







Cobar是关系型数据的分布式处理系统,它可以在分布式的环境上看上去就像传统数据库一样提供海量的数据服务。
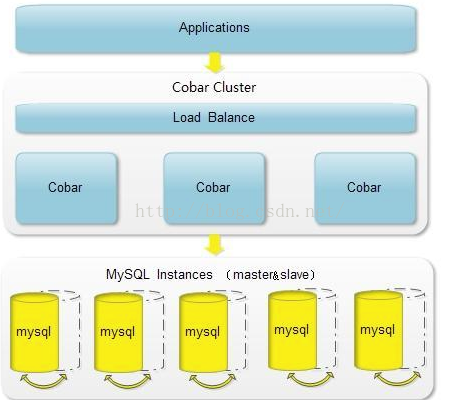
二:cobar如何实现分布式
通过将表放入不同的库来实现分布式数据库。
1.cobar支持将一张表水平拆分成多份放入不同的库来实现表的水平拆分(拆分后的表不能再同一个库中)
2.cobar支持将不同的表放入不同的库中
多数情况下,用户会将以上两种方式混合使用
3.分库数必须能被1024整除,
3.连接cobar以及corbar的功能约束
(1)不支持跨库情况下的join,分页,排序,子查询操作
(2)SET语句执行会被忽略,事务和字符集设置除外;
(3)分库情况下,insert语句必须包含拆分的字段列名。
(4)分库情况下,update语句不能更新拆分字段的值。
(5)不支持SVAEPOINT操作。
(6)暂时只支持MySQL数据节点。
7) 使用JDBC时,不支持rewriteBatchedStatements=true参数设置(默认为false)。
8) 使用JDBC时,不支持useServerPrepStmts=true参数设置(默认为false)。
9) 使用JDBC时,BLOB, BINARY, VARBINARY字段不能使用setBlob()或setBinaryStream()方法设置参数。
cobar默认端口为8066
4.cobar路由
1.大部分情况下使用单维路由一足够
2.路由实例:(以256为例)

5.二维路由会导致多库执行,性能较差,不推荐使用
(1)两个路由字段都确定:

(2)只有一个路由字段时:
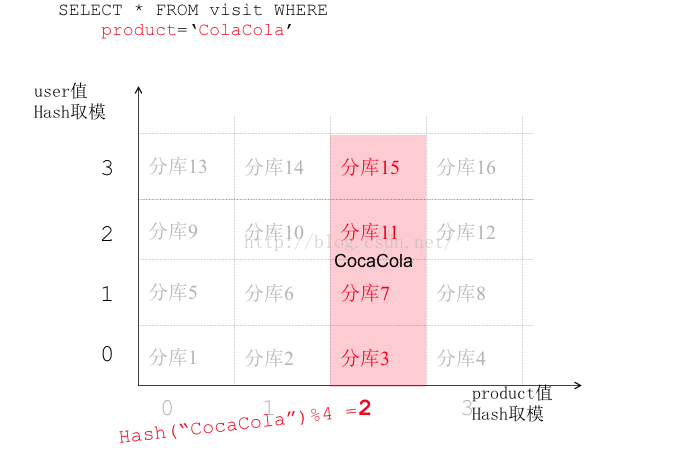
替代方案:(1)再建一张另一维度的表,两张表数据保持一致(通过消息保证数据最终一致)
(2)使用搜索引擎















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









