:
#初始化
def __init__(self):
#获取登录请求的网址
self.loginUrl = "https://mail.163.com/entry/cgi/ntesdoor?df=mail163_letter&from=web&funcid=loginone&iframe=1&language=-1&passtype=1&product=mail163&net=t&style=-1&race=-2_42_-2_hz"
#设置代理,以防止本地IP被封
self.proxyUrl = "http://202.106.16.36:3128"
#初始化sid码
self.sid = ""
#第一次登陆所需要的请求头request headers
self.loginHeaders = {
'Host':"mail.163.com",
'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0",
'Accept':"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
'Accept-Language':"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
'Accept-Encoding':"gzip, deflate, br",
'Referer':"http://mail.163.com/",
'Connection':"keep-alive",
}
#设置用户名和密码
self.username = 'xxxx'
self.pwd = 'xxxx'
#post所包含的参数
self.post = {
'savelogin':"0",
'url2':"http://mail.163.com/errorpage/error163.htm",
'username':self.username,
'password':self.pwd
}
#对post编码转换
self.postData = urllib.urlencode(self.post)
#设置代理
self.proxy = urllib2.ProxyHandler({'http':self.proxyUrl})
#设置cookie对象,会在登录后获取登录网页的cookie
self.cookie = cookielib.LWPCookieJar()
#设置cookie处理器
self.cookieHandler = urllib2.HTTPCookieProcessor(self.cookie)
#设置登录时用到的opener,相当于我们直接打开网页用的urlopen
self.opener = urllib2.build_opener(self.cookieHandler,self.proxy,urllib2.HTTPHandler)
#模拟登陆并获取sid码
def loginPage(self):
try:
#发出一个请求
request = urllib2.Request(self.loginUrl,self.postData,self.loginHeaders)
#得到响应
response = self.opener.open(request)
#需要将响应中的内容用read读取出来获得网页代码,网页编码为utf-8
content = response.read().decode('utf-8')
#打印获得的网页代码
print content
#设定提取sid码的正则表达式
sidpattern = re.compile('sid=(.*?)&',re.S)
result = re.search(sidpattern,content)
self.sid = result.group(1)
print self.sid
except urllib2.HTTPError, e:
print e.reason
#通过sid码获得邮箱收件箱信息
def messageList(self):
#重定向的网址
listUrl = 'http://mail.163.com/js6/s?sid=%s&func=mbox:listMessages&TopTabReaderShow=1&TopTabLofterShow=1&welcome_welcomemodule_mailrecom_click=1&LeftNavfolder1Click=1&mbox_folder_enter=1'%self.sid
#新的请求头
Headers = {
'Host':"mail.163.com",
'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0",
'Accept':"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
'Accept-Language':"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
'Accept-Encoding':"gzip, deflate, br",
'Referer':"http://mail.163.com/js6/main.jsp?sid=%s&df=mail163_letter"%self.sid,
'Connection':"keep-alive"
}
#发出请求并获得响应
request = urllib2.Request(listUrl,headers = Headers)
response = self.opener.open(request)
#提取响应的页面内容
content = response.read().decode('utf-8')
return content
#获取邮件信息
def getmail(self):
messages = self.messageList()
pattern = re.compile('<string name="from">"(.*?)".*?name="to">(.*?)<.*?name="subject">(.*?)<.*?name="sentDate">(.*?)<.*?name="receivedDate">(.*?)</date>',re.S)
mails = re.findall(pattern,messages)
for mail in mails:
print '-'*50
print '发件人',mail[0],'主题',mail[2],'发送时间',mail[3]
print '收件人',mail[1],u'接收时间',mail[4]
#创建163邮箱爬虫类
mail = MAIL()
mail.loginPage()
mail.getmail()
谢谢观看,看完后也可以去试试,第一次写,写的不好的地方望指正。

















 719
719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









