






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
这里对容器启动中循环依赖的部分做一个学习总结
提示:以下是本篇文章正文内容,下面案例可供参考
一、什么是循环依赖?
假如有两个对象A和B,其中A依赖B并且B也依赖A,此时就产生了循环依赖
二、容器启动过程中有多少种循环依赖?
A和B的依赖关系有两种
1 set型依赖
2 构造器型依赖
在容器中bean的类型主要分两种
1 单例bean
2 多例bean
按上边的条件一共有四种组合,其中spring只解决了单例set型依赖,其他3种情况都是通过抛异常来处理的。
三、容器是如何解决循环依赖的
3.1 容器为什么要解决循环依赖问题?
假如容器需要创建两个对象A和B,并且A和B之间存在循环依赖关系,那么大致流程如下
1 创建A实例
2 进行对A实例的依赖注入,此时发现其依赖B对象,发现容器中还没有B对象
3 进行对B对象的创建,此时A对象还未初始化完成所以容器中还没有A对象
4 进行对B实例的依赖注入,此时发现其依赖A对象,发现容器中还没有A对象
5 创建A实例
6.进行对A实例的依赖注入,此时发现其依赖B对象,发现容器中还没有B对象
发现一个循环开始了
3.2 容器如何解决循环依赖问题?
主要原理就是使用了缓存技术,具体步骤如下
还是之前的场景 假如容器需要创建两个对象A和B,并且A和B之间存在循环依赖关系,那么大致流程如下
1 创建A实例 ,先将A实例缓存起来
2 进行对A实例的依赖注入,此时发现其依赖B对象,发现容器中还没有B对象
3 进行对B对象的创建,此时A对象还未初始化完成所以容器中还没有A对象
4 进行对B实例的依赖注入,此时发现其依赖A对象,发现容器中还没有A对象,于是去缓存中找并且找到了。于是B对象依赖注入完成
5 B对象注册到容器中
6 A对象完成对B对象的依赖注入
7 A对象注册到容器中
主要就是在第一步加了个缓存,第四步最终跳出了循环
原理比较简单,但是容器为了更好的扩展性和健壮性实际解决循环依赖的方法要相对复杂一些。采用了三级缓存技术
3.3 三级缓存在哪里
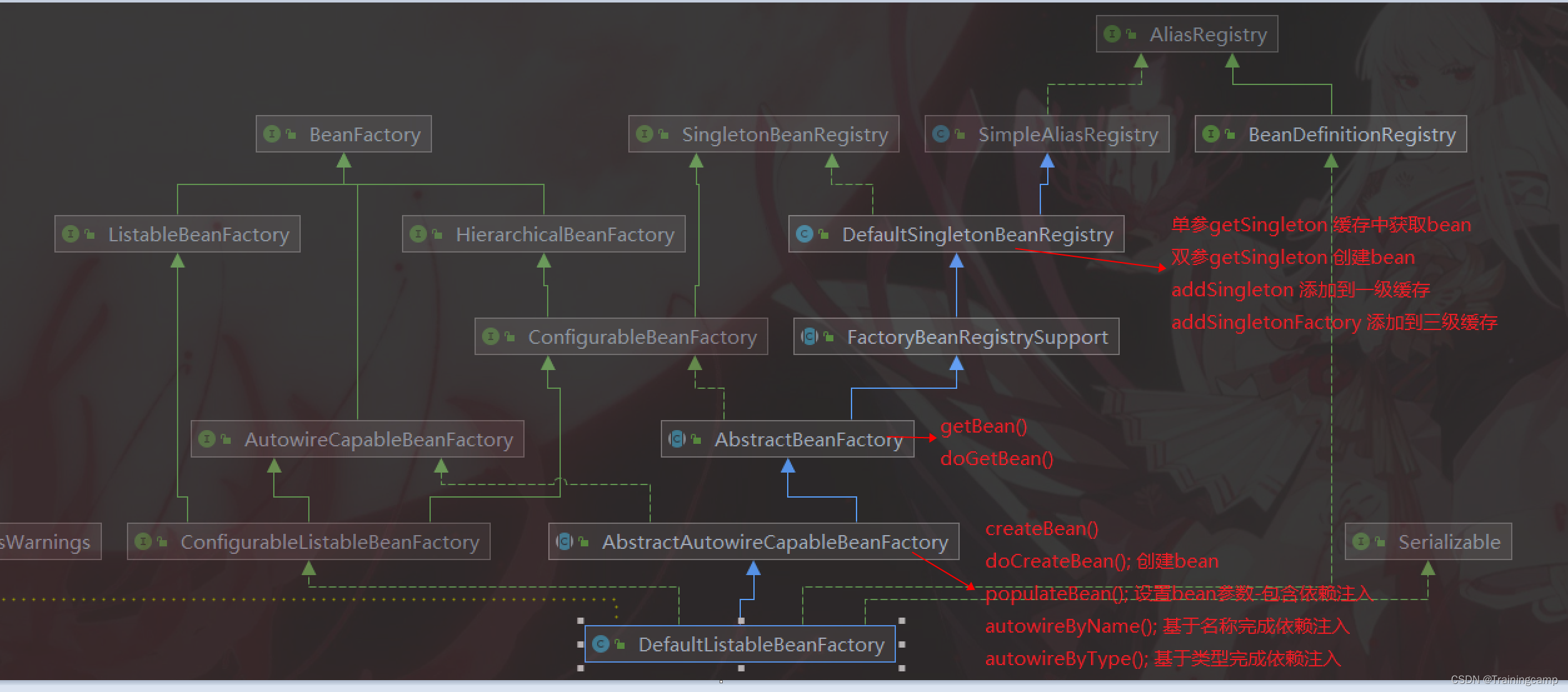
容器主要是通过DefaultSingletonBeanRegistry这个类来实现三级缓存的。有三个主要的成员变量对应的就是三级缓存。还有五个主要的方法,方法的主要作用就是将bean对象在不同阶段放到不同的缓存中
//解决循环依赖的核心类
public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry {
//一级缓存 用于保存初始化完成并且已经注册到容器中的bean
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
//二级缓存 用于保存还未初始化完成的bean
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
//三级缓存 用于保存还未初始化完成的bean
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
//核心方法1 获取缓存中的单例bean
// 这个方法在 AbstractBeanFactory.doGetBean中被用到了 先去缓存中获取bean 看有没有
public Object getSingleton(String beanName) {
return getSingleton(beanName, true);
}
//核心方法2 获取缓存中的单例bean
// 核心方法1调用的就是核心方法2 所以他俩算一个方法
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
//allowEarlyReference上边可以看出这个值是true
//如果一级缓存中有直接返回
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
//如果二级缓存中有 直接返回
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
//如果三级缓存中有
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
//获取真正需要的bean对象
singletonObject = singletonFactory.getObject();
//将其放到二级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
