







春节的跳槽季又到了,相信很多人是通过拉钩网站来选择下一家公司的。 但是,拉钩网站无法像某招聘网站那样通过区域来筛选。所以,今天特地写了一个Python脚本来爬取所有的公司详细地址,并导出到xls文件内进行筛选。下面记录一下自己的思考过程。
项目地址 https://github.com/sunbohong/exportCompanysFromLagou
获取招聘公司信息
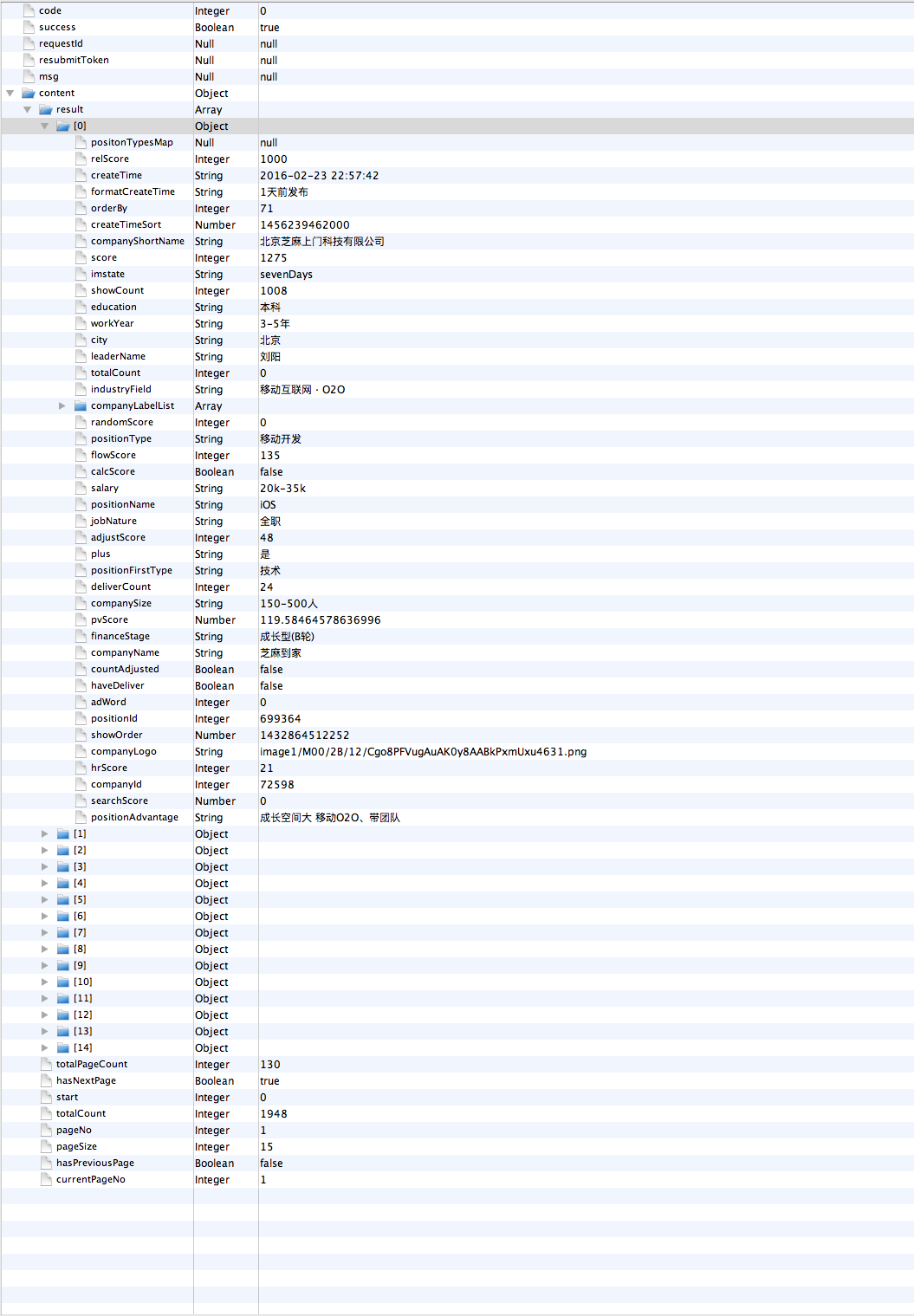
通过Charles分析拉钩网站的请求可以发现:当通过关键字查找职位的方式(比如:http://www.lagou.com/zhaopin/iOS)获取招聘信息时,网页内会通过调用ajax获取下一页的公司信息。其url为http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC 并附带 参数。返回信息结构下图所示。很明显,返回信息并没有包含公司的详细地址,所以,我们需要进行下一步的获取。
first=false&pn=2&kd=iOS
获取详细地址
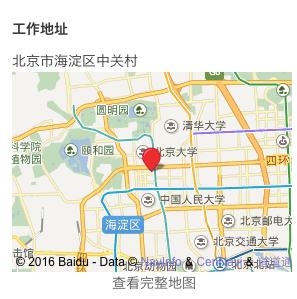
当我们点击职位的链接是,网页会跳转到 http://www.lagou.com/jobs/1453123.html 。我们可以在页面右侧中部发现公司的详细地址,如下图所示。所以,我们只需要获取这个地址就可以达到目的了。
通过Python编程实现
定义模块
#-*- coding:utf-8 -*-
#!/usr/bin/python
#命令行工具
import click
import json
import urllib
import urllib2
from json2xls import Json2Xls
class exportCompanysFromLagou(object):
"""exportFromLagou API
:param string kd:职位名
:param string city:指定的城市名
:param bool get_detail_location:是否获取详细地址
"""
def __init__(self, kd, city='北京',get_detail_location=True):
self.kd = kd
self.city=city
print self.city
self.get_detail_location=get_detail_location
#保存公司信息
self.companys=[]
self.url = "http://www.lagou.com/jobs/positionAjax.json?"+urllib.urlencode({'city':self.city.encode('utf-8')})
def make(self):
@click.command()
@click.argument('kd')
@click.option('--city', '-c', default='北京')
@click.option('--get_detail_location', '-l',default=True)
def make(kd,city,get_detail_location):
exportCompanysFromLagou(kd,city=city,get_detail_location=get_detail_location).make()
if __name__ == '__main__':
make()获取职位页数
添加getTotalPageNo函数和getJsonData函数
def getTotalPageNo(self):
parameters = {'first':'false', 'pn':1, 'kd':self.kd}
jsonData=self.getJsonData(self.url,parameters)
# 判断返回数据是否正确
code = jsonData["code"]
if code == 0 :
