






最近,在大波面试来袭的时候,我默默的在这钻研spark的安装,以前的linux的基础知识都忘得差不多了,所以安装起来比较麻烦,于是写下这篇安装博文,希望有用。
前言
首先,我在电脑上安装了ubuntu操作系统,这也不是件简单的事,首先需要一个U盘,然后在ubuntu官网上下载对应的桌面版本的镜像文件,对应的界面如下:
下载完成后,将U盘插入到电脑上面,然后到网页下载USB Installer页面 上面,下载一个叫“USB Installer”的工具,下载完成后直接运行,选择对应的镜像包版本和文件,以及对应的U盘,然后安装,这样U盘就变成了一个启动盘,可以用于系统的安装。
将U盘插入电脑之后,点击重启电脑,这样电脑就会弹出几个选项,根据需求选择对应的选项,我选的是第二项,安装ubuntu系统,之后就进入到ubuntu install中,根据选项依次进行选择,一般来说,下一步就可,部分选项可根据实际情况进行选择。安装完成后,重启电脑,这样ubuntu系统就安装完成了。
PS:参考,http://jingyan.baidu.com/article/27fa73269b14fd46f9271f53.html
系统安装过程主要遇到的问题是如何将U盘变为启动盘,现在有很多工具,例如大白菜和老毛桃,网上也有很多攻略可供参考。
其实安装一个虚拟机也可以用于spark的搭建,我为了系统运行,所以选择直接搭建系统,选择很多,可根据自己需求进行安装。
正文
首先要下载对应的环境,例如JDK,Scala,Hadoop和Spark对应文件,我下载的是jdk-linux.gz,hadoop.tar.gz,scala.tgz,spark-hadoop.tgz,具体的版本可根据实际情况选择,我的下载文件如下: 
ps:这里有个小错误,我下载的jdk为32位,而装的系统为64位,后期就遇到问题了,所以特别指出。
声明:接下来的步骤主要是参考http://wuchong.me/blog/2015/04/04/spark-on-yarn-cluster-deploy/这篇博文,大家可以具体看看,我还是省略了一部分。
1.环境配置
修改主机名: sudo vi /etc/hostname,在master上修改为master,其中一个slave上修改为slave1,另一个同理。
配置hosts
在每台主机上修改host文件 : 首先进入到文件中,然后修改文件,退出并保存文件。
sudo vi /etc/hosts
10.1.1.107 master
10.1.1.108 slave1
10.1.1.109 slave2配置之后ping一下用户名看是否生效
ping slave1
ping slave2还有使用ssh来连通各个电脑,这个我自己也还没理解透,反正用处挺大的,可参考上述文章进行设置。安装Openssh server的命令为:
sudo apt-get install openssh-server2.安装java
spark要求java的版本必须为6以上,我后来下载的是jdk1.8.0,解压到opt目录下:
tar zxvf /jdk-8u102-linux-x64 -C /opt(注:这个目录必须存在)修改环境变量sudo vi /etc/profile,添加下列内容,注意将路径替换成你自己的:
export WORK_SPACE=~/workspace/
export JAVA_HOME=/opt/jdk1.8.0_20
export JRE_HOME=/opt/jdk1.8.0_20/jre
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export CLASSPATH=$CLASSPATH:.:$JAVA_HOME/lib/tool.jar:$JAVA_HOME/jre/lib/rt.jar(注意,这里与参考博文不同,应该这么写,否则可能有错误)
然后使环境变量生效,并验证 Java 是否安装成功
$ source /etc/profile #生效环境变量
$ java -version #如果打印出如下版本信息,则说明安装成功
java version "1.7.0_75"
Java(TM) SE Runtime Environment (build 1.7.0_75-b13)
Java HotSpot(TM) 64-Bit Server VM (build 24.75-b04, mixed mode)3.安装 Scala
park官方要求 Scala 版本为 2.10.x,注意不要下错版本,我这里下了 2.10.4,官方下载地址,注意要下载.tgz为后缀的文件,下载完成后在对应的工作目录下解压:
tar -zxvf scala-2.10.4.tgz(可直接在目录中打开终端,然后解压)再次修改环境变量sudo vi /etc/profile,添加以下内容:
export SCALA_HOME=$WORK_SPACE/scala-2.10.4
export PATH=$PATH:$SCALA_HOME/bin同样的方法使环境变量生效,并验证 scala 是否安装成功
$ source /etc/profile #生效环境变量
$ scala -version #如果打印出如下版本信息,则说明安装成功
Scala code runner version 2.10.4 -- Copyright 2002-2013, LAMP/EPFL4.安装配置 Hadoop YARN
首先从官网下载 hadoop2.6.0 版本,这里给出镜像下载地址。同样工作空间中解压:
tar -zxvf hadoop-2.6.0.tar.gz配置 Hadoop
cd ~/workspace/hadoop-2.6.0/etc/hadoop进入hadoop配置目录,需要配置有以下7个文件:hadoop-env.sh,yarn-env.sh,slaves,core-site.xml,hdfs-site.xml,maprd-site.xml,yarn-site.xml