//清空三级缓存
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
//核心方法3 getSingleton的重载方法 用于单例bean的创建
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(beanName, "Bean name must not be null");
synchronized (this.singletonObjects) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
。。。省略代码
//给bean创建一个标记 表示这个bean正在被创建 还未创建完
beforeSingletonCreation(beanName);
。。。省略代码
try {
//创建单例bean 这里会进入到createBean方法中
singletonObject = singletonFactory.getObject();
newSingleton = true;
}
catch (IllegalStateException ex) {
。。。省略代码
}
catch (BeanCreationException ex) {
。。。省略代码
}
finally {
。。。省略代码
//去掉bean的正在创建标识
afterSingletonCreation(beanName);
}
if (newSingleton) {
//将bean添加到一级缓存
addSingleton(beanName, singletonObject);
}
}
return singletonObject;
}
}
//核心方法4 添加到一级缓存的处理逻辑
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
//将bean添加到一级缓存
this.singletonObjects.put(beanName, singletonObject);
//清空三级缓存
this.singletonFactories.remove(beanName);
//清空二级缓存
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
//核心方法5 添加三级缓存
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
//将一个表达式放入三级缓存
//三级缓存放入的是一个表达式 主要是为了支持动态代理
this.singletonFactories.put(beanName, singletonFactory);
//清空二级缓存
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
}
五个方法中有3个名字都叫getSingleton,比较容易混淆。这里稍微总结下。首先前两个getSingleton其实是一个方法,因为方法1啥也没干直接调用了方法2所以算一个。接下来的就是总结下这两个方法的区别。后边的别名在3.4中会用到,方便描述
| 方法 | 作用 | 别名 |
|---|---|---|
| getSingleton(String beanName) | 主要目的是从缓存中获取bean实例,获取顺序如下 1. 去一级缓存中获取bean实例 有返回 没有继续下一步 2. 去二级缓存中获取bean实例 有返回 没有继续下一步 3. 去三级缓存中获取bean实例工厂 如果没有返回空 如果有 【3.1 基于工厂创建实例】 【3.2 实例缓存到二级缓存】 【3.3 清空三级缓存中的实例】 | 单参getSingleton |
| getSingleton(String xxx, ObjectFactory<?> xxx) | 主要目的创建单例bean 1. 给即将要创建的bean加一个标记 后续会用到 2. 使用bean工厂创建单例bean 循环依赖主要就发生在这里 3. 将单例bean加入到一级缓存 | 双参getSingleton |
了解了这个类后边跟源码会舒服很多
3.4 假设一个场景跟随源码看看容器是如何解决循环依赖的
假设有两个单例非懒加载对象A和B需要在容器初始化后被创建,其中A依赖B并且B也依赖A。容器初始化时先实例化A对象
3.4.1从doGetBean方法开始了
首选需要创建A对象
protected <T> T doGetBean(final String name, @Nullable final Class<T> requiredType,
