







最近群里传的很火的一个爬虫练习网站.(网站做的非常走心, 支持一下.)
url : http://glidedsky.com/
做了几个题感觉非常有意思, 和大家交流分享一波.
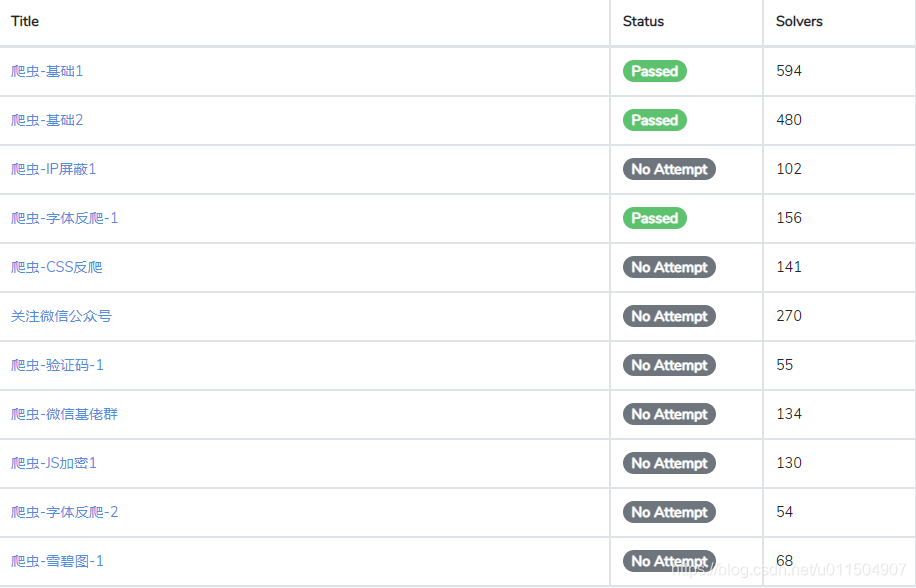
第一题:
- 这里有一个网站,里面有一些数字。把这些数字的总和,输入到答案框里面,即可通过本关. 这个咱就不说了, 把数据全都取出相加就可以通关了.
第二题:
- 在第一题的基础上加了翻页.在code中加个链接迭代就行了.
第三题(IP 屏蔽):
- 从这开始就有意思了.每个 IP,只能访问一次,之后就会被封禁。一共1000页.也就是要最少1000个代理ip,
因为没那么多ip咱就不做了.有条件的小伙伴可以选阿布云的动态ip.每次请求都是一个新的ip. 按照第二题的思路就可以搞定
第四题 (字体反爬):
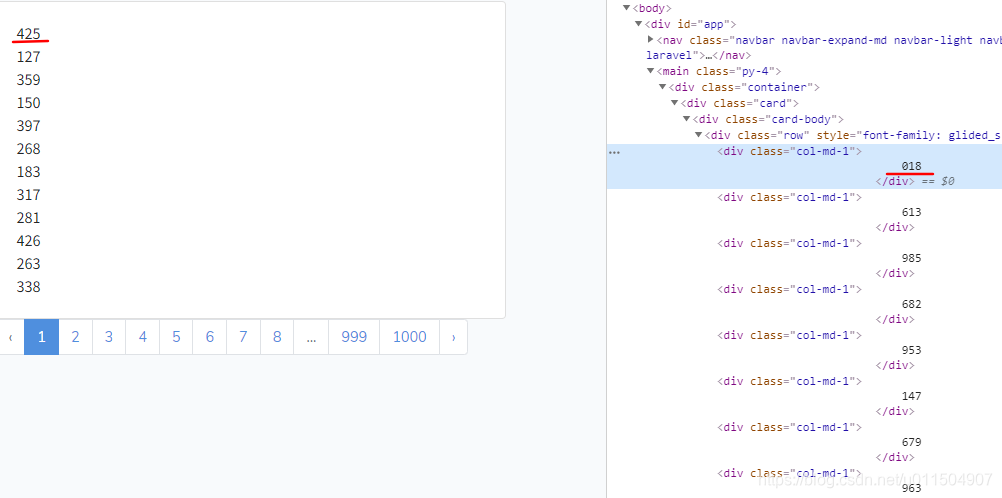
- 很明显可以看出从页面源码中得到的数据和实际在浏览器中看到的数字是不一样的.并且每次刷新页面源码中的数字都不同,
说明font是动态加载的.

- 源码中可以找到字体文件. 用base64解密保存成woff文件.再用fontcreator打开就可以看到他们的映射关系.
直接上码.
import requests
import re
from lxml import etree
import base64
from fontTools.ttLib import TTFont
session = requests.session()
h = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36',
}
login_url = "http://glidedsky.com/login"
session.headers = h
sum_number = 0
a_map = {
'one': '1',
'two': '2',
'three': '3',
'four': '4',
'five': '5',
'six': '6',
'seven': '7',
'eight': '8',
'nine': '9',
'zero': '0'
}
def get_token():
resp = session.get(login_url)
_token = re.search('<meta name="csrf-token" content="(.*?)">', resp.text).group(1)
return _token
def login(token):
data = {
'_token': token,
'email': '你的账号',
'password': '你的密码'
}
session.post(login_url, data=data)
def get_html(url):
result = session.get(url)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1367
1367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









