







因为要写个demo出来,所以在网上找了很多资料,文章都是站在各个博主巨人肩上拼凑出来的。
一、Raft 协议的易理解性描述
在一个由 Raft 协议组织的集群中有三类角色:
- Leader(领袖)
- Follower(群众)
- Candidate(候选人)
就像一个民主社会,领袖由民众投票选出。刚开始没有领袖,所有集群中的参与者都是群众,那么首先开启一轮大选,在大选期间所有群众都能参与竞选,这时所有群众的角色就变成了候选人,民主投票选出领袖后就开始了这届领袖的任期,然后选举结束,所有除领袖的候选人又变回群众角色服从领袖领导。这里提到一个概念「任期」,用术语 Term 表达(后面会详细讲解)。关于 Raft 协议的核心概念和术语就这么多而且和现实民主制度非常匹配,所以很容易理解。三类角色的变迁图如下,结合后面的选举过程来看很容易理解。
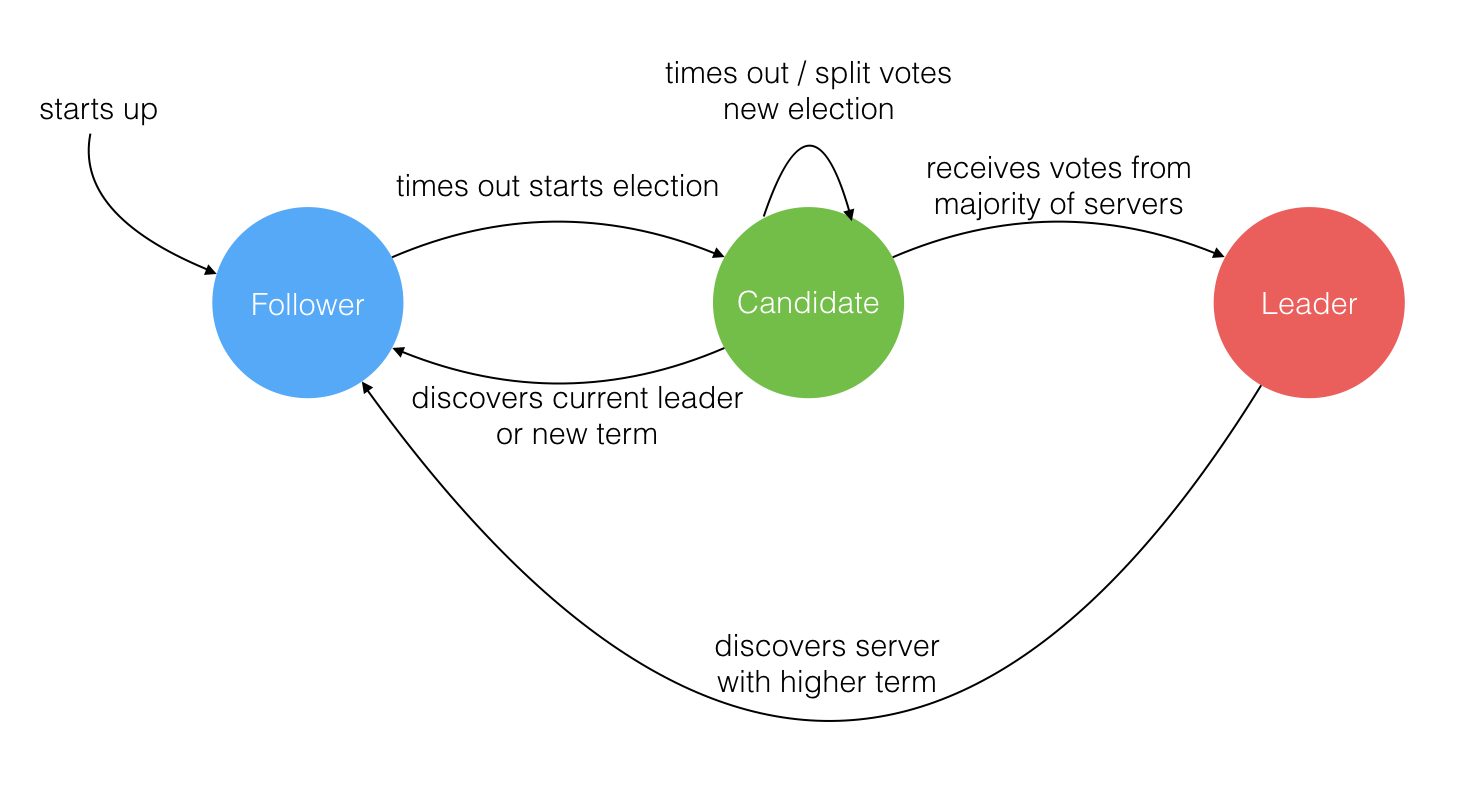
Leader 选举过程
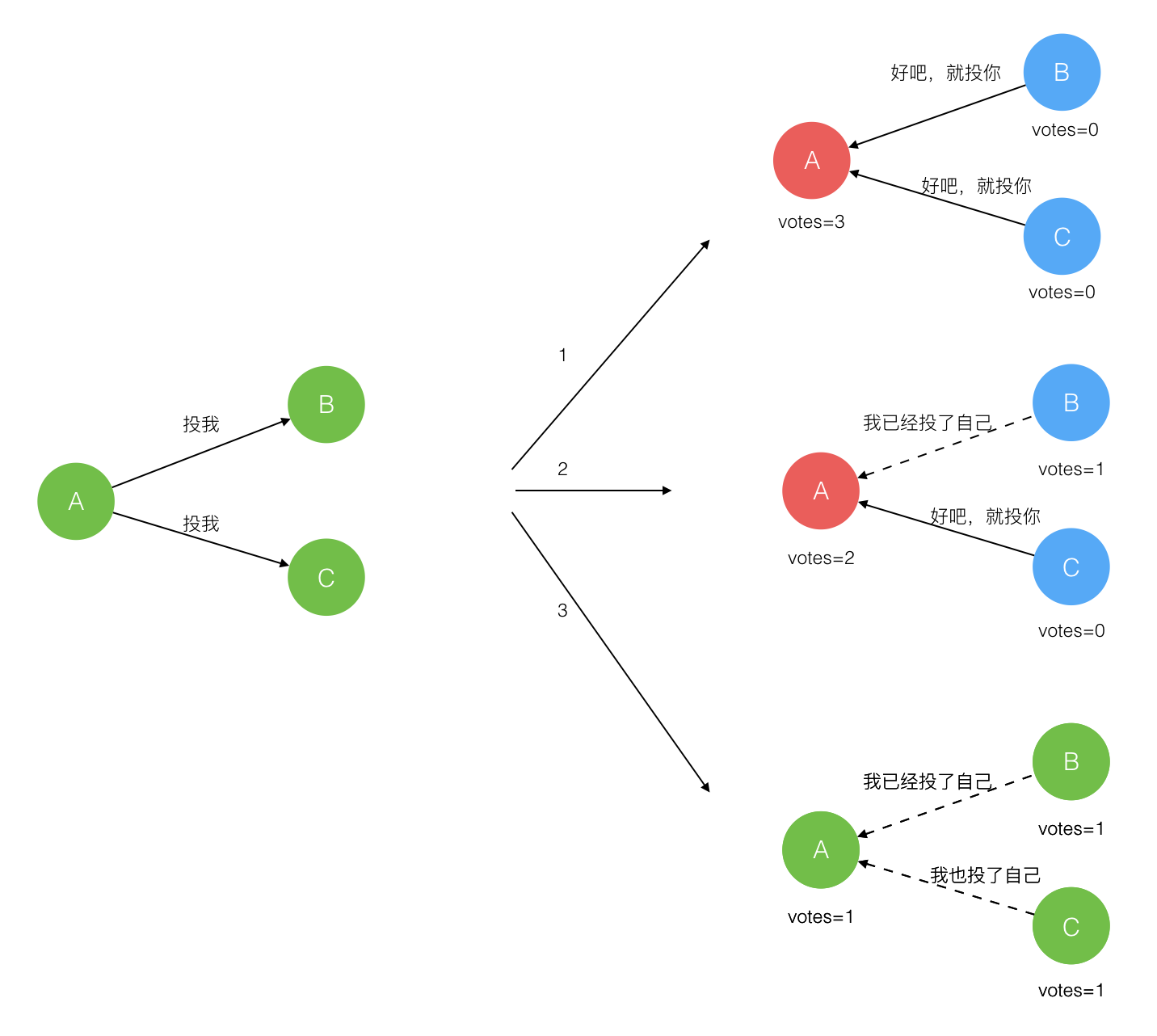
