海量数据处理以及缓存穿透这两个场景让我认识了 布隆过滤器 ,我查阅了一些资料来了解它,但是很多现成资料并不满足我的需求,所以就决定自己总结一篇关于布隆过滤器的文章。希望通过这篇文章让更多人了解布隆过滤器,并且会实际去使用它!
下面我们将分为几个方面来介绍布隆过滤器:
1. 什么是布隆过滤器?
2. 布隆过滤器的原理介绍。
3. 布隆过滤器使用场景。
4. 通过 Java 编程手动实现布隆过滤器。
5. 利用Google开源的Guava中自带的布隆过滤器。
6. Redis 中的布隆过滤器。
### 1.什么是布隆过滤器?
首先,我们需要了解布隆过滤器的概念。
布隆过滤器(Bloom Filter)是一个叫做 Bloom 的老哥于1970年提出的。我们可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构。相比于我们平时常用的的 List、Map 、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。理论情况下添加到集合中的元素越多,误报的可能性就越大。并且,存放在布隆过滤器的数据不容易删除。

位数组中的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1。这样申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 kb ≈ 122kb 的空间。
总结:**一个名叫 Bloom 的人提出了一种来检索元素是否在给定大集合中的数据结构,这种数据结构是高效且性能很好的,但缺点是具有一定的错误识别率和删除难度。并且,理论情况下,添加到集合中的元素越多,误报的可能性就越大。**
### 2.布隆过滤器的原理介绍
**当一个元素加入布隆过滤器中的时候,会进行如下操作:**
1. 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
2. 根据得到的哈希值,在位数组中把对应下标的值置为 1。
**当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行如下操作:**
1. 对给定元素再次进行相同的哈希计算;
2. 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
举个简单的例子:
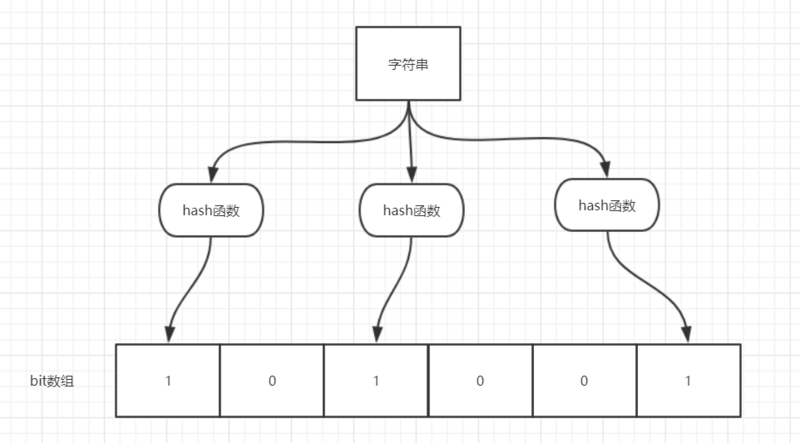
如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后在对应的位数组的下表的元素设置为 1(当位数组初始化时 ,所有位置均为0)。当第二次存储相同字符串时,因为先前的对应位置已设置为1,所以很容易知道此值已经存在(去重非常方便)。
如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
**不同的字符串可能哈希出来的位置相同,这种情况我们可以适当增加位数组大小或者调整我们的哈希函数。**
综上,我们可以得出:**布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。**
### 3.布隆过滤器使用场景
1. 判断给定数据是否存在:比如判断一个数字是否在于包含大量数字的数字集中(数字集很大,5亿以上!)、 防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)等等、邮箱的垃圾邮件过滤、黑名单功能等等。
2. 去重:比如爬给定网址的时候对已经爬取过的 URL 去重。
### 4.通过 Java 编程手动实现布隆过滤器
我们上面已经说了布隆过滤器的原理,知道了布隆过滤器的原理之后就可以自己手动实现一个了。
如果你想要手动实现一个的话,你需要:
1. 一个合适大小的位数组保存数据
2. 几个不同的哈希函数
3. 添加元素到位数组(布隆过滤器)的方法实现
4. 判断给定元素是否存在于位数组(布隆过滤器)的方法实现。
下面给出一个我觉得写的还算不错的代码(参考网上已有代码改进得到,对于所有类型对象皆适用):
```java
import java.util.BitSet;
public class MyBloomFilter {
/**
* 位数组的大小
*/
private static final int DEFAULT_SIZE = 2 << 24;
/**
* 通过这个数组可以创建 6 个不同的哈希函数
*/
private static final int[] SEEDS = new int[]{3, 13, 46, 71, 91, 134};
/**
* 位数组。数组中的元素只能是 0 或者 1
*/
private BitSet bits = new BitSet(DEFAULT_SIZE);
/**
* 存放包含 hash 函数的类的数组
*/
private SimpleHash[] func = new SimpleHash[SEEDS.length];
/**
* 初始化多个包含 hash 函数的类的数组,每个类中的 hash 函数都不一样
*/
public MyBloomFilter() {
// 初始化多个不同的 Hash 函数
for (int i = 0; i < SEEDS.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, SEEDS[i]);
}
}
/**
* 添加元素到位数组
*/
public void add(Object value) {
for (SimpleHash f : func) {
bits.set(f.hash(value), true);
}
}
/**
* 判断指定元素是否存在于位数组
*/
public boolean contains(Object value) {
boolean ret = true;
for (SimpleHash f : func) {
ret = ret && bits.get(f.hash(value));
}
return ret;
}
/**
* 静态内部类。用于 hash 操作!
*/
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
/**
* 计算 hash 值
*/
public int hash(Object value) {
int h;
return (value == null) ? 0 : Math.abs(seed * (cap - 1) & ((h = value.hashCode()) ^ (h >>> 16)));
}
}
}
```
测试:
```java
String value1 = "https://javaguide.cn/";
String value2 = "https://github.com/Snailclimb";
MyBloomFilter filter = new MyBloomFilter();
System.out.println(filter.contains(value1));
System.out.println(filter.contains(value2));
filter.add(value1);
filter.add(value2);
System.out.println(filter.contains(value1));
System.out.println(filter.contains(value2));
```
Output:
```
false
false
true
true
```
测试:
```java
Integer value1 = 13423;
Integer value2 = 22131;
MyBloomFilter filter = new MyBloomFilter();
System.out.println(filter.contains(value1));
System.out.println(filter.contains(value2));
filter.add(value1);
filter.add(value2);
System.out.println(filter.contains(value1));
System.out.println(filter.contains(value2));
```
Output:
```java
false
false
true
true
```
### 5.利用Google开源的 Guava中自带的布隆过滤器
自己实现的目的主要是为了让自己搞懂布隆过滤器的原理,Guava 中布隆过滤器的实现算是比较权威的,所以实际项目中我们不需要手动实现一个布隆过滤器。
首先我们需要在项目中引入 Guava 的依赖:
```java
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.0-jre</version>
</dependency>
```
实际使用如下:
我们创建了一个最多存放 最多 1500个整数的布隆过滤器,并且我们可以容忍误判的概率为百分之(0.01)
```java
// 创建布隆过滤器对象
BloomFilter<Integer> filter = BloomFilter.create(
Funnels.integerFunnel(),
1500,
0.01);
// 判断指定元素是否存在
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
// 将元素添加进布隆过滤器
filter.put(1);
filter.put(2);
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
```
在我们的示例中,当`mightContain()` 方法返回*true*时,我们可以99%确定该元素在过滤器中,当过滤器返回*false*时,我们可以100%确定该元素不存在于过滤器中。
**Guava 提供的布隆过滤器的实现还是很不错的(想要详细了解的可以看一下它的源码实现),但是它有一个重大的缺陷就是只能单机使用(另外,容量扩展也不容易),而现在互联网一般都是分布式的场景。为了解决这个问题,我们就需要用到 Redis 中的布隆过滤器了。**
### 6.Redis 中的布隆过滤器
#### 6.1介绍
Redis v4.0 之后有了 Module(模块/插件) 功能,Redis Modules 让 Redis 可以使用外部模块扩展其功能 。布隆过滤器就是其中的 Module。详情可以查看 Redis 官方对 Redis Modules 的介绍 :https://redis.io/modules。
另外,官网推荐了一个 RedisBloom 作为 Redis 布隆过滤器的 Module,地址:https://github.com/RedisBloom/RedisBloom。其他还有:
- redis-lua-scaling-bloom-filter (lua 脚本实现):https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter
- pyreBloom(Python中的快速Redis 布隆过滤器) :https://github.com/seomoz/pyreBloom
- ......
RedisBloom 提供了多种语言的客户端支持,包括:Python、Java、JavaScript 和 PHP。
#### 6.2使用Docker安装
如果我们需要体验 Redis 中的布隆过滤器非常简单,通过 Docker 就可以了!我们直接在 Google 搜索**docker redis bloomfilter** 然后在排除广告的第一条搜素结果就找到了我们想要的答案(这是我平常解决问题的一种方式,分享一下),具体地址:https://hub.docker.com/r/redislabs/rebloom/ (介绍的很详细 )。
**具体操作如下:**
```
➜ ~ docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest
➜ ~ docker exec -it redis-redisbloom bash
root@21396d02c252:/data# redis-cli
127.0.0.1:6379>
```
#### 6.3常用命令一览
> 注意: key:布隆过滤器的名称,item : 添加的元素。
1. **`BF.ADD `**:将元素添加到布隆过滤器中,如果该过滤器尚不存在,则创建该过滤器。格式:`BF.ADD {key} {item}`。
2. **`BF.MADD `** : 将一个或多个元素添加到“布隆过滤器”中,并创建一个尚不存在的过滤器。该命令的操作方式`BF.ADD`与之相同,只不过它允许多个输入并返回多个值。格式:`BF.MADD {key} {item} [item ...]` 。
3. **`BF.EXISTS` ** : 确定元素是否在布隆过滤器中存在。格式:`BF.EXISTS {key} {item}`。
4. **`BF.MEXISTS`** : 确定一个或者多个元素是否在布隆过滤器中存在格式:`BF.MEXISTS {key} {item} [item ...]`。
另外,`BF.RESERVE` 命令需要单独介绍一下:
这个命令的格式如下:
`BF.RESERVE {key} {error_rate} {capacity} [EXPANSION expansion] `。
下面简单介绍一下每个参数的具体含义:
1. key:布隆过滤器的名称
2. error_rate :误报的期望概率。这应该是介于0到1之间的十进制值。例如,对于期望的误报率0.1%(1000中为1),error_rate应该设置为0.001。该数字越接近零,则每个项目的内存消耗越大,并且每个操作的CPU使用率越高。
3. capacity: 过滤器的容量。当实际存储的元素个数超过这个值之后,性能将开始下降。实际的降级将取决于超出限制的程度。随着过滤器元素数量呈指数增长,性能将线性下降。
可选参数:
- expansion:如果创建了一个新的子过滤器,则其大小将是当前过滤器的大小乘以`expansion`。默认扩展值为2。这意味着每个后续子过滤器将是前一个子过滤器的两倍。
#### 6.4实际使用
```shell
127.0.0.1:6379> BF.ADD myFilter java
(integer) 1
127.0.0.1:6379> BF.ADD myFilter javaguide
(integer) 1
127.0.0.1:6379> BF.EXISTS myFilter java
(integer) 1
127.0.0.1:6379> BF.EXISTS myFilter javaguide
(integer) 1
127.0.0.1:6379> BF.EXISTS myFilter github
(integer) 0
```
# N皇后
[51. N皇后](https://leetcode-cn.com/problems/n-queens/)
### 题目描述
> n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
>

>
上图为 8 皇后问题的一种解法。
>
给定一个整数 n,返回所有不同的 n 皇后问题的解决方案。
>
每一种解法包含一个明确的 n 皇后问题的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。
示例:
```
输入: 4
输出: [
[".Q..", // 解法 1
"...Q",
"Q...",
"..Q."],
["..Q.", // 解法 2
"Q...",
"...Q",
".Q.."]
