







图像压缩编码是专门研究图像数据压缩的技术,就是尽量减少表示数据图像所需要的数据量。
本章主要介绍图像压缩编码的基础知识,重点讲解常用的图像压缩编码方法,如霍夫曼编码、香农编码、算术编码、行程编码和预测编码及编码方法的MATLAB实现,最后介绍了静态图像压缩标准JPEG标准。
数字图像通常需要很大的比特数,这给图像的传输和存储带来相当大的困难。例如用8bit存储一幅512512的灰度图像的比特数为256K。而一部60分钟的彩色电影,如果每秒放映24帧,数字化后每帧包含512512像素,每像素的R、G、B分量分别占8bit,则这样一部电影的总比特数为64800M,若用一张600M的CD存储则需要100多张CD光盘来存储。由此可见对图像数据进行压缩显得非常必要。减少存储空间、缩短传输时间这成为促进图像压缩编码技术发展的主导因素。图像压缩是通过编码来实现的,所以通常将压缩与编码统称为图像的压缩编码。图像压缩编码从本质上来说就是对要处理的图像数据按照一定的规则进行变换和组合,从而达到以尽可能少的数据来表示尽可能多的数据信息。
1 霍夫曼编码
霍夫曼在1952年提出了一种构造最佳码的方法,称之为霍夫曼编码(Huffman)。霍夫曼编码是一种无损的统计编码方法,利用信息符号概率分布特性的改变字长进行编码。霍夫曼编码适用于多远独立信源,对于多元独立信源来说它是最佳码。
霍夫曼编码是一种利用信息符号概率分布特性的变字长的编码方法,即对于出现概率大的信息符号编以短字长的码,对于出现概率小的信息符号编以长字长的码。如果码字长度严格按照所对应符号出现概率大小逆序排列,则编码结果的平均码字长度一定小于任何其他排列形式。霍夫曼编码则是严格按照信源符号出现的概率大小来构造码字,因此这种编码方式形成的平均码字长度最短。
霍夫曼编码系统主要分为压缩对象输入、概率统计、构造Huffman树、生成Huffman树、压缩编码环节组成,如图所示霍夫曼编解码系统构成。编程思路依据霍夫曼的编程步骤进行,实现对数据的压缩及其压缩参数的计算。
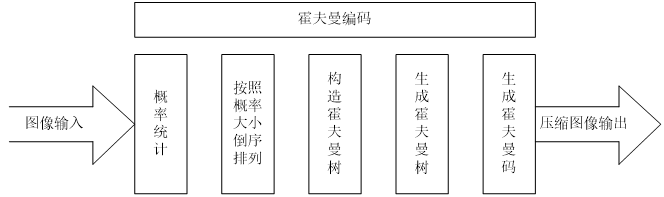
1.1编码参数
一副大小为m*n的图像灰度级为K,图像中第k级灰度出现的概率为Pk,每个像素用d比特表示,每两帧图像间隔为△t,则相关参数为:
数字图像的熵H :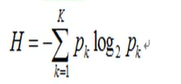
表示图像信源的平均信息量。
图像平均码子长度R: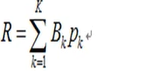
描述图像压缩后的平均码子长度。
编码效率: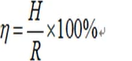
描述图像编码效率
信息冗余度: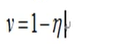
描述图像被压缩的程度,冗余度越小则图像可以被压缩的程度越小。
每秒所需的传输比特数为: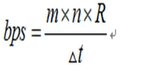
反映的数据的容量。
压缩比: r = d/R
1.2 霍夫曼编码的步骤如下:
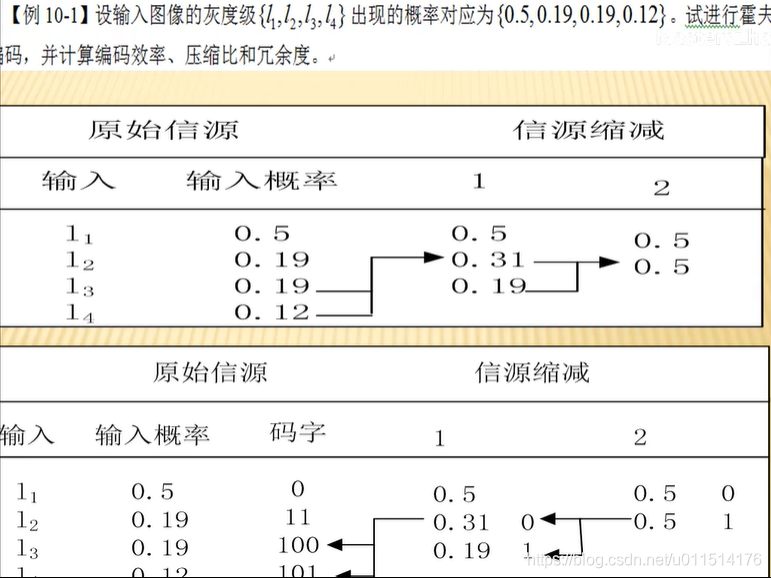
1.将信源符号按出现概率从大到小排成一列,然后把最末两个符号的概率相加,合成一个概率。
2.把这个符号的概率与其余符号的概率按从大到小排列,然后再把最末两个符号的概率加起来,合成一个概率。
3.重复上述做法,直到最后剩下两个概率为止。
4.从最后一步剩下的两个概率开始逐步反向进行编码。每步只需对两个分支各赋予一个二进制码,如对概率大的赋予码1,对概率小的赋予码O。

