







"ApacheSpark is a fast and general engine for large-scale dataprocessing."
实习需要调研Spark和SparkStreaming,因此特地来研究一下咯~
首先,它是一个快速/通用的引擎,用于大数据处理。按照官网的说法:"Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk."
然后关键词我想应该是“开源的 数据分析 基于内存 分布式集群计算框架”。
它同时支持Batch(批量数据)、Interactive(交互查询)、Streaming(实施数据流)的处理,且兼容支持HDFS和S3等分布式文件系统,可以部署在YARN和Mesos等流行的集群资源管理器之上。后面编译的过程中可以看到它自动下载了非常多的jar,包括hadoop、Hbase、cassandra均能和它一起工作..
下面就来看看如何配置与安装咯。
系统:64位Ubuntu12.04
1.配置java环境
网上教程一大把~这里不说咯。
2.配置scala环境
去官网下载最新的scala二进制包
解压
tar -zxf scala-2.11.1.tgz
复制
cp -r scala-2.11.1/ usr/bin/
设置环境变量
sudo gedit /etc/profile
于文件中添加
export PATH=$PATH:/usr/bin/scala-2.11.1/bin
保存并退出,刷新
source /etc/profile
测试一下:
scala -version

3.编译spark
去官网下载spark的source file
同样的解压之后进入spark执行编译指令
stedraw@ubuntu:~/spark-1.0.0$ sbt/sbt assembly
这个过程中它会下载非常多的jar,最后compile,整个过程比较漫长,时长受网速和电脑性能一定影响...正常情况下也要一个半小时左右。
中间半天不动了,有可能网络不畅,ctrl+c退出,重新执行sbt,可以继续之前的操作。
(compiling的部分就不要中断了,会从头编译。)

最后,进入/spark-1.0.0/bin,执行
./spark-shell
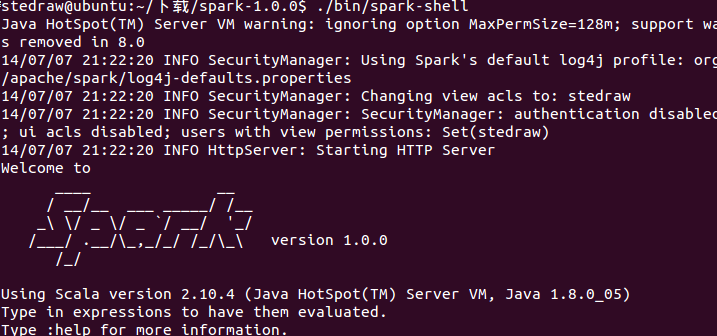
就可以交互式编程啦。















 1893
1893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