]
解释: 4 皇后问题存在两个不同的解法。
```
### 问题分析
约束条件为每个棋子所在的行、列、对角线都不能有另一个棋子。
使用一维数组表示一种解法,下标(index)表示行,值(value)表示该行的Q(皇后)在哪一列。
每行只存储一个元素,然后递归到下一行,这样就不用判断行了,只需要判断列和对角线。
### Solution1
当result[row] = column时,即row行的棋子在column列。
对于[0, row-1]的任意一行(i 行),若 row 行的棋子和 i 行的棋子在同一列,则有result[i] == column;
若 row 行的棋子和 i 行的棋子在同一对角线,等腰直角三角形两直角边相等,即 row - i == Math.abs(result[i] - column)
布尔类型变量 isValid 的作用是剪枝,减少不必要的递归。
```
public List<List<String>> solveNQueens(int n) {
// 下标代表行,值代表列。如result[0] = 3 表示第1行的Q在第3列
int[] result = new int[n];
List<List<String>> resultList = new LinkedList<>();
dfs(resultList, result, 0, n);
return resultList;
}
void dfs(List<List<String>> resultList, int[] result, int row, int n) {
// 递归终止条件
if (row == n) {
List<String> list = new LinkedList<>();
for (int x = 0; x < n; ++x) {
StringBuilder sb = new StringBuilder();
for (int y = 0; y < n; ++y)
sb.append(result[x] == y ? "Q" : ".");
list.add(sb.toString());
}
resultList.add(list);
return;
}
for (int column = 0; column < n; ++column) {
boolean isValid = true;
result[row] = column;
/*
* 逐行往下考察每一行。同列,result[i] == column
* 同对角线,row - i == Math.abs(result[i] - column)
*/
for (int i = row - 1; i >= 0; --i) {
if (result[i] == column || row - i == Math.abs(result[i] - column)) {
isValid = false;
break;
}
}
if (isValid) dfs(resultList, result, row + 1, n);
}
}
```
### Solution2
使用LinkedList表示一种解法,下标(index)表示行,值(value)表示该行的Q(皇后)在哪一列。
解法二和解法一的不同在于,相同列以及相同对角线的校验。
将对角线抽象成【一次函数】这个简单的数学模型,根据一次函数的截距是常量这一特性进行校验。
这里,我将右上-左下对角线,简称为“\”对角线;左上-右下对角线简称为“/”对角线。
“/”对角线斜率为1,对应方程为y = x + b,其中b为截距。
对于线上任意一点,均有y - x = b,即row - i = b;
定义一个布尔类型数组anti_diag,将b作为下标,当anti_diag[b] = true时,表示相应对角线上已经放置棋子。
但row - i有可能为负数,负数不能作为数组下标,row - i 的最小值为-n(当row = 0,i = n时),可以加上n作为数组下标,即将row -i + n 作为数组下标。
row - i + n 的最大值为 2n(当row = n,i = 0时),故anti_diag的容量设置为 2n 即可。

“\”对角线斜率为-1,对应方程为y = -x + b,其中b为截距。
对于线上任意一点,均有y + x = b,即row + i = b;
同理,定义数组main_diag,将b作为下标,当main_diag[row + i] = true时,表示相应对角线上已经放置棋子。
有了两个校验对角线的数组,再来定义一个用于校验列的数组cols,这个太简单啦,不解释。
**解法二时间复杂度为O(n!),在校验相同列和相同对角线时,引入三个布尔类型数组进行判断。相比解法一,少了一层循环,用空间换时间。**
```
List<List<String>> resultList = new LinkedList<>();
public List<List<String>> solveNQueens(int n) {
boolean[] cols = new boolean[n];
boolean[] main_diag = new boolean[2 * n];
boolean[] anti_diag = new boolean[2 * n];
LinkedList<Integer> result = new LinkedList<>();
dfs(result, 0, cols, main_diag, anti_diag, n);
return resultList;
}
void dfs(LinkedList<Integer> result, int row, boolean[] cols, boolean[] main_diag, boolean[] anti_diag, int n) {
if (row == n) {
List<String> list = new LinkedList<>();
for (int x = 0; x < n; ++x) {
StringBuilder sb = new StringBuilder();
for (int y = 0; y < n; ++y)
sb.append(result.get(x) == y ? "Q" : ".");
list.add(sb.toString());
}
resultList.add(list);
return;
}
for (int i = 0; i < n; ++i) {
if (cols[i] || main_diag[row + i] || anti_diag[row - i + n])
continue;
result.add(i);
cols[i] = true;
main_diag[row + i] = true;
anti_diag[row - i + n] = true;
dfs(result, row + 1, cols, main_diag, anti_diag, n);
result.removeLast();
cols[i] = false;
main_diag[row + i] = false;
anti_diag[row - i + n] = false;
}
}
```
# 网易 2018
下面三道编程题来自网易2018校招编程题,这三道应该来说是非常简单的编程题了,这些题目大家稍微有点编程和数学基础的话应该没什么问题。看答案之前一定要自己先想一下如果是自己做的话会怎么去做,然后再对照这我的答案看看,和你自己想的有什么区别?那一种方法更好?
## 问题
### 一 获得特定数量硬币问题
小易准备去魔法王国采购魔法神器,购买魔法神器需要使用魔法币,但是小易现在一枚魔法币都没有,但是小易有两台魔法机器可以通过投入x(x可以为0)个魔法币产生更多的魔法币。
魔法机器1:如果投入x个魔法币,魔法机器会将其变为2x+1个魔法币
魔法机器2:如果投入x个魔法币,魔法机器会将其变为2x+2个魔法币
小易采购魔法神器总共需要n个魔法币,所以小易只能通过两台魔法机器产生恰好n个魔法币,小易需要你帮他设计一个投入方案使他最后恰好拥有n个魔法币。
**输入描述:** 输入包括一行,包括一个正整数n(1 ≤ n ≤ 10^9),表示小易需要的魔法币数量。
**输出描述:** 输出一个字符串,每个字符表示该次小易选取投入的魔法机器。其中只包含字符'1'和'2'。
**输入例子1:** 10
**输出例子1:** 122
### 二 求“相反数”问题
为了得到一个数的"相反数",我们将这个数的数字顺序颠倒,然后再加上原先的数得到"相反数"。例如,为了得到1325的"相反数",首先我们将该数的数字顺序颠倒,我们得到5231,之后再加上原先的数,我们得到5231+1325=6556.如果颠倒之后的数字有前缀零,前缀零将会被忽略。例如n = 100, 颠倒之后是1.
**输入描述:** 输入包括一个整数n,(1 ≤ n ≤ 10^5)
**输出描述:** 输出一个整数,表示n的相反数
**输入例子1:** 1325
**输出例子1:** 6556
### 三 字符串碎片的平均长度
一个由小写字母组成的字符串可以看成一些同一字母的最大碎片组成的。例如,"aaabbaaac"是由下面碎片组成的:'aaa','bb','c'。牛牛现在给定一个字符串,请你帮助计算这个字符串的所有碎片的平均长度是多少。
**输入描述:** 输入包括一个字符串s,字符串s的长度length(1 ≤ length ≤ 50),s只含小写字母('a'-'z')
**输出描述:** 输出一个整数,表示所有碎片的平均长度,四舍五入保留两位小数。
**如样例所示:** s = "aaabbaaac"
所有碎片的平均长度 = (3 + 2 + 3 + 1) / 4 = 2.25
**输入例子1:** aaabbaaac
**输出例子1:** 2.25
## 答案
### 一 获得特定数量硬币问题
#### 分析:
作为该试卷的第一题,这道题应该只要思路正确就很简单了。
解题关键:明确魔法机器1只能产生奇数,魔法机器2只能产生偶数即可。我们从后往前一步一步推回去即可。
#### 示例代码
注意:由于用户的输入不确定性,一般是为了程序高可用性使需要将捕获用户输入异常然后友好提示用户输入类型错误并重新输入的。所以下面我给了两个版本,这两个版本都是正确的。这里只是给大家演示如何捕获输入类型异常,后面的题目中我给的代码没有异常处理的部分,参照下面两个示例代码,应该很容易添加。(PS:企业面试中没有明确就不用添加异常处理,当然你有的话也更好)
**不带输入异常处理判断的版本:**
```java
import java.util.Scanner;
public class Main2 {
// 解题关键:明确魔法机器1只能产生奇数,魔法机器2只能产生偶数即可。我们从后往前一步一步推回去即可。
public static void main(String[] args) {
System.out.println("请输入要获得的硬币数量:");
Scanner scanner = new Scanner(System.in);
int coincount = scanner.nextInt();
StringBuilder sb = new StringBuilder();
while (coincount >= 1) {
// 偶数的情况
if (coincount % 2 == 0) {
coincount = (coincount - 2) / 2;
sb.append("2");
// 奇数的情况
} else {
coincount = (coincount - 1) / 2;
sb.append("1");
}
}
// 输出反转后的字符串
System.out.println(sb.reverse());
}
}
```
**带输入异常处理判断的版本(当输入的不是整数的时候会提示重新输入):**
```java
import java.util.InputMismatchException;
import java.util.Scanner;
public class Main {
// 解题关键:明确魔法机器1只能产生奇数,魔法机器2只能产生偶数即可。我们从后往前一步一步推回去即可。
public static void main(String[] args) {
System.out.println("请输入要获得的硬币数量:");
Scanner scanner = new Scanner(System.in);
boolean flag = true;
while (flag) {
try {
int coincount = scanner.nextInt();
StringBuilder sb = new StringBuilder();
while (coincount >= 1) {
// 偶数的情况
if (coincount % 2 == 0) {
coincount = (coincount - 2) / 2;
sb.append("2");
// 奇数的情况
} else {
coincount = (coincount - 1) / 2;
sb.append("1");
}
}
// 输出反转后的字符串
System.out.println(sb.reverse());
flag=false;//程序结束
} catch (InputMismatchException e) {
System.out.println("输入数据类型不匹配,请您重新输入:");
scanner.nextLine();
continue;
}
}
}
}
```
### 二 求“相反数”问题
#### 分析:
解决本道题有几种不同的方法,但是最快速的方法就是利用reverse()方法反转字符串然后再将字符串转换成int类型的整数,这个方法是快速解决本题关键。我们先来回顾一下下面两个知识点:
**1)String转int;**
在 Java 中要将 String 类型转化为 int 类型时,需要使用 Integer 类中的 parseInt() 方法或者 valueOf() 方法进行转换.