在极简的思维下,一个最小的 Raft 民主集群需要三个参与者(如下图:A、B、C),这样才可能投出多数票。初始状态 ABC 都是 Follower,然后发起选举这时有三种可能情形发生。下图中前二种都能选出 Leader,第三种则表明本轮投票无效(Split Votes),每方都投给了自己,结果没有任何一方获得多数票。之后每个参与方随机休息一阵(Election Timeout)重新发起投票直到一方获得多数票。这里的关键就是随机 timeout,最先从 timeout 中恢复发起投票的一方向还在 timeout 中的另外两方请求投票,这时它们就只能投给对方了,很快达成一致。
选出 Leader 后,Leader 通过定期向所有 Follower 发送心跳信息维持其统治。若 Follower 一段时间未收到 Leader 的心跳则认为 Leader 可能已经挂了再次发起选主过程。
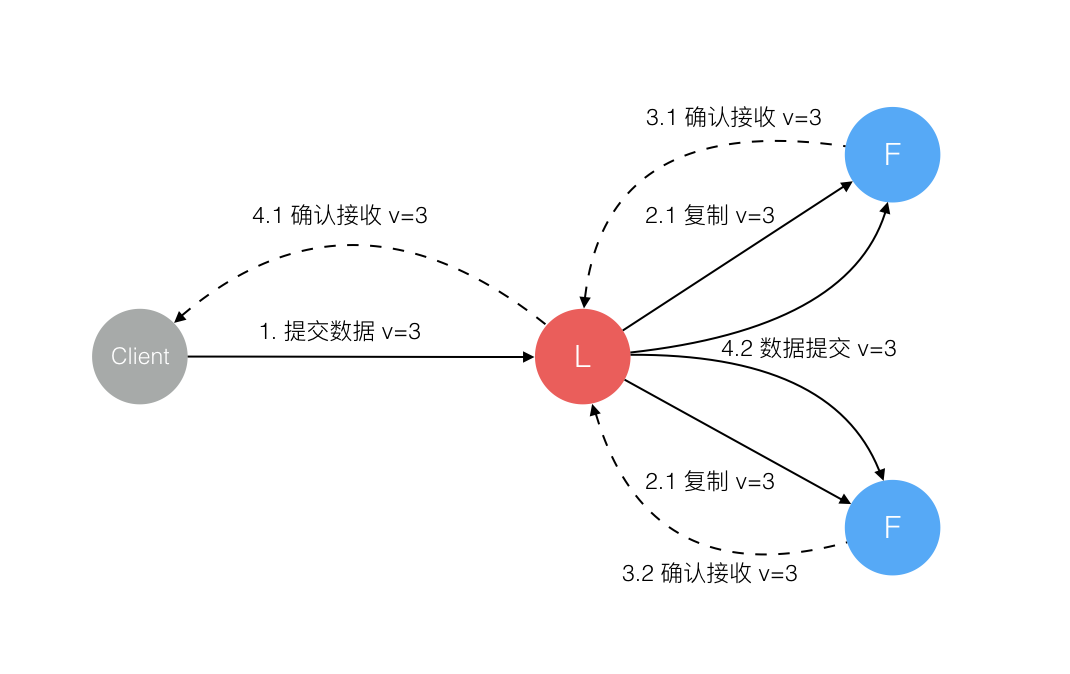
Leader 节点对一致性的影响
