







tess4j用于识别图像上的文字信息,步骤如下:
1.下载tesseract的安装包:
https://sourceforge.net/projects/tesseract-ocr-alt/files/?source=navbar(Windows下下载exe版本);
2.安装成功之后,输入【tesseract】,出现如下信息表示安装成功。
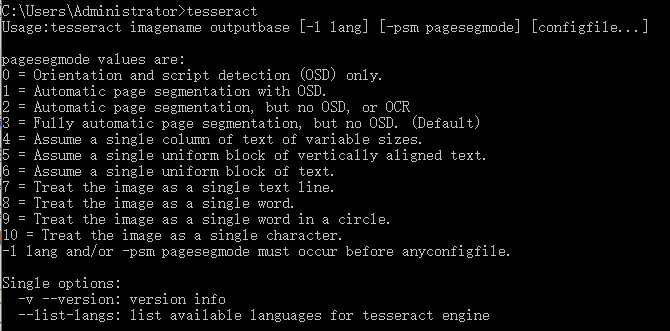
3.使用cmd方式测试tesseract能否使用
(1)进入到放置图片的路径(图片内容为英文)
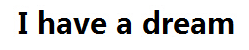
(2)输入【tesseract.exe 3.jpg 3】—–表示识别3.jpg这张图,并且将结果写入到3.txt这个文件夹中。
2.下载tess4j源码:
https://sourceforge.net/projects/tess4j/files/tess4j/(3.2.1对应的版jdk版本是1.8的,其它的没试过)
3.新建一个java工程,将tess4J下载下来的源码包下面的lib、src目录下面的分别复制到新建的java工程中;
4.使用如下代码测试能否使用
File imageFile = new File("E:\\test\\5.png");
ITesseract instance = new Tesseract(); // JNA Interface Mapping
try {
String result = instance.doOCR(imageFile);
System.out.println(result);
} catch (TesseractException e) {
System.err.println(e.getMessage());
}














 5337
5337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