```java
String str = "123";
int a = Integer.parseInt(str);
```
或
```java
String str = "123";
int a = Integer.valueOf(str).intValue();
```
**2)next()和nextLine()的区别**
在Java中输入字符串有两种方法,就是next()和nextLine().两者的区别就是:nextLine()的输入是碰到回车就终止输入,而next()方法是碰到空格,回车,Tab键都会被视为终止符。所以next()不会得到带空格的字符串,而nextLine()可以得到带空格的字符串。
#### 示例代码:
```java
import java.util.Scanner;
/**
* 本题关键:①String转int;②next()和nextLine()的区别
*/
public class Main {
public static void main(String[] args) {
System.out.println("请输入一个整数:");
Scanner scanner = new Scanner(System.in);
String s=scanner.next();
//将字符串转换成数字
int number1=Integer.parseInt(s);
//将字符串倒序后转换成数字
//因为Integer.parseInt()的参数类型必须是字符串所以必须加上toString()
int number2=Integer.parseInt(new StringBuilder(s).reverse().toString());
System.out.println(number1+number2);
}
}
```
### 三 字符串碎片的平均长度
#### 分析:
这道题的意思也就是要求:(字符串的总长度)/(相同字母团构成的字符串的个数)。
这样就很简单了,就变成了字符串的字符之间的比较。如果需要比较字符串的字符的话,我们可以利用charAt(i)方法:取出特定位置的字符与后一个字符比较,或者利用toCharArray()方法将字符串转换成字符数组采用同样的方法做比较。
#### 示例代码
**利用charAt(i)方法:**
```java
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
while (sc.hasNext()) {
String s = sc.next();
//个数至少为一个
float count = 1;
for (int i = 0; i < s.length() - 1; i++) {
if (s.charAt(i) != s.charAt(i + 1)) {
count++;
}
}
System.out.println(s.length() / count);
}
}
}
```
**利用toCharArray()方法:**
```java
import java.util.Scanner;
public class Main2 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
while (sc.hasNext()) {
String s = sc.next();
//个数至少为一个
float count = 1;
char [] stringArr = s.toCharArray();
for (int i = 0; i < stringArr.length - 1; i++) {
if (stringArr[i] != stringArr[i + 1]) {
count++;
}
}
System.out.println(s.length() / count);
}
}
}
```
<!-- MarkdownTOC -->
- [说明](#说明)
- [1. KMP 算法](#1-kmp-算法)
- [2. 替换空格](#2-替换空格)
- [3. 最长公共前缀](#3-最长公共前缀)
- [4. 回文串](#4-回文串)
- [4.1. 最长回文串](#41-最长回文串)
- [4.2. 验证回文串](#42-验证回文串)
- [4.3. 最长回文子串](#43-最长回文子串)
- [4.4. 最长回文子序列](#44-最长回文子序列)
- [5. 括号匹配深度](#5-括号匹配深度)
- [6. 把字符串转换成整数](#6-把字符串转换成整数)
<!-- /MarkdownTOC -->
## 说明
- 本文作者:wwwxmu
- 原文地址:https://www.weiweiblog.cn/13string/
- 作者的博客站点:https://www.weiweiblog.cn/ (推荐哦!)
考虑到篇幅问题,我会分两次更新这个内容。本篇文章只是原文的一部分,我在原文的基础上增加了部分内容以及修改了部分代码和注释。另外,我增加了爱奇艺 2018 秋招 Java:`求给定合法括号序列的深度` 这道题。所有代码均编译成功,并带有注释,欢迎各位享用!
## 1. KMP 算法
谈到字符串问题,不得不提的就是 KMP 算法,它是用来解决字符串查找的问题,可以在一个字符串(S)中查找一个子串(W)出现的位置。KMP 算法把字符匹配的时间复杂度缩小到 O(m+n) ,而空间复杂度也只有O(m)。因为“暴力搜索”的方法会反复回溯主串,导致效率低下,而KMP算法可以利用已经部分匹配这个有效信息,保持主串上的指针不回溯,通过修改子串的指针,让模式串尽量地移动到有效的位置。
具体算法细节请参考:
- **字符串匹配的KMP算法:** http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
- **从头到尾彻底理解KMP:** https://blog.csdn.net/v_july_v/article/details/7041827
- **如何更好的理解和掌握 KMP 算法?:** https://www.zhihu.com/question/21923021
- **KMP 算法详细解析:** https://blog.sengxian.com/algorithms/kmp
- **图解 KMP 算法:** http://blog.jobbole.com/76611/
- **汪都能听懂的KMP字符串匹配算法【双语字幕】:** https://www.bilibili.com/video/av3246487/?from=search&seid=17173603269940723925
- **KMP字符串匹配算法1:** https://www.bilibili.com/video/av11866460?from=search&seid=12730654434238709250
**除此之外,再来了解一下BM算法!**
> BM算法也是一种精确字符串匹配算法,它采用从右向左比较的方法,同时应用到了两种启发式规则,即坏字符规则 和好后缀规则 ,来决定向右跳跃的距离。基本思路就是从右往左进行字符匹配,遇到不匹配的字符后从坏字符表和好后缀表找一个最大的右移值,将模式串右移继续匹配。
《字符串匹配的KMP算法》:http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
## 2. 替换空格
> 剑指offer:请实现一个函数,将一个字符串中的每个空格替换成“%20”。例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy。
这里我提供了两种方法:①常规方法;②利用 API 解决。
```java
//https://www.weiweiblog.cn/replacespace/
public class Solution {
/**
* 第一种方法:常规方法。利用String.charAt(i)以及String.valueOf(char).equals(" "
* )遍历字符串并判断元素是否为空格。是则替换为"%20",否则不替换
*/
public static String replaceSpace(StringBuffer str) {
int length = str.length();
// System.out.println("length=" + length);
StringBuffer result = new StringBuffer();
for (int i = 0; i < length; i++) {
char b = str.charAt(i);
if (String.valueOf(b).equals(" ")) {
result.append("%20");
} else {
result.append(b);
}
}
return result.toString();
}
/**
* 第二种方法:利用API替换掉所用空格,一行代码解决问题
*/
public static String replaceSpace2(StringBuffer str) {
return str.toString().replaceAll("\\s", "%20");
}
}
```
## 3. 最长公共前缀
> Leetcode: 编写一个函数来查找字符串数组中的最长公共前缀。如果不存在公共前缀,返回空字符串 ""。
示例 1:
```
输入: ["flower","flow","flight"]
输出: "fl"
```
示例 2:
```
输入: ["dog","racecar","car"]
输出: ""
解释: 输入不存在公共前缀。
```
思路很简单!先利用Arrays.sort(strs)为数组排序,再将数组第一个元素和最后一个元素的字符从前往后对比即可!
