







静态查找表
(一)顺序表的查找
Ø 静态查找表的存储结构可用顺序表或线性链表表示。
Ø 本节只讨论在顺序存储结构中查找的实现。
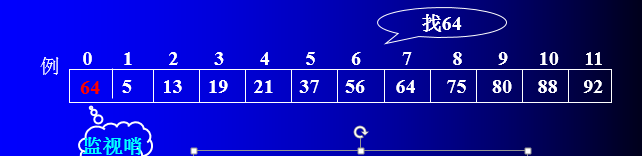
顺序查找的基本思想:从表中最后一个记录开始,逐个进行记录的关键字和给定值的比较,若某个记录的关键字和给定值比较相等,
则查找成功,找到所查记录;反之,若直至第一个记录,其关键字和给定值比较都不等,则表明表中没有所查记录,查找不成功。

#define M 500
typedef struct
{ int key ;
float info ;
}JD ;
int seqsrch ( JD r[ ], int n, int k )
{ int i=n ;
r[0].key=k ;
while ( r[i].key!= k )
i-- ;
return ( i ) ;
}
监测哨的作用:
(1)省去判定循环中下标越界的条件,从而节约比较时间。
(2)保存查找值的副本,查找时若遇到它,则表示查找不成功。这样在从后向
前查找失败时,不必判断查找表是否检测完,从而达到算法统一。
顺序查找性能分析:
对一个含有 n 个数据元素的表,查找成功时有:
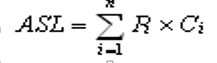
上述算法中,对于有 n 个数据元素的表,给定值 k与表中第 i 个元素的关键字相等
,即定位第 i 个记录时,需进行:ni+1次关键字比较,即 Ci=ni+1。则查找成功时
,顺序查找的平均查找长度为:
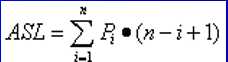
算法中的基本工作就是关键字的比较,因此,
查找长度的量级就是查找算法的时间复杂度为 O(n) 。
顺序查找缺点是当 n 很大时,平均查找长度较大,效率低;优点是对
表中数据元素的存储没有特殊要求。
(二)有序表的查找(二分法查找)
以有序表表示静态查找表时,可用二分法查找法来实现查找。
二分查找,是一种效率较高的查找方法,但前提是表中元素必须按关键字有序(按关键字递增或递减)排列。
算法思想
二分法查找的基本思想:
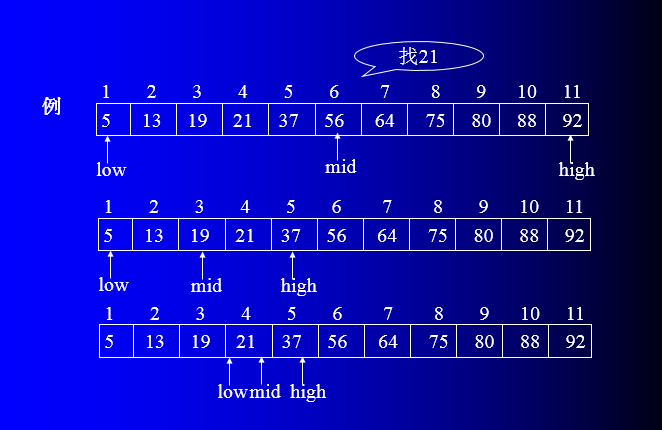
在有序表中,取中间元素作为比较对象,若给定值与中间元素的关键字相等,则查找成功;若给定值小于中间元素的关键字,则在中间元素的左半区继续查找;若给定值大于中间元素的关键字,则在中间元素的右半区继续查找。不断重复上述查找过程,直到查找成功,或所查找的区域无数据元素,查找失败。
在有序表中,取中间元素作为比较对象,若给定值与中间元素的关键字相等,则查找成功;若给定值小于中间元素的关键字,则在中间元素的左半区继续查找;若给定值大于中间元素的关键字,则在中间元素的右半区继续查找。不断重复上述查找过程,直到查找成功,或所查找的区域无数据元素,查找失败。
算法实现:
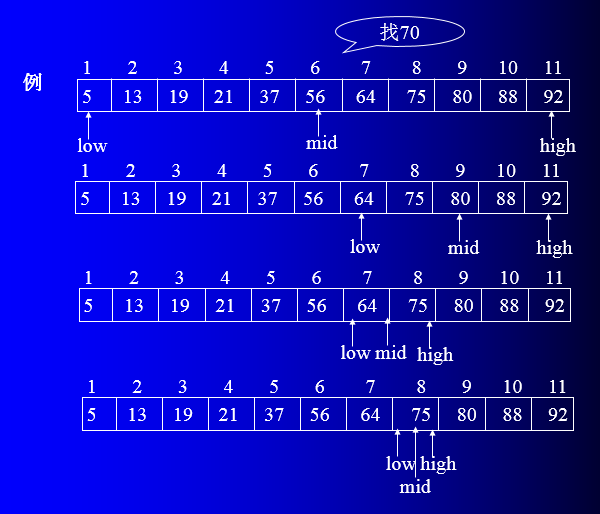
设表长为n,low,high 和 mid分别指向待查元素所在区间的上界、下界和中点, k为给定值。初始时,令low=1 , high=n , mid=(low+high)/2
让 k 与 mid 指向的记录比较:
若 k == r[mid].key,则查找成功