Raft 协议强依赖 Leader 节点的可用性来确保集群数据的一致性。数据的流向只能从 Leader 节点向 Follower 节点转移。当 Client 向集群 Leader 节点提交数据后,Leader 节点接收到的数据处于未提交状态(Uncommitted),接着 Leader 节点会并发向所有 Follower 节点复制数据并等待接收响应,确保至少集群中超过半数节点已接收到数据后再向 Client 确认数据已接收。一旦向 Client 发出数据接收 Ack 响应后,表明此时数据状态进入已提交(Committed),Leader 节点再向 Follower 节点发通知告知该数据状态已提交。
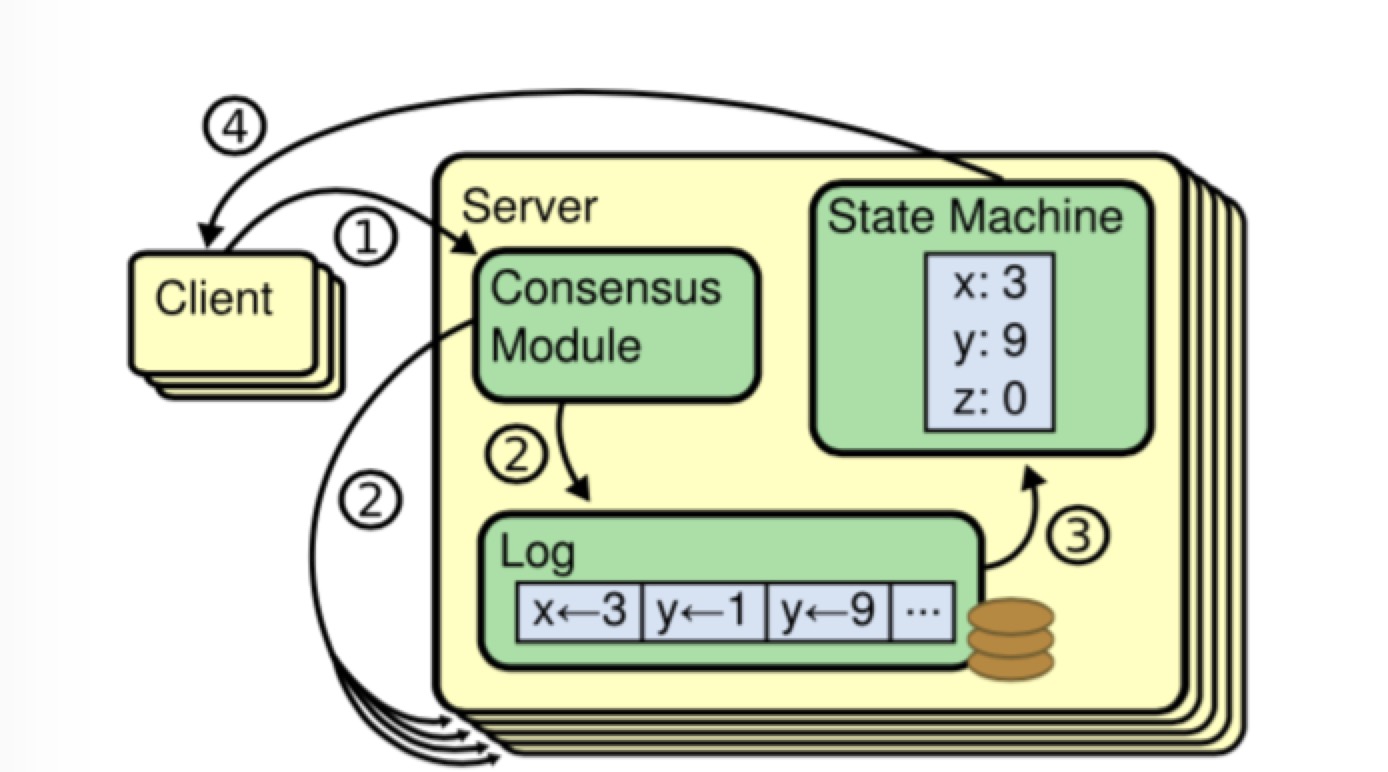
二、Raft 实现建模
1.应用场景
1. Symmetric, leader-less
所有Server都是对等的,Client可以和任意Server进行交互
2. Asymmetric, leader-based
任意时刻,有且仅有1台Server拥有决策权,Client仅和该Leader交互。
本文的raft算法是采用的后者。
2.几个元素介绍
- 在服务器刚启动的时候,都属于Role.Follower状态,它接收Leader的RPC请求。如果经过一定时间没有发现Leader及没有接受到心跳,timeout监听触发,
- StateMachine中转换Role到Candidate状态,开始Leader的选举:
- 发送请求后,收到远程服务器响应。有两种情况结果:
- Leader只有在发现比自己高term的Leader的时候才会转换成Follower。调用discoverHigherTerm()方法,改变当前StateMachine;
- 所有的Server均以Follower角色启动,并启动选举定时器
- Follower期望从Leader或者Candidate接收RPC
- Leader必须广播Heartbeat重置Follower的选举定时器
- 如果Follower选举定时器超时,则假定Leader已经crash,发起选举
参考资料:















 968
968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