```java
public class Main {
public static String replaceSpace(String[] strs) {
// 如果检查值不合法及就返回空串
if (!checkStrs(strs)) {
return "";
}
// 数组长度
int len = strs.length;
// 用于保存结果
StringBuilder res = new StringBuilder();
// 给字符串数组的元素按照升序排序(包含数字的话,数字会排在前面)
Arrays.sort(strs);
int m = strs[0].length();
int n = strs[len - 1].length();
int num = Math.min(m, n);
for (int i = 0; i < num; i++) {
if (strs[0].charAt(i) == strs[len - 1].charAt(i)) {
res.append(strs[0].charAt(i));
} else
break;
}
return res.toString();
}
private static boolean chechStrs(String[] strs) {
boolean flag = false;
if (strs != null) {
// 遍历strs检查元素值
for (int i = 0; i < strs.length; i++) {
if (strs[i] != null && strs[i].length() != 0) {
flag = true;
} else {
flag = false;
break;
}
}
}
return flag;
}
// 测试
public static void main(String[] args) {
String[] strs = { "customer", "car", "cat" };
// String[] strs = { "customer", "car", null };//空串
// String[] strs = {};//空串
// String[] strs = null;//空串
System.out.println(Main.replaceSpace(strs));// c
}
}
```
## 4. 回文串
### 4.1. 最长回文串
> LeetCode: 给定一个包含大写字母和小写字母的字符串,找到通过这些字母构造成的最长的回文串。在构造过程中,请注意区分大小写。比如`"Aa"`不能当做一个回文字符串。注
意:假设字符串的长度不会超过 1010。
> 回文串:“回文串”是一个正读和反读都一样的字符串,比如“level”或者“noon”等等就是回文串。——百度百科 地址:https://baike.baidu.com/item/%E5%9B%9E%E6%96%87%E4%B8%B2/1274921?fr=aladdin
示例 1:
```
输入:
"abccccdd"
输出:
7
解释:
我们可以构造的最长的回文串是"dccaccd", 它的长度是 7。
```
我们上面已经知道了什么是回文串?现在我们考虑一下可以构成回文串的两种情况:
- 字符出现次数为双数的组合
- 字符出现次数为双数的组合+一个只出现一次的字符
统计字符出现的次数即可,双数才能构成回文。因为允许中间一个数单独出现,比如“abcba”,所以如果最后有字母落单,总长度可以加 1。首先将字符串转变为字符数组。然后遍历该数组,判断对应字符是否在hashset中,如果不在就加进去,如果在就让count++,然后移除该字符!这样就能找到出现次数为双数的字符个数。
```java
//https://leetcode-cn.com/problems/longest-palindrome/description/
class Solution {
public int longestPalindrome(String s) {
if (s.length() == 0)
return 0;
// 用于存放字符
HashSet<Character> hashset = new HashSet<Character>();
char[] chars = s.toCharArray();
int count = 0;
for (int i = 0; i < chars.length; i++) {
if (!hashset.contains(chars[i])) {// 如果hashset没有该字符就保存进去
hashset.add(chars[i]);
} else {// 如果有,就让count++(说明找到了一个成对的字符),然后把该字符移除
hashset.remove(chars[i]);
count++;
}
}
return hashset.isEmpty() ? count * 2 : count * 2 + 1;
}
}
```
### 4.2. 验证回文串
> LeetCode: 给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写。 说明:本题中,我们将空字符串定义为有效的回文串。
示例 1:
```
输入: "A man, a plan, a canal: Panama"
输出: true
```
示例 2:
```
输入: "race a car"
输出: false
```
```java
//https://leetcode-cn.com/problems/valid-palindrome/description/
class Solution {
public boolean isPalindrome(String s) {
if (s.length() == 0)
return true;
int l = 0, r = s.length() - 1;
while (l < r) {
// 从头和尾开始向中间遍历
if (!Character.isLetterOrDigit(s.charAt(l))) {// 字符不是字母和数字的情况
l++;
} else if (!Character.isLetterOrDigit(s.charAt(r))) {// 字符不是字母和数字的情况
r--;
} else {
// 判断二者是否相等
if (Character.toLowerCase(s.charAt(l)) != Character.toLowerCase(s.charAt(r)))
return false;
l++;
r--;
}
}
return true;
}
}
```
### 4.3. 最长回文子串
> Leetcode: LeetCode: 最长回文子串 给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为1000。
示例 1:
```
输入: "babad"
输出: "bab"
注意: "aba"也是一个有效答案。
```
示例 2:
```
输入: "cbbd"
输出: "bb"
```
以某个元素为中心,分别计算偶数长度的回文最大长度和奇数长度的回文最大长度。给大家大致花了个草图,不要嫌弃!

```java
//https://leetcode-cn.com/problems/longest-palindromic-substring/description/
class Solution {
private int index, len;
public String longestPalindrome(String s) {
if (s.length() < 2)
return s;
for (int i = 0; i < s.length() - 1; i++) {
PalindromeHelper(s, i, i);
PalindromeHelper(s, i, i + 1);
}
return s.substring(index, index + len);
}
public void PalindromeHelper(String s, int l, int r) {
while (l >= 0 && r < s.length() && s.charAt(l) == s.charAt(r)) {
l--;
r++;
}
if (len < r - l - 1) {
index = l + 1;
len = r - l - 1;
}
}
}
```
### 4.4. 最长回文子序列
> LeetCode: 最长回文子序列
给定一个字符串s,找到其中最长的回文子序列。可以假设s的最大长度为1000。
**最长回文子序列和上一题最长回文子串的区别是,子串是字符串中连续的一个序列,而子序列是字符串中保持相对位置的字符序列,例如,"bbbb"可以是字符串"bbbab"的子序列但不是子串。**
给定一个字符串s,找到其中最长的回文子序列。可以假设s的最大长度为1000。
示例 1:
```
输入:
"bbbab"
输出:
4
```
一个可能的最长回文子序列为 "bbbb"。
示例 2:
```
输入:
"cbbd"
输出:
2
```
一个可能的最长回文子序列为 "bb"。
**动态规划:** dp[i][j] = dp[i+1][j-1] + 2 if s.charAt(i) == s.charAt(j) otherwise, dp[i][j] = Math.max(dp[i+1][j], dp[i][j-1])
```java
class Solution {
public int longestPalindromeSubseq(String s) {
int len = s.length();
int [][] dp = new int[len][len];
for(int i = len - 1; i>=0; i--){
dp[i][i] = 1;
for(int j = i+1; j < len; j++){
if(s.charAt(i) == s.charAt(j))
dp[i][j] = dp[i+1][j-1] + 2;
else
dp[i][j] = Math.max(dp[i+1][j], dp[i][j-1]);
}
}
return dp[0][len-1];
}
}
```
## 5. 括号匹配深度
> 爱奇艺 2018 秋招 Java:
>一个合法的括号匹配序列有以下定义:
>1. 空串""是一个合法的括号匹配序列
>2. 如果"X"和"Y"都是合法的括号匹配序列,"XY"也是一个合法的括号匹配序列
>3. 如果"X"是一个合法的括号匹配序列,那么"(X)"也是一个合法的括号匹配序列
>4. 每个合法的括号序列都可以由以上规则生成。
> 例如: "","()","()()","((()))"都是合法的括号序列
>对于一个合法的括号序列我们又有以下定义它的深度:
>1. 空串""的深度是0
>2. 如果字符串"X"的深度是x,字符串"Y"的深度是y,那么字符串"XY"的深度为max(x,y)
>3. 如果"X"的深度是x,那么字符串"(X)"的深度是x+1
> 例如: "()()()"的深度是1,"((()))"的深度是3。牛牛现在给你一个合法的括号序列,需要你计算出其深度。
```
输入描述:
输入包括一个合法的括号序列s,s长度length(2 ≤ length ≤ 50),序列中只包含'('和')'。
输出描述:
输出一个正整数,即这个序列的深度。
```
示例:
```
输入:
(())
输出:
2
```
思路草图:

代码如下:
```java
import java.util.Scanner;
/**
* https://www.nowcoder.com/test/8246651/summary
*
* @author Snailclimb
* @date 2018年9月6日
* @Description: TODO 求给定合法括号序列的深度
*/
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
String s = sc.nextLine();
int cnt = 0, max = 0, i;
for (i = 0; i < s.length(); ++i) {
if (s.charAt(i) == '(')
cnt++;
else
cnt--;
max = Math.max(max, cnt);
}
sc.close();
System.out.println(max);
}
}
```
## 6. 把字符串转换成整数
> 剑指offer: 将一个字符串转换成一个整数(实现Integer.valueOf(string)的功能,但是string不符合数字要求时返回0),要求不能使用字符串转换整数的库函数。 数值为0或者字符串不是一个合法的数值则返回0。
```java
//https://www.weiweiblog.cn/strtoint/
public class Main {
public static int StrToInt(String str) {
if (str.length() == 0)
return 0;
char[] chars = str.toCharArray();
// 判断是否存在符号位
int flag = 0;
if (chars[0] == '+')
flag = 1;
else if (chars[0] == '-')
flag = 2;
int start = flag > 0 ? 1 : 0;
int res = 0;// 保存结果
for (int i = start; i < chars.length; i++) {
if (Character.isDigit(chars[i])) {// 调用Character.isDigit(char)方法判断是否是数字,是返回True,否则False
int temp = chars[i] - '0';
res = res * 10 + temp;
} else {
return 0;
}
}
return flag != 2 ? res : -res;
}
public static void main(String[] args) {
// TODO Auto-generated method stub
String s = "-12312312";
System.out.println("使用库函数转换:" + Integer.valueOf(s));
int res = Main.StrToInt(s);
System.out.println("使用自己写的方法转换:" + res);
}
}
```
<!-- MarkdownTOC -->
- [1. 两数相加](#1-两数相加)
- [题目描述](#题目描述)
- [问题分析](#问题分析)
- [Solution](#solution)
- [2. 翻转链表](#2-翻转链表)
- [题目描述](#题目描述-1)
- [问题分析](#问题分析-1)
- [Solution](#solution-1)
- [3. 链表中倒数第k个节点](#3-链表中倒数第k个节点)
- [题目描述](#题目描述-2)
- [问题分析](#问题分析-2)
- [Solution](#solution-2)
- [4. 删除链表的倒数第N个节点](#4-删除链表的倒数第n个节点)
- [问题分析](#问题分析-3)
- [Solution](#solution-3)
- [5. 合并两个排序的链表](#5-合并两个排序的链表)
- [题目描述](#题目描述-3)
- [问题分析](#问题分析-4)
- [Solution](#solution-4)
<!-- /MarkdownTOC -->
# 1. 两数相加
### 题目描述
> Leetcode:给定两个非空链表来表示两个非负整数。位数按照逆序方式存储,它们的每个节点只存储单个数字。将两数相加返回一个新的链表。
>
>你可以假设除了数字 0 之外,这两个数字都不会以零开头。
示例:
```
输入:(2 -> 4 -> 3) + (5 -> 6 -> 4)
输出:7 -> 0 -> 8
原因:342 + 465 = 807
```
### 问题分析
Leetcode官方详细解答地址:
https://leetcode-cn.com/problems/add-two-numbers/solution/
> 要对头结点进行操作时,考虑创建哑节点dummy,使用dummy->next表示真正的头节点。这样可以避免处理头节点为空的边界问题。
我们使用变量来跟踪进位,并从包含最低有效位的表头开始模拟逐
位相加的过程。
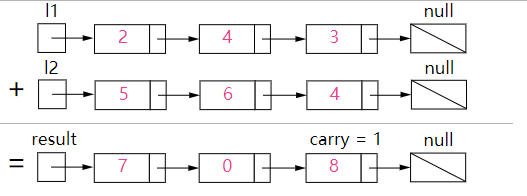
### Solution
**我们首先从最低有效位也就是列表 l1和 l2 的表头开始相加。注意需要考虑到进位的情况!**
```java
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