若 k < r[mid].key, 则 high=mid-1
若 k > r[mid].key, 则 low=mid+1
重复上述操作,直至low>high时,查找失败
代码实现
#define M 500
typedef struct
{ int key ;
float info ;
}JD ;
int binsrch ( JD r[ ], int n, int k )
{ int low, high, mid, found ;
low=1; high=n;
found=0; // found 为找到标志。值为 0 表示未找到。
while ( (low<=high) && (found==0) )
{ mid=( low+high ) / 2;
if ( k>r[mid].key ) low=mid+1;
else if ( k==r[mid].key ) found=1;
else high=mid-1;
}
if ( found==1 ) // 如果已找到
return ( mid ) ; // 找到的记录的下标肯定为 mid
else
return ( 0 );
}
性能分析
从二分法查找的过程看,每次查找都是以表的中点为比较对象,并以中
点将表分割为两个子表,对定位到的子表继续作同样的操作。所以,对表
中每个数据元素的查找过程,可用二叉树来描述,称这个描述查找过程的
二叉树称为判定树。
判定树中每一结点对应表中一个记录,但结点值不是某个记录的关键
字,而是某个记录在表中的位置序号。根结点对应当前区间的中间记录,
左子树对应前一子表,右子树对应后一子表。
点将表分割为两个子表,对定位到的子表继续作同样的操作。所以,对表
中每个数据元素的查找过程,可用二叉树来描述,称这个描述查找过程的
二叉树称为判定树。
判定树中每一结点对应表中一个记录,但结点值不是某个记录的关键
字,而是某个记录在表中的位置序号。根结点对应当前区间的中间记录,
左子树对应前一子表,右子树对应后一子表。
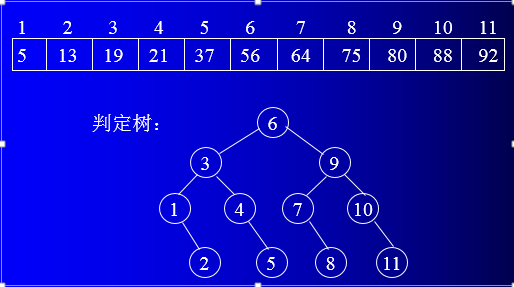
从上面判定树可看到,查找第一层的根结点 56,一次比较即可找
到; 查找第二层的结点 19 和 80, 二次比较即可找到; 查找第三层的
结点 5、21、64、88,三次比较即可找到;查找第四层的结点 13,37、
75、92,四次比较即可找到。
到; 查找第二层的结点 19 和 80, 二次比较即可找到; 查找第三层的
结点 5、21、64、88,三次比较即可找到;查找第四层的结点 13,37、
75、92,四次比较即可找到。
查找表中任一元素的过程,即是判定树中从根到该元素结点路径上各结点关键字的比较次数,也即该元素结点在树中的层次数。
n 个结点的判定树,树高为 k,则有 2k-1-1<n≤2k-1,即 k-1<log2(n+1)≤k,
所以 k= log2(n+1) 。因此,二分查找在查找成功时,进行的关键字比较次数至
多为 log2(n+1) 。
以树高为 k 的满二叉树( n=2k-1 )为例。
假设表中每个元素的查找是等概率的,即 Pi= ,
则树的第 i 层有 2i-1 个结点。
二分查找的平均查找长度为:
n 个结点的判定树,树高为 k,则有 2k-1-1<n≤2k-1,即 k-1<log2(n+1)≤k,
所以 k= log2(n+1) 。因此,二分查找在查找成功时,进行的关键字比较次数至