1.3 霍夫曼编码的源代码
1.3.1 fliplr 左右翻转矩阵函数,sort排序函数,find返回非零元素函数
fliplr(A)
将矩阵A的列绕垂直轴进行左右翻转 matabc
如果A是一个行向量,fliplr(A)将A中元素的顺序进行翻转。
如果A是一个列向量,fliplr(A)还等于A。
sort排序函数
sort(A):对一维或二维矩阵进行升序排序,并返回排序后的矩阵;当A为二维矩阵时,对矩阵的每一列分别进行排序。
sort(A,dim):对矩阵按指定的方向进行升序排序,并返回排序后的矩阵。当dim=1时,对矩阵的每一列排序(即将第一维行数打乱重排);当dim=2时,对矩阵的每一行排序(即将第二维列数打乱重排)。
sort(A,dim,mode):mode为’ascend’时,进行升序排序;mode为’descend’时,进行降序排序。相比于sort(A)可见默认升序,默认dim=1。
find返回非零元素函数

 返回前N个非零元素的位置,find(A,X)
返回前N个非零元素的位置,find(A,X)
返回最后一个非零值的位置find(A,1,‘last’)
返回最后一个非零值的行列位置或者A中非零元素位置
[a,b,v] = find(A),找出A中非零元素所在的行和列,分别存储在a和b中,并将结果放在v中。
%【例10-2】霍夫曼编码
close all; clear all; clc; %关闭所有图形窗口,清除工作空间所有变量,清空命令行
A=[0.5,0.19,0.19,0.12]; %信源消息的概率序列
A=fliplr(sort(A)); %按降序排列
T=A;
[m,n]=size(A);
B=zeros(n,n-1); %空的编码表(矩阵)
for i=1:n
B(i,1)=T(i); %生成编码表的第一列
end
r=B(i,1)+B(i-1,1); %最后两个元素相加
T(n-1)=r;
T(n)=0;
T=fliplr(sort(T));
t=n-1;
for j=2:n-1 %生成编码表的其他各列
for i=1:t
B(i,j)=T(i);
end
K=find(T==r);
B(n,j)=K(end); %从第二列开始,每列的最后一个元素记录特征元素在该列的位置
r=(B(t-1,j)+B(t,j)); %最后两个元素相加
T(t-1)=r;
T(t)=0;
T=fliplr(sort(T));
t=t-1;
end
B; %输出编码表
END1=str2sym('[0 ,1]'); %给最后一列的元素编码
END=END1;
t=3;
d=1;
for j=n-2:-1:1 %从倒数第二列开始依次对各列元素编码
for i=1:t-2
if i>1 & B(i,j)==B(i-1,j)
d=d+1;
else
d=1;
end
B(B(n,j+1),j+1)=-1;
temp=B(:,j+1);
x=find(temp==B(i,j));
END(i)=END1(x(d));
end
y=B(n,j+1);
END(t-1)=[char(END1(y)),'0'];
END(t)=[char(END1(y)),'1'];
t=t+1;
END1=END;
end
disp('排序后的原概率序列A:');
disp(A) %排序后的原概率序列
disp('编码结果END:')
disp(END) ; %编码结果
for i=1:n
[a,b]=size(char(END(i)));
L(i)=b;
end
disp('平均码字长度')
avlen=sum(L.*A);disp(avlen); %平均码长
H1=log2(A);
disp('信息熵')
H=-A*(H1');disp(H) %熵
disp('编码效率')
P=H/avlen;disp(P) %编码效率





















 5179
5179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