//https://leetcode-cn.com/problems/add-two-numbers/description/
class Solution {
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
ListNode dummyHead = new ListNode(0);
ListNode p = l1, q = l2, curr = dummyHead;
//carry 表示进位数
int carry = 0;
while (p != null || q != null) {
int x = (p != null) ? p.val : 0;
int y = (q != null) ? q.val : 0;
int sum = carry + x + y;
//进位数
carry = sum / 10;
//新节点的数值为sum % 10
curr.next = new ListNode(sum % 10);
curr = curr.next;
if (p != null) p = p.next;
if (q != null) q = q.next;
}
if (carry > 0) {
curr.next = new ListNode(carry);
}
return dummyHead.next;
}
}
```
# 2. 翻转链表
### 题目描述
> 剑指 offer:输入一个链表,反转链表后,输出链表的所有元素。
### 问题分析
这道算法题,说直白点就是:如何让后一个节点指向前一个节点!在下面的代码中定义了一个 next 节点,该节点主要是保存要反转到头的那个节点,防止链表 “断裂”。
### Solution
```java
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}
```
```java
/**
*
* @author Snailclimb
* @date 2018年9月19日
* @Description: TODO
*/
public class Solution {
public ListNode ReverseList(ListNode head) {
ListNode next = null;
ListNode pre = null;
while (head != null) {
// 保存要反转到头的那个节点
next = head.next;
// 要反转的那个节点指向已经反转的上一个节点(备注:第一次反转的时候会指向null)
head.next = pre;
// 上一个已经反转到头部的节点
pre = head;
// 一直向链表尾走
head = next;
}
return pre;
}
}
```
测试方法:
```java
public static void main(String[] args) {
ListNode a = new ListNode(1);
ListNode b = new ListNode(2);
ListNode c = new ListNode(3);
ListNode d = new ListNode(4);
ListNode e = new ListNode(5);
a.next = b;
b.next = c;
c.next = d;
d.next = e;
new Solution().ReverseList(a);
while (e != null) {
System.out.println(e.val);
e = e.next;
}
}
```
输出:
```
5
4
3
2
1
```
# 3. 链表中倒数第k个节点
### 题目描述
> 剑指offer: 输入一个链表,输出该链表中倒数第k个结点。
### 问题分析
> **链表中倒数第k个节点也就是正数第(L-K+1)个节点,知道了只一点,这一题基本就没问题!**
首先两个节点/指针,一个节点 node1 先开始跑,指针 node1 跑到 k-1 个节点后,另一个节点 node2 开始跑,当 node1 跑到最后时,node2 所指的节点就是倒数第k个节点也就是正数第(L-K+1)个节点。
### Solution
```java
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}*/
// 时间复杂度O(n),一次遍历即可
// https://www.nowcoder.com/practice/529d3ae5a407492994ad2a246518148a?tpId=13&tqId=11167&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking
public class Solution {
public ListNode FindKthToTail(ListNode head, int k) {
// 如果链表为空或者k小于等于0
if (head == null || k <= 0) {
return null;
}
// 声明两个指向头结点的节点
ListNode node1 = head, node2 = head;
// 记录节点的个数
int count = 0;
// 记录k值,后面要使用
int index = k;
// p指针先跑,并且记录节点数,当node1节点跑了k-1个节点后,node2节点开始跑,
// 当node1节点跑到最后时,node2节点所指的节点就是倒数第k个节点
while (node1 != null) {
node1 = node1.next;
count++;
if (k < 1) {
node2 = node2.next;
}
k--;
}
// 如果节点个数小于所求的倒数第k个节点,则返回空
if (count < index)
return null;
return node2;
}
}
```
# 4. 删除链表的倒数第N个节点
> Leetcode:给定一个链表,删除链表的倒数第 n 个节点,并且返回链表的头结点。
**示例:**
```
给定一个链表: 1->2->3->4->5, 和 n = 2.
当删除了倒数第二个节点后,链表变为 1->2->3->5.
```
**说明:**
给定的 n 保证是有效的。
**进阶:**
你能尝试使用一趟扫描实现吗?
该题在 leetcode 上有详细解答,具体可参考 Leetcode.
### 问题分析
我们注意到这个问题可以容易地简化成另一个问题:删除从列表开头数起的第 (L - n + 1)个结点,其中 L是列表的长度。只要我们找到列表的长度 L,这个问题就很容易解决。
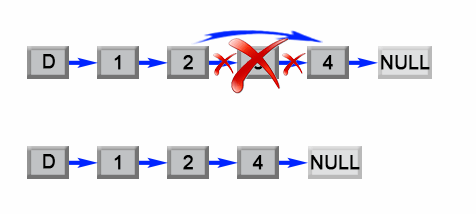
### Solution
**两次遍历法**
首先我们将添加一个 **哑结点** 作为辅助,该结点位于列表头部。哑结点用来简化某些极端情况,例如列表中只含有一个结点,或需要删除列表的头部。在第一次遍历中,我们找出列表的长度 L。然后设置一个指向哑结点的指针,并移动它遍历列表,直至它到达第 (L - n) 个结点那里。**我们把第 (L - n)个结点的 next 指针重新链接至第 (L - n + 2)个结点,完成这个算法。**
```java
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
// https://leetcode-cn.com/problems/remove-nth-node-from-end-of-list/description/
public class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
// 哑结点,哑结点用来简化某些极端情况,例如列表中只含有一个结点,或需要删除列表的头部
ListNode dummy = new ListNode(0);
// 哑结点指向头结点
dummy.next = head;
// 保存链表长度
int length = 0;
ListNode len = head;
while (len != null) {
length++;
len = len.next;
}
length = length - n;
ListNode target = dummy;
// 找到 L-n 位置的节点
while (length > 0) {
target = target.next;
length--;
}
// 把第 (L - n)个结点的 next 指针重新链接至第 (L - n + 2)个结点
target.next = target.next.next;
return dummy.next;
}
}
```
**复杂度分析:**
- **时间复杂度 O(L)** :该算法对列表进行了两次遍历,首先计算了列表的长度 LL 其次找到第 (L - n)(L−n) 个结点。 操作执行了 2L-n2L−n 步,时间复杂度为 O(L)O(L)。
- **空间复杂度 O(1)** :我们只用了常量级的额外空间。
**进阶——一次遍历法:**
> **链表中倒数第N个节点也就是正数第(L-N+1)个节点。
其实这种方法就和我们上面第四题找“链表中倒数第k个节点”所用的思想是一样的。**基本思路就是:** 定义两个节点 node1、node2;node1 节点先跑,node1节点 跑到第 n+1 个节点的时候,node2 节点开始跑.当node1 节点跑到最后一个节点时,node2 节点所在的位置就是第 (L-n ) 个节点(L代表总链表长度,也就是倒数第 n+1 个节点)
```java
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
public class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
ListNode dummy = new ListNode(0);
dummy.next = head;
// 声明两个指向头结点的节点
ListNode node1 = dummy, node2 = dummy;
// node1 节点先跑,node1节点 跑到第 n 个节点的时候,node2 节点开始跑
// 当node1 节点跑到最后一个节点时,node2 节点所在的位置就是第 (L-n ) 个节点,也就是倒数第 n+1(L代表总链表长度)
while (node1 != null) {
node1 = node1.next;
if (n < 1 && node1 != null) {
node2 = node2.next;
}
n--;
}
node2.next = node2.next.next;
return dummy.next;
}
}
```
# 5. 合并两个排序的链表
### 题目描述
> 剑指offer:输入两个单调递增的链表,输出两个链表合成后的链表,当然我们需要合成后的链表满足单调不减规则。
### 问题分析
我们可以这样分析:
1. 假设我们有两个链表 A,B;
2. A的头节点A1的值与B的头结点B1的值比较,假设A1小,则A1为头节点;
3. A2再和B1比较,假设B1小,则,A1指向B1;
4. A2再和B2比较
就这样循环往复就行了,应该还算好理解。
考虑通过递归的方式实现!
### Solution
**递归版本:**
```java
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}*/
//https://www.nowcoder.com/practice/d8b6b4358f774294a89de2a6ac4d9337?tpId=13&tqId=11169&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking
public class Solution {
public ListNode Merge(ListNode list1,ListNode list2) {
if(list1 == null){
return list2;
}
if(list2 == null){
return list1;
}
if(list1.val <= list2.val){
list1.next = Merge(list1.next, list2);
return list1;
}else{
list2.next = Merge(list1, list2.next);
return list2;
}
}
}
```
### 一 斐波那契数列
#### **题目描述:**
大家都知道斐波那契数列,现在要求输入一个整数n,请你输出斐波那契数列的第n项。
n<=39
#### **问题分析:**
可以肯定的是这一题通过递归的方式是肯定能做出来,但是这样会有一个很大的问题,那就是递归大量的重复计算会导致内存溢出。另外可以使用迭代法,用fn1和fn2保存计算过程中的结果,并复用起来。下面我会把两个方法示例代码都给出来并给出两个方法的运行时间对比。
#### **示例代码:**
**采用迭代法:**
```java
int Fibonacci(int number) {
if (number <= 0) {
return 0;
}
if (number == 1 || number == 2) {
return 1;
}
int first = 1, second = 1, third = 0;
for (int i = 3; i <= number; i++) {
third = first + second;
first = second;
second = third;
}
return third;
}
```
**采用递归:**
```java
public int Fibonacci(int n) {
if (n <= 0) {
return 0;
}
if (n == 1||n==2) {
return 1;
}
return Fibonacci(n - 2) + Fibonacci(n - 1);
}
```
#### **运行时间对比:**
假设n为40我们分别使用迭代法和递归法计算,计算结果如下:
1. 迭代法

2. 递归法

### 二 跳台阶问题
#### **题目描述:**
一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
#### **问题分析:**
**正常分析法:**
a.如果两种跳法,1阶或者2阶,那么假定第一次跳的是一阶,那么剩下的是n-1个台阶,跳法是f(n-1);
b.假定第一次跳的是2阶,那么剩下的是n-2个台阶,跳法是f(n-2)
c.由a,b假设可以得出总跳法为: f(n) = f(n-1) + f(n-2)
d.然后通过实际的情况可以得出:只有一阶的时候 f(1) = 1 ,只有两阶的时候可以有 f(2) = 2
**找规律分析法:**
f(1) = 1, f(2) = 2, f(3) = 3, f(4) = 5, 可以总结出f(n) = f(n-1) + f(n-2)的规律。
但是为什么会出现这样的规律呢?假设现在6个台阶,我们可以从第5跳一步到6,这样的话有多少种方案跳到5就有多少种方案跳到6,另外我们也可以从4跳两步跳到6,跳到4有多少种方案的话,就有多少种方案跳到6,其他的不能从3跳到6什么的啦,所以最后就是f(6) = f(5) + f(4);这样子也很好理解变态跳台阶的问题了。
**所以这道题其实就是斐波那契数列的问题。**
代码只需要在上一题的代码稍做修改即可。和上一题唯一不同的就是这一题的初始元素变为 1 2 3 5 8.....而上一题为1 1 2 3 5 .......。另外这一题也可以用递归做,但是递归效率太低,所以我这里只给出了迭代方式的代码。
#### **示例代码:**
```java
int jumpFloor(int number) {
if (number <= 0) {
return 0;
}
if (number == 1) {
return 1;
}
if (number == 2) {
return 2;
}
int first = 1, second = 2, third = 0;
for (int i = 3; i <= number; i++) {
third = first + second;
first = second;
second = third;
}
return third;
}
```
### 三 变态跳台阶问题
#### **题目描述:**
一只青蛙一次可以跳上1级台阶,也可以跳上2级……它也可以跳上n级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
#### **问题分析:**
假设n>=2,第一步有n种跳法:跳1级、跳2级、到跳n级
跳1级,剩下n-1级,则剩下跳法是f(n-1)
跳2级,剩下n-2级,则剩下跳法是f(n-2)
......