多为 log2(n+1) 。
以树高为 k 的满二叉树( n=2k-1 )为例。
假设表中每个元素的查找是等概率的,即 Pi= ,
则树的第 i 层有 2i-1 个结点。
二分查找的平均查找长度为:
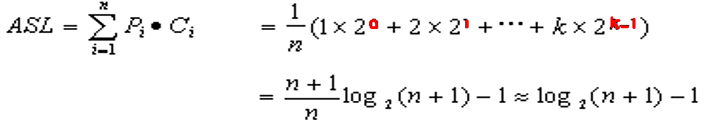
时间复杂度分析
所以,二分查找的时间复杂度为:O (log2n)。
二分查找的优点:效率高。
二分查找的缺点:
必须按关键字排序,有时排序也很费时;
只适用顺序存储结构,所以进行插入、删除操作必须移动大量的结点。
二分查找适用于一经建立就很少改动,而又经常需要查找的线性表。
对于经常需要改动的线性表,可采用链表存储结构,进行顺序查找。
二分查找的优点:效率高。
二分查找的缺点:
必须按关键字排序,有时排序也很费时;
只适用顺序存储结构,所以进行插入、删除操作必须移动大量的结点。
二分查找适用于一经建立就很少改动,而又经常需要查找的线性表。
对于经常需要改动的线性表,可采用链表存储结构,进行顺序查找。
3.索引顺序表的查找
Ø若以索引顺序表表示静态查找表,可用
分块查找法实现查找。
Ø分块查找又称索引顺序查找,是顺序查找的一种改进方法。
查找过程:
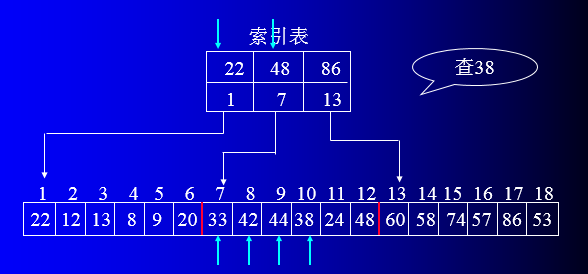
将表分成几块,块内无序,块间有序;先确定待查记录所在块,再在块内查找。
算法实现:
用数组存放待查记录,每个数据元素至少含有关键字域。
建立索引表,每个索引表结点含有最大关键字域和指向本块第一个结点的指针。
typedef struct
{ int key ;
int link ;
} SD;
typedef struct
{ int key;
float info;
}JD;
int blocksrch ( JD r[ ], SD d[ ], int b, int k, int n )
{ int i=1, j ;
while( ( k > d[i].key ) &&( i<=b ) ) // 确定要比较的值 k 在哪一块
i++; // k <= d[i].key 时的 i 就确定了 k 所在块的索引结点下标序号
if ( i>b )
{ printf("\n Not found"); return( 0 ); }
j = d[i].link; // 要比较的值 k 在以d[i].link 为起点下标的块中
while ( (j<n) && (k!=r[j].key) && (r[j].key<=d[i].key))
j++; // 在所在块中进行顺序查找
if ( k != r[j].key )
{ j=0; printf ("\n Not found"); }
return ( j ) ;
}
分块查找方法评价:

查找方法比较
| 顺序查找 | 二分法查找 | 索引查找 | |
| ASL | 最大 | 最小 | 两者之间 |
| 表结构 | 有序表、无序表 | 有序表 | 分块有序表 |
| 分块有序表 | 顺序存储结构 线性链表 | 顺序存储结构 线性链表 | 顺序存储结构 线性链表 |














 188
188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









