







提示:此工具基于selenium爬虫框架,故本机必须安装chrome浏览器
文章目录
前言
这里只贴出了源码,我们公司内部使用时打包成了exe文件,windows电脑可以直接运行,如有需要请下你的邮箱。
后续更新计划:
1.增加其他工具支持,比如JS
2.增加多线程,提高运行效率
3.词频统计,自动生成ST关键词,亚马逊标题,五点描述
4.开发Web版本
提示:以下是本篇文章正文内容,下面案例可供参考
一、项目结构
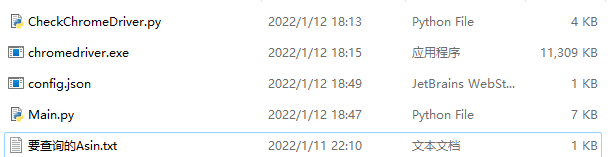
- Main.py - 主程序
- CheckChromeDriver.py - 检查chromedriver版本号
- config.json - 配置文件
- 要查询的Asin.txt - 放入需要查询的Asin
- chromedriver.exe - 爬虫支持程序
二、项目说明
1.Main.py
代码如下:
import os
import xlrd
import xlwt
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support.expected_conditions import presence_of_element_located
from selenium.webdriver.chrome.service import Service
import json
from xlutils.copy import copy
import CheckChromeDriver as ccd
import time
def getKeywordByAsin(asin, pagecount):
browser.get('https://xp.sellermotor.com/selection/asin-query/query')
keywordList = []
# 切换站点
country = browser.find_element(By.ID, 'search_country_code').get_attribute('data-value')
if country != countryCode:
js = '$("#search_country_code").attr("data-value","jp")'
browser.execute_script(js)
country = browser.find_element(By.ID, 'search_country_code').get_attribute('data-value')
print("Current country:", country)
# 输入Asin
browser.find_element(By.XPATH, '//*[@id="search-keyword"]').send_keys(asin)
# 点击查询
browser.find_element(By.XPATH, '//*[@id="market-insight-search"]').click()
# element = browser.find_element(By.CLASS_NAME, 'pagination')
wait.until(presence_of_element_located((By.CLASS_NAME, 'page-item')))
c = browser.find_elements(By.CLASS_NAME, 'page-item')
page_count = c[len(c) - 2].text
if page_count:
next_click_count = int(page_count)
else:
next_click_count = 1
print(next_click_count)
title = None
for i in range(next_click_count):
if i == pagecount:
break
print('------------------Page %s------------------' % (i))
table = browser.find_element(By.ID, 'asinQueryTable')
header = table.find_element(By.TAG_NAME, 'thead')
body = table.find_element(By.TAG_NAME, 'tbody')
rows = body.find_elements(By.TAG_NAME, 'tr')
titles = header.find_elements(By.TAG_NAME,</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 907
907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