跳n-1级,剩下1级,则剩下跳法是f(1)
跳n级,剩下0级,则剩下跳法是f(0)
所以在n>=2的情况下:
f(n)=f(n-1)+f(n-2)+...+f(1)
因为f(n-1)=f(n-2)+f(n-3)+...+f(1)
所以f(n)=2*f(n-1) 又f(1)=1,所以可得**f(n)=2^(number-1)**
#### **示例代码:**
```java
int JumpFloorII(int number) {
return 1 << --number;//2^(number-1)用位移操作进行,更快
}
```
#### **补充:**
**java中有三种移位运算符:**
1. “<<” : **左移运算符**,等同于乘2的n次方
2. “>>”: **右移运算符**,等同于除2的n次方
3. “>>>” **无符号右移运算符**,不管移动前最高位是0还是1,右移后左侧产生的空位部分都以0来填充。与>>类似。
例:
int a = 16;
int b = a << 2;//左移2,等同于16 * 2的2次方,也就是16 * 4
int c = a >> 2;//右移2,等同于16 / 2的2次方,也就是16 / 4
### 四 二维数组查找
#### **题目描述:**
在一个二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
#### **问题解析:**
这一道题还是比较简单的,我们需要考虑的是如何做,效率最快。这里有一种很好理解的思路:
> 矩阵是有序的,从左下角来看,向上数字递减,向右数字递增,
> 因此从左下角开始查找,当要查找数字比左下角数字大时。右移
> 要查找数字比左下角数字小时,上移。这样找的速度最快。
#### **示例代码:**
```java
public boolean Find(int target, int [][] array) {
//基本思路从左下角开始找,这样速度最快
int row = array.length-1;//行
int column = 0;//列
//当行数大于0,当前列数小于总列数时循环条件成立
while((row >= 0)&& (column< array[0].length)){
if(array[row][column] > target){
row--;
}else if(array[row][column] < target){
column++;
}else{
return true;
}
}
return false;
}
```
### 五 替换空格
#### **题目描述:**
请实现一个函数,将一个字符串中的空格替换成“%20”。例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy。
#### **问题分析:**
这道题不难,我们可以通过循环判断字符串的字符是否为空格,是的话就利用append()方法添加追加“%20”,否则还是追加原字符。
或者最简单的方法就是利用: replaceAll(String regex,String replacement)方法了,一行代码就可以解决。
#### **示例代码:**
**常规做法:**
```java
public String replaceSpace(StringBuffer str) {
StringBuffer out=new StringBuffer();
for (int i = 0; i < str.toString().length(); i++) {
char b=str.charAt(i);
if(String.valueOf(b).equals(" ")){
out.append("%20");
}else{
out.append(b);
}
}
return out.toString();
}
```
**一行代码解决:**
```java
public String replaceSpace(StringBuffer str) {
//return str.toString().replaceAll(" ", "%20");
//public String replaceAll(String regex,String replacement)
//用给定的替换替换与给定的regular expression匹配的此字符串的每个子字符串。
//\ 转义字符. 如果你要使用 "\" 本身, 则应该使用 "\\". String类型中的空格用“\s”表示,所以我这里猜测"\\s"就是代表空格的意思
return str.toString().replaceAll("\\s", "%20");
}
```
### 六 数值的整数次方
#### **题目描述:**
给定一个double类型的浮点数base和int类型的整数exponent。求base的exponent次方。
#### **问题解析:**
这道题算是比较麻烦和难一点的一个了。我这里采用的是**二分幂**思想,当然也可以采用**快速幂**。
更具剑指offer书中细节,该题的解题思路如下:
1.当底数为0且指数<0时,会出现对0求倒数的情况,需进行错误处理,设置一个全局变量;
2.判断底数是否等于0,由于base为double型,所以不能直接用==判断
3.优化求幂函数(二分幂)。
当n为偶数,a^n =(a^n/2)*(a^n/2);
当n为奇数,a^n = a^[(n-1)/2] * a^[(n-1)/2] * a。时间复杂度O(logn)
**时间复杂度**:O(logn)
#### **示例代码:**
```java
public class Solution {
boolean invalidInput=false;
public double Power(double base, int exponent) {
//如果底数等于0并且指数小于0
//由于base为double型,不能直接用==判断
if(equal(base,0.0)&&exponent<0){
invalidInput=true;
return 0.0;
}
int absexponent=exponent;
//如果指数小于0,将指数转正
if(exponent<0)
absexponent=-exponent;
//getPower方法求出base的exponent次方。
double res=getPower(base,absexponent);
//如果指数小于0,所得结果为上面求的结果的倒数
if(exponent<0)
res=1.0/res;
return res;
}
//比较两个double型变量是否相等的方法
boolean equal(double num1,double num2){
if(num1-num2>-0.000001&&num1-num2<0.000001)
return true;
else
return false;
}
//求出b的e次方的方法
double getPower(double b,int e){
//如果指数为0,返回1
if(e==0)
return 1.0;
//如果指数为1,返回b
if(e==1)
return b;
//e>>1相等于e/2,这里就是求a^n =(a^n/2)*(a^n/2)
double result=getPower(b,e>>1);
result*=result;
//如果指数n为奇数,则要再乘一次底数base
if((e&1)==1)
result*=b;
return result;
}
}
```
当然这一题也可以采用笨方法:累乘。不过这种方法的时间复杂度为O(n),这样没有前一种方法效率高。
```java
// 使用累乘
public double powerAnother(double base, int exponent) {
double result = 1.0;
for (int i = 0; i < Math.abs(exponent); i++) {
result *= base;
}
if (exponent >= 0)
return result;
else
return 1 / result;
}
```
### 七 调整数组顺序使奇数位于偶数前面
#### **题目描述:**
输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有的奇数位于数组的前半部分,所有的偶数位于位于数组的后半部分,并保证奇数和奇数,偶数和偶数之间的相对位置不变。
#### **问题解析:**
这道题有挺多种解法的,给大家介绍一种我觉得挺好理解的方法:
我们首先统计奇数的个数假设为n,然后新建一个等长数组,然后通过循环判断原数组中的元素为偶数还是奇数。如果是则从数组下标0的元素开始,把该奇数添加到新数组;如果是偶数则从数组下标为n的元素开始把该偶数添加到新数组中。
#### **示例代码:**
时间复杂度为O(n),空间复杂度为O(n)的算法
```java
public class Solution {
public void reOrderArray(int [] array) {
//如果数组长度等于0或者等于1,什么都不做直接返回
if(array.length==0||array.length==1)
return;
//oddCount:保存奇数个数
//oddBegin:奇数从数组头部开始添加
int oddCount=0,oddBegin=0;
//新建一个数组
int[] newArray=new int[array.length];
//计算出(数组中的奇数个数)开始添加元素
for(int i=0;i<array.length;i++){
if((array[i]&1)==1) oddCount++;
}
for(int i=0;i<array.length;i++){
//如果数为基数新数组从头开始添加元素
//如果为偶数就从oddCount(数组中的奇数个数)开始添加元素
if((array[i]&1)==1)
newArray[oddBegin++]=array[i];
else newArray[oddCount++]=array[i];
}
for(int i=0;i<array.length;i++){
array[i]=newArray[i];
}
}
}
```
### 八 链表中倒数第k个节点
#### **题目描述:**
输入一个链表,输出该链表中倒数第k个结点
#### **问题分析:**
**一句话概括:**
两个指针一个指针p1先开始跑,指针p1跑到k-1个节点后,另一个节点p2开始跑,当p1跑到最后时,p2所指的指针就是倒数第k个节点。
**思想的简单理解:**
前提假设:链表的结点个数(长度)为n。
规律一:要找到倒数第k个结点,需要向前走多少步呢?比如倒数第一个结点,需要走n步,那倒数第二个结点呢?很明显是向前走了n-1步,所以可以找到规律是找到倒数第k个结点,需要向前走n-k+1步。
**算法开始:**
1. 设两个都指向head的指针p1和p2,当p1走了k-1步的时候,停下来。p2之前一直不动。
2. p1的下一步是走第k步,这个时候,p2开始一起动了。至于为什么p2这个时候动呢?看下面的分析。
3. 当p1走到链表的尾部时,即p1走了n步。由于我们知道p2是在p1走了k-1步才开始动的,也就是说p1和p2永远差k-1步。所以当p1走了n步时,p2走的应该是在n-(k-1)步。即p2走了n-k+1步,此时巧妙的是p2正好指向的是规律一的倒数第k个结点处。
这样是不是很好理解了呢?