- 在hadoop-env.sh中配置JAVA_HOME
# The java implementation to use.
export JAVA_HOME=/opt/jdk1.8.0_20- 在yarn-env.sh中配置JAVA_HOME
# some Java parameters
export JAVA_HOME=/home/spark/workspace/jdk1.7.0_75- 在slaves中配置slave节点的ip或者host,
slave1
slave2- 修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/spark/workspace/hadoop-2.6.0/tmp</value>
</property>
</configuration>- 修改hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/spark/workspace/hadoop-2.6.0/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/spark/workspace/hadoop-2.6.0/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>- 修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>- 修改yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>- 将配置好的hadoop-2.6.0文件夹分发给所有slaves吧
scp -r ~/workspace/hadoop-2.6.0 spark@slave1:~/workspace/- 启动 Hadoop
在 master 上执行以下操作,就可以启动 hadoop 了。
cd ~/workspace/hadoop-2.6.0 #进入hadoop目录
bin/hadoop namenode -format #格式化namenode
sbin/start-dfs.sh #启动dfs
sbin/start-yarn.sh #启动yarn- 验证 Hadoop 是否安装成功
可以通过jps命令查看各个节点启动的进程是否正常。在 master 上应该有以下几个进程:
$ jps #run on master
3407 SecondaryNameNode
3218 NameNode
3552 ResourceManager
3910 Jps在每个slave上应该有以下几个进程:
$ jps #run on slaves
2072 NodeManager
2213 Jps
1962 DataNode或者在浏览器中输入 http://master:8088 ,应该有 hadoop 的管理界面出来了,并能看到 slave1 和 slave2 节点。
5.Spark安装
- 下载解压
进入官方下载地址下载最新版 Spark。我下载的是 spark-1.3.1-bin-hadoop2.6.tgz。在~/workspace目录下解压:
tar -zxvf spark-1.3.0-bin-hadoop2.4.tgz
mv spark-1.3.0-bin-hadoop2.4 spark-1.3.0 #原来的文件名太长了,修改下- 配置 Spark
cd ~/workspace/spark-1.3.0/conf #进入spark配置目录
cp spark-env.sh.template spark-env.sh #从配置模板复制
vi spark-env.sh #添加配置内容在spark-env.sh末尾添加以下内容(这是我的配置,你可以自行修改):
export SCALA_HOME=/home/spark/workspace/scala-2.10.4
export JAVA_HOME=/home/spark/workspace/jdk1.7.0_75
export HADOOP_HOME=/home/spark/workspace/hadoop-2.6.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
SPARK_MASTER_IP=master
SPARK_LOCAL_DIRS=/home/spark/workspace/spark-1.3.0
SPARK_DRIVER_MEMORY=1G注:在设置Worker进程的CPU个数和内存大小,要注意机器的实际硬件条件,如果配置的超过当前Worker节点的硬件条件,Worker进程会启动失败。
vi slaves在slaves文件下填上slave主机名:
slave1
slave2将配置好的spark-1.3.0文件夹分发给所有slaves吧
scp -r ~/workspace/spark-1.3.0 spark@slave1:~/workspace/启动Spark
sbin/start-all.sh- 1
验证 Spark 是否安装成功
用jps检查,在 master 上应该有以下几个进
$ jps
7949 Jps
7328 SecondaryNameNode
7805 Master
7137 NameNode
7475 ResourceManagerslave 上应该有以下几个进程:
$jps
3132 DataNode
3759 Worker
3858 Jps
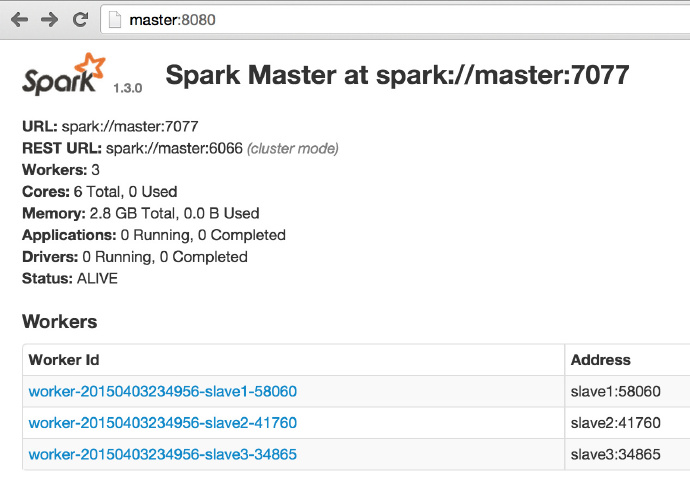
3231 NodeManager进入Spark的Web管理页面: http://master:8080














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