totalPageCount = jsonData["content"]["totalPageCount"]
return totalPageCount
return 0
def getJsonData(self,url,parameters):
req = urllib2.Request(url)
data = urllib.urlencode(parameters)
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor())
response = opener.open(req, data)
# 读取数据
obj = response.read()
# 转json
jsonData=json.loads(obj)
return jsonData在make函数内添加对totalPageCount调用
def make(self):
totalPageCount = self.getTotalPageNo()
print "一共有%s页数据" % totalPageCount
获取公司数据
def getCompanys(self,url,parameters):
jsonData=self.getJsonData(url,parameters)
# 判断返回数据是否正确
code = jsonData["code"]
if code == 0 :
self.companys.extend(jsonData["content"]["result"]) 在make函数内添加调用
for i in xrange(1,totalPageCount+1):
parameters = {'first':'false', 'pn':i, 'kd':self.kd}
self.getCompanys(self.url,parameters)
print "已经获取%d页" % i
获取公司的详细地址
通过尝试修改浏览器的UA,可以发现职位介绍页面对应mobile地址为http://www.lagou.com/center/job_10000.html?m=1 ,我们在这里访问这个地址,以较少网络请求
def getLocation(self):
print "正在获取准确的公司地址"
for company in self.companys:
url = "http://www.lagou.com/center/job_%s.html?m=1" % company["positionId"]
req = urllib2.Request(url)
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor())
response = opener.open(req)
# 读取数据
obj = response.read()
s0 = obj.find("global.companyAddress = '")
s1 = obj.find(" global.imgUrl ")
company['location']=obj[s0+25:s1-6]在make函数内添加调用
if self.get_detail_location:
self.getLocation()保存到xls文件
在这里,以职位名+城市进行保存
def saveToFile(self):
self.filesavepath = '%s-%s.xls' % (self.kd,self.city)
if len(self.companys)>0:
obj = Json2Xls(self.filesavepath, json.dumps(self.companys))
obj.make()
print u"已保存到%s" % self.filesavepath在make函数内添加调用
self.saveToFile()















 1591
1591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