#### **考察内容:**
链表+代码的鲁棒性
#### **示例代码:**
```java
/*
//链表类
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}*/
//时间复杂度O(n),一次遍历即可
public class Solution {
public ListNode FindKthToTail(ListNode head,int k) {
ListNode pre=null,p=null;
//两个指针都指向头结点
p=head;
pre=head;
//记录k值
int a=k;
//记录节点的个数
int count=0;
//p指针先跑,并且记录节点数,当p指针跑了k-1个节点后,pre指针开始跑,
//当p指针跑到最后时,pre所指指针就是倒数第k个节点
while(p!=null){
p=p.next;
count++;
if(k<1){
pre=pre.next;
}
k--;
}
//如果节点个数小于所求的倒数第k个节点,则返回空
if(count<a) return null;
return pre;
}
}
```
### 九 反转链表
#### **题目描述:**
输入一个链表,反转链表后,输出链表的所有元素。
#### **问题分析:**
链表的很常规的一道题,这一道题思路不算难,但自己实现起来真的可能会感觉无从下手,我是参考了别人的代码。
思路就是我们根据链表的特点,前一个节点指向下一个节点的特点,把后面的节点移到前面来。
就比如下图:我们把1节点和2节点互换位置,然后再将3节点指向2节点,4节点指向3节点,这样以来下面的链表就被反转了。
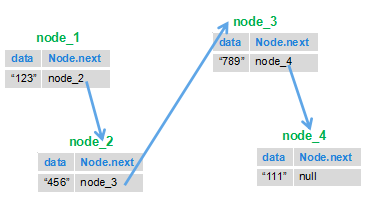
#### **考察内容:**
链表+代码的鲁棒性
#### **示例代码:**
```java
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}*/
public class Solution {
public ListNode ReverseList(ListNode head) {
ListNode next = null;
ListNode pre = null;
while (head != null) {
//保存要反转到头来的那个节点
next = head.next;
//要反转的那个节点指向已经反转的上一个节点
head.next = pre;
//上一个已经反转到头部的节点
pre = head;
//一直向链表尾走
head = next;
}
return pre;
}
}
```
### 十 合并两个排序的链表
#### **题目描述:**
输入两个单调递增的链表,输出两个链表合成后的链表,当然我们需要合成后的链表满足单调不减规则。
#### **问题分析:**
我们可以这样分析:
1. 假设我们有两个链表 A,B;
2. A的头节点A1的值与B的头结点B1的值比较,假设A1小,则A1为头节点;
3. A2再和B1比较,假设B1小,则,A1指向B1;
4. A2再和B2比较。。。。。。。
就这样循环往复就行了,应该还算好理解。
#### **考察内容:**
链表+代码的鲁棒性
#### **示例代码:**
**非递归版本:**
```java
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}*/
public class Solution {
public ListNode Merge(ListNode list1,ListNode list2) {
//list1为空,直接返回list2
if(list1 == null){
return list2;
}
//list2为空,直接返回list1
if(list2 == null){
return list1;
}
ListNode mergeHead = null;
ListNode current = null;
//当list1和list2不为空时
while(list1!=null && list2!=null){
//取较小值作头结点
if(list1.val <= list2.val){
if(mergeHead == null){
mergeHead = current = list1;
}else{
current.next = list1;
//current节点保存list1节点的值因为下一次还要用
current = list1;
}
//list1指向下一个节点
list1 = list1.next;
}else{
if(mergeHead == null){
mergeHead = current = list2;
}else{
current.next = list2;
//current节点保存list2节点的值因为下一次还要用
current = list2;
}
//list2指向下一个节点
list2 = list2.next;
}
}
if(list1 == null){
current.next = list2;
}else{
current.next = list1;
}
return mergeHead;
}
}
```
**递归版本:**
```java
public ListNode Merge(ListNode list1,ListNode list2) {
if(list1 == null){
return list2;
}
if(list2 == null){
return list1;
}
if(list1.val <= list2.val){
list1.next = Merge(list1.next, list2);
return list1;
}else{
list2.next = Merge(list1, list2.next);
return list2;
}
}
```
### 十一 用两个栈实现队列
#### **题目描述:**
用两个栈来实现一个队列,完成队列的Push和Pop操作。 队列中的元素为int类型。
#### 问题分析:
先来回顾一下栈和队列的基本特点:
**栈:**后进先出(LIFO)
**队列:** 先进先出
很明显我们需要根据JDK给我们提供的栈的一些基本方法来实现。先来看一下Stack类的一些基本方法:
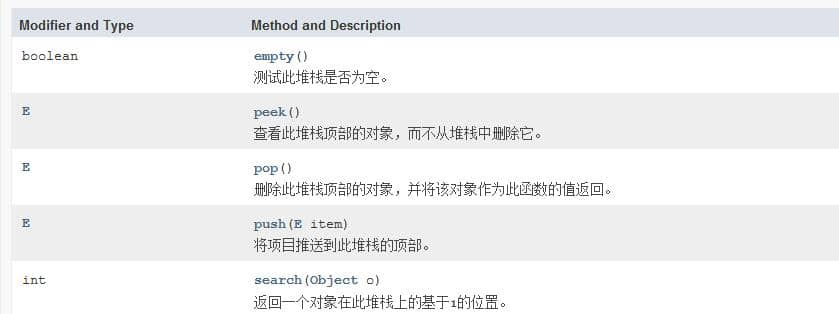
既然题目给了我们两个栈,我们可以这样考虑当push的时候将元素push进stack1,pop的时候我们先把stack1的元素pop到stack2,然后再对stack2执行pop操作,这样就可以保证是先进先出的。(负[pop]负[pop]得正[先进先出])
#### 考察内容:
队列+栈
#### 示例代码:
```java
//左程云的《程序员代码面试指南》的答案
import java.util.Stack;
public class Solution {
Stack<Integer> stack1 = new Stack<Integer>();
Stack<Integer> stack2 = new Stack<Integer>();
//当执行push操作时,将元素添加到stack1
public void push(int node) {
stack1.push(node);
}
public int pop() {
//如果两个队列都为空则抛出异常,说明用户没有push进任何元素
if(stack1.empty()&&stack2.empty()){
throw new RuntimeException("Queue is empty!");
}
//如果stack2不为空直接对stack2执行pop操作,
if(stack2.empty()){
while(!stack1.empty()){
//将stack1的元素按后进先出push进stack2里面
stack2.push(stack1.pop());
}
}
return stack2.pop();
}
}
```
### 十二 栈的压入,弹出序列
#### **题目描述:**
输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如序列1,2,3,4,5是某栈的压入顺序,序列4,5,3,2,1是该压栈序列对应的一个弹出序列,但4,3,5,1,2就不可能是该压栈序列的弹出序列。(注意:这两个序列的长度是相等的)
#### **题目分析:**
这道题想了半天没有思路,参考了Alias的答案,他的思路写的也很详细应该很容易看懂。
作者:Alias
https://www.nowcoder.com/questionTerminal/d77d11405cc7470d82554cb392585106
来源:牛客网
【思路】借用一个辅助的栈,遍历压栈顺序,先讲第一个放入栈中,这里是1,然后判断栈顶元素是不是出栈顺序的第一个元素,这里是4,很显然1≠4,所以我们继续压栈,直到相等以后开始出栈,出栈一个元素,则将出栈顺序向后移动一位,直到不相等,这样循环等压栈顺序遍历完成,如果辅助栈还不为空,说明弹出序列不是该栈的弹出顺序。
举例:
入栈1,2,3,4,5
出栈4,5,3,2,1
首先1入辅助栈,此时栈顶1≠4,继续入栈2
此时栈顶2≠4,继续入栈3
此时栈顶3≠4,继续入栈4
此时栈顶4=4,出栈4,弹出序列向后一位,此时为5,,辅助栈里面是1,2,3
此时栈顶3≠5,继续入栈5
此时栈顶5=5,出栈5,弹出序列向后一位,此时为3,,辅助栈里面是1,2,3
….
