







JAVA爬虫--httpClient模拟发送请求
1.项目背景
使用JAVA编写的知乎爬虫,根据“轮带逛”这一原理,搜索轮子哥的所有动态,根据关键字来筛选感兴趣的问题,所有搜索到的问题链接会放到项目目录“fetchedData”下面。
2.开发过程
其实要爬取轮子哥的所有动态我们都不需要登陆(但是代码里也加了这部分,方便以后其他需求)。我们点开轮子哥的知乎主页:http://www.zhihu.com/people/excited-vczh。
接着发现页面里有个“更多”的按钮:

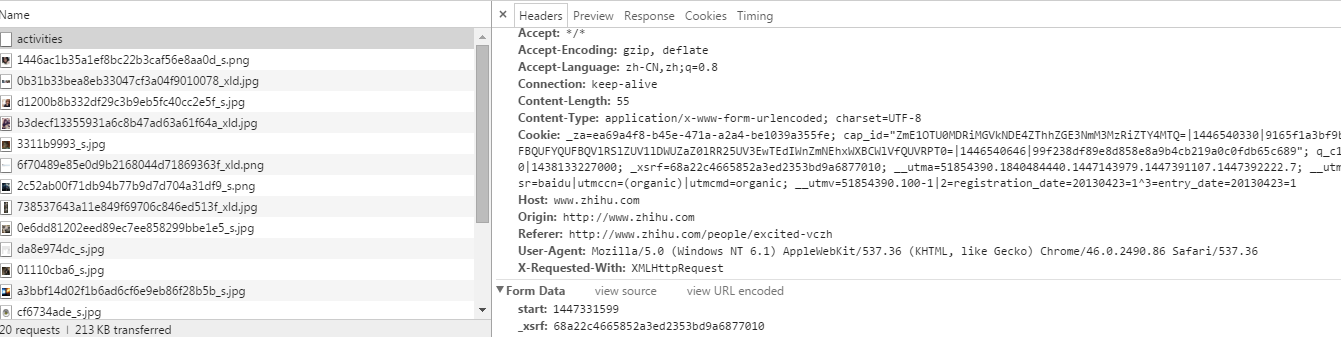
activities这个请求便是了。这儿有两个参数:start和_xsrf,
- start, 应该是记录时间的变量
_xsrf,猜测是一种验证机制
对于这两个变量 我们查看当前网页的源码(鼠标右键然后查看网页源代码),发现:

这个data-time是不是和上面的start比较像!猜测activities请求应该是从这个start这个时间节点开始得到动态。
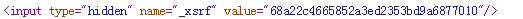
而这个位于hidden区域的_xsrf应该就是第二个参数了。
这么一来我们只要从源代码中获取这两个参数再发送过去就好了~
要注意的是在HttpPost设置header时,不能完全照着网页请求的来,其中一条"Accept-Language"要去掉:
httpPost.setHeader("(Request-Line)","POST /login HTTP/1.1");
httpPost.setHeader("Accept","*/*");
httpPost.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36");
httpPost.setHeader("Referer", "http://www.zhihu.com/people/excited-vczh");
httpPost.setHeader("Origin", "http://www.zhihu.com");
httpPost.setHeader("Host", "www.zhihu.com");
httpPost.setHeader("Content-Type", "application/x-www-form-urlencoded; charset=UTF-8"); //
httpPost.setHeader("Accept-Language","zh-CN,zh;q=0.8");
// httpPost.setHeader("Accept-Encoding","gzip, deflate");
不然得到的内容会是乱码。
这样我们每次解析一条请求时能拿到下一条请求的开始时间参数data-time,将获取到的url放到一个队列里,发送完一个请求再继续发送下一个请求。
另外我们项目代码是从文件“filter.conf”中读取关键字来筛选问题的,这样就能选取自己感兴趣的话题啦!
所有项目代码已上传到github: https://github.com/StormSpirit22/ZhihuSpider















 648
648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