依次执行,最后辅助栈为空。如果不为空说明弹出序列不是该栈的弹出顺序。
#### **考察内容:**
栈
#### **示例代码:**
```java
import java.util.ArrayList;
import java.util.Stack;
//这道题没想出来,参考了Alias同学的答案:https://www.nowcoder.com/questionTerminal/d77d11405cc7470d82554cb392585106
public class Solution {
public boolean IsPopOrder(int [] pushA,int [] popA) {
if(pushA.length == 0 || popA.length == 0)
return false;
Stack<Integer> s = new Stack<Integer>();
//用于标识弹出序列的位置
int popIndex = 0;
for(int i = 0; i< pushA.length;i++){
s.push(pushA[i]);
//如果栈不为空,且栈顶元素等于弹出序列
while(!s.empty() &&s.peek() == popA[popIndex]){
//出栈
s.pop();
//弹出序列向后一位
popIndex++;
}
}
return s.empty();
}
}
```
下面只是简单地总结,给了一些参考文章,后面会对这部分内容进行重构。
<!-- MarkdownTOC -->
- [Queue](#queue)
- [什么是队列](#什么是队列)
- [队列的种类](#队列的种类)
- [Java 集合框架中的队列 Queue](#java-集合框架中的队列-queue)
- [推荐文章](#推荐文章)
- [Set](#set)
- [什么是 Set](#什么是-set)
- [补充:有序集合与无序集合说明](#补充:有序集合与无序集合说明)
- [HashSet 和 TreeSet 底层数据结构](#hashset-和-treeset-底层数据结构)
- [推荐文章](#推荐文章-1)
- [List](#list)
- [什么是List](#什么是list)
- [List的常见实现类](#list的常见实现类)
- [ArrayList 和 LinkedList 源码学习](#arraylist-和-linkedlist-源码学习)
- [推荐阅读](#推荐阅读)
- [Map](#map)
- [树](#树)
<!-- /MarkdownTOC -->
## Queue
### 什么是队列
队列是数据结构中比较重要的一种类型,它支持 FIFO,尾部添加、头部删除(先进队列的元素先出队列),跟我们生活中的排队类似。
### 队列的种类
- **单队列**(单队列就是常见的队列, 每次添加元素时,都是添加到队尾,存在“假溢出”的问题也就是明明有位置却不能添加的情况)
- **循环队列**(避免了“假溢出”的问题)
### Java 集合框架中的队列 Queue
Java 集合中的 Queue 继承自 Collection 接口 ,Deque, LinkedList, PriorityQueue, BlockingQueue 等类都实现了它。
Queue 用来存放 等待处理元素 的集合,这种场景一般用于缓冲、并发访问。
除了继承 Collection 接口的一些方法,Queue 还添加了额外的 添加、删除、查询操作。
### 推荐文章
- [Java 集合深入理解(9):Queue 队列](https://blog.csdn.net/u011240877/article/details/52860924)
## Set
### 什么是 Set
Set 继承于 Collection 接口,是一个不允许出现重复元素,并且无序的集合,主要 HashSet 和 TreeSet 两大实现类。
在判断重复元素的时候,HashSet 集合会调用 hashCode()和 equal()方法来实现;TreeSet 集合会调用compareTo方法来实现。
### 补充:有序集合与无序集合说明
- 有序集合:集合里的元素可以根据 key 或 index 访问 (List、Map)
- 无序集合:集合里的元素只能遍历。(Set)
### HashSet 和 TreeSet 底层数据结构
**HashSet** 是哈希表结构,主要利用 HashMap 的 key 来存储元素,计算插入元素的 hashCode 来获取元素在集合中的位置;
**TreeSet** 是红黑树结构,每一个元素都是树中的一个节点,插入的元素都会进行排序;
### 推荐文章
- [Java集合--Set(基础)](https://www.jianshu.com/p/b48c47a42916)
## List
### 什么是List
在 List 中,用户可以精确控制列表中每个元素的插入位置,另外用户可以通过整数索引(列表中的位置)访问元素,并搜索列表中的元素。 与 Set 不同,List 通常允许重复的元素。 另外 List 是有序集合而 Set 是无序集合。
### List的常见实现类
**ArrayList** 是一个数组队列,相当于动态数组。它由数组实现,随机访问效率高,随机插入、随机删除效率低。
**LinkedList** 是一个双向链表。它也可以被当作堆栈、队列或双端队列进行操作。LinkedList随机访问效率低,但随机插入、随机删除效率高。
**Vector** 是矢量队列,和ArrayList一样,它也是一个动态数组,由数组实现。但是ArrayList是非线程安全的,而Vector是线程安全的。
**Stack** 是栈,它继承于Vector。它的特性是:先进后出(FILO, First In Last Out)。相关阅读:[java数据结构与算法之栈(Stack)设计与实现](https://blog.csdn.net/javazejian/article/details/53362993)
### ArrayList 和 LinkedList 源码学习
- [ArrayList 源码学习](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/collection/ArrayList.md)
- [LinkedList 源码学习](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/collection/LinkedList.md)
### 推荐阅读
- [java 数据结构与算法之顺序表与链表深入分析](https://blog.csdn.net/javazejian/article/details/52953190)
## Map
- [集合框架源码学习之 HashMap(JDK1.8)](https://juejin.im/post/5ab0568b5188255580020e56)
- [ConcurrentHashMap 实现原理及源码分析](https://link.juejin.im/?target=http%3A%2F%2Fwww.cnblogs.com%2Fchengxiao%2Fp%2F6842045.html)
## 树
* ### 1 二叉树
[二叉树](https://baike.baidu.com/item/%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科)
(1)[完全二叉树](https://baike.baidu.com/item/%E5%AE%8C%E5%85%A8%E4%BA%8C%E5%8F%89%E6%A0%91)——若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。
(2)[满二叉树](https://baike.baidu.com/item/%E6%BB%A1%E4%BA%8C%E5%8F%89%E6%A0%91)——除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
(3)[平衡二叉树](https://baike.baidu.com/item/%E5%B9%B3%E8%A1%A1%E4%BA%8C%E5%8F%89%E6%A0%91/10421057)——平衡二叉树又被称为AVL树(区别于AVL算法),它是一棵二叉排序树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
* ### 2 完全二叉树
[完全二叉树](https://baike.baidu.com/item/%E5%AE%8C%E5%85%A8%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科)
完全二叉树:叶节点只能出现在最下层和次下层,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树。
* ### 3 满二叉树
[满二叉树](https://baike.baidu.com/item/%E6%BB%A1%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科,国内外的定义不同)
国内教程定义:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果一个二叉树的层数为K,且结点总数是(2^k) -1 ,则它就是满二叉树。
* ### 堆
[数据结构之堆的定义](https://blog.csdn.net/qq_33186366/article/details/51876191)
堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。
* ### 4 二叉查找树(BST)
[浅谈算法和数据结构: 七 二叉查找树](http://www.cnblogs.com/yangecnu/p/Introduce-Binary-Search-Tree.html)
二叉查找树的特点:
1. 若任意节点的左子树不空,则左子树上所有结点的 值均小于它的根结点的值;
2. 若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
3. 任意节点的左、右子树也分别为二叉查找树;
4. 没有键值相等的节点(no duplicate nodes)。
* ### 5 平衡二叉树(Self-balancing binary search tree)
[ 平衡二叉树](https://baike.baidu.com/item/%E5%B9%B3%E8%A1%A1%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科,平衡二叉树的常用实现方法有红黑树、AVL、替罪羊树、Treap、伸展树等)
* ### 6 红黑树
- 红黑树特点:
1. 每个节点非红即黑;
2. 根节点总是黑色的;
3. 每个叶子节点都是黑色的空节点(NIL节点);
4. 如果节点是红色的,则它的子节点必须是黑色的(反之不一定);
5. 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)。
- 红黑树的应用:
TreeMap、TreeSet以及JDK1.8之后的HashMap底层都用到了红黑树。
- 为什么要用红黑树
简单来说红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。详细了解可以查看 [漫画:什么是红黑树?](https://juejin.im/post/5a27c6946fb9a04509096248#comment)(也介绍到了二叉查找树,非常推荐)
- 推荐文章:
- [漫画:什么是红黑树?](https://juejin.im/post/5a27c6946fb9a04509096248#comment)(也介绍到了二叉查找树,非常推荐)
- [寻找红黑树的操作手册](http://dandanlove.com/2018/03/18/red-black-tree/)(文章排版以及思路真的不错)
- [红黑树深入剖析及Java实现](https://zhuanlan.zhihu.com/p/24367771)(美团点评技术团队)
* ### 7 B-,B+,B*树
[二叉树学习笔记之B树、B+树、B*树 ](https://yq.aliyun.com/articles/38345)
[《B-树,B+树,B*树详解》](https://blog.csdn.net/aqzwss/article/details/53074186)
[《B-树,B+树与B*树的优缺点比较》](https://blog.csdn.net/bigtree_3721/article/details/73632405)
B-树(或B树)是一种平衡的多路查找(又称排序)树,在文件系统中有所应用。主要用作文件的索引。其中的B就表示平衡(Balance)
1. B+ 树的叶子节点链表结构相比于 B- 树便于扫库,和范围检索。
2. B+树支持range-query(区间查询)非常方便,而B树不支持。这是数据库选用B+树的最主要原因。
3. B\*树 是B+树的变体,B\*树分配新结点的概率比B+树要低,空间使用率更高;
* ### 8 LSM 树
[[HBase] LSM树 VS B+树](https://blog.csdn.net/dbanote/article/details/8897599)
B+树最大的性能问题是会产生大量的随机IO
为了克服B+树的弱点,HBase引入了LSM树的概念,即Log-Structured Merge-Trees。
[LSM树由来、设计思想以及应用到HBase的索引](http://www.cnblogs.com/yanghuahui/p/3483754.html)
## 图
## BFS及DFS
- [《使用BFS及DFS遍历树和图的思路及实现》](https://blog.csdn.net/Gene1994/article/details/85097507)
我比较推荐大家可以刷一下 Leetcode ,我自己平时没事也会刷一下,我觉得刷 Leetcode 不仅是为了能让你更从容地面对面试中的手撕算法问题,更可以提高你的编程思维能力、解决问题的能力以及你对某门编程语言 API 的熟练度。当然牛客网也有一些算法题,我下面也整理了一些。
## LeetCode
- [LeetCode(中国)官网](https://leetcode-cn.com/)
- [如何高效地使用 LeetCode](https://leetcode-cn.com/articles/%E5%A6%82%E4%BD%95%E9%AB%98%E6%95%88%E5%9C%B0%E4%BD%BF%E7%94%A8-leetcode/)
## 牛客网
- [牛客网官网](https://www.nowcoder.com)
- [剑指offer编程题](https://www.nowcoder.com/ta/coding-interviews)
- [2017校招真题](https://www.nowcoder.com/ta/2017test)
- [华为机试题](https://www.nowcoder.com/ta/huawei)
## 公司真题
- [ 网易2018校园招聘编程题真题集合](https://www.nowcoder.com/test/6910869/summary)
- [ 网易2018校招内推编程题集合](https://www.nowcoder.com/test/6291726/summary)
- [2017年校招全国统一模拟笔试(第五场)编程题集合](https://www.nowcoder.com/test/5986669/summary)
- [2017年校招全国统一模拟笔试(第四场)编程题集合](https://www.nowcoder.com/test/5507925/summary)
- [2017年校招全国统一模拟笔试(第三场)编程题集合](https://www.nowcoder.com/test/5217106/summary)
- [2017年校招全国统一模拟笔试(第二场)编程题集合](https://www.nowcoder.com/test/4546329/summary)
- [ 2017年校招全国统一模拟笔试(第一场)编程题集合](https://www.nowcoder.com/test/4236887/summary)
- [百度2017春招笔试真题编程题集合](https://www.nowcoder.com/test/4998655/summary)
- [网易2017春招笔试真题编程题集合](https://www.nowcoder.com/test/4575457/summary)
- [网易2017秋招编程题集合](https://www.nowcoder.com/test/2811407/summary)
- [网易有道2017内推编程题](https://www.nowcoder.com/test/2385858/summary)
- [ 滴滴出行2017秋招笔试真题-编程题汇总](https://www.nowcoder.com/test/3701760/summary)
- [腾讯2017暑期实习生编程题](https://www.nowcoder.com/test/1725829/summary)
- [今日头条2017客户端工程师实习生笔试题](https://www.nowcoder.com/test/1649301/summary)
- [今日头条2017后端工程师实习生笔试题](https://www.nowcoder.com/test/1649268/summary)



























 3931
3931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