@Nullable final Object[] args, boolean typeCheckOnly) throws BeansException {
。。。省略代码
//这里调用了单参getSingleton 去各个缓存中取对象
Object sharedInstance = getSingleton(beanName);
//A对象还未创建所以缓存里没有 这个if不会进
if (sharedInstance != null && args == null) {
。。。省略代码
}
else {
。。。省略代码
try {
final RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);
checkMergedBeanDefinition(mbd, beanName, args);
。。。省略代码
// Create bean instance.
if (mbd.isSingleton()) {
//这里调用了双参getSingleton 创建单例bean
//可以看到第二个参数传入的表达式方法就是createBean,方法内部调用singletonFactory.getObject()就是执行createBean
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}
。。。省略代码
});
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
。。。省略代码
}
catch (BeansException ex) {
cleanupAfterBeanCreationFailure(beanName);
throw ex;
}
}
...省略代码
return (T) bean;
}
3.4.2跟进双参getSingleton方法
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(beanName, "Bean name must not be null");
synchronized (this.singletonObjects) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
。。。省略代码
//给A对象加一个创建标记 记住这个标记 后续会用这个标记判断
beforeSingletonCreation(beanName);
。。。省略代码
try {
//创建单例bean 这里会进入到createBean方法中 进入这里创建A对象
singletonObject = singletonFactory.getObject();
newSingleton = true;
}
catch (IllegalStateException ex) {
。。。省略代码
}
catch (BeanCreationException ex) {
。。。省略代码
}
finally {
。。。省略代码
//去掉bean的正在创建标识
afterSingletonCreation(beanName);
}
if (newSingleton) {
//将bean添加到一级缓存
addSingleton(beanName, singletonObject);
}
}
return singletonObject;
}
}
这个方法应该很熟悉啦,做了3件事
1 给A对象加一个创建标记 后续会用作判断
2 调用createBean创建A对象–我们继续跟这里
3 将完全体的A对象放到一级缓存中并返回A对象。
3.4.2跟doCreateBean方法
因为createBean最终会掉doCreateBean,所以直接跟doCreateBean
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
// Instantiate the bean.
。。。省略代码
//这里A对象实例创建完成
final Object bean = instanceWrapper.getWrappedInstance();
。。。省略代码
//还记得刚刚说的创建标记吗 这里就用到了判断
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
//有没有创建标记
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
。。。省略代码
//() -> getEarlyBeanReference(beanName, mbd, bean) 这个表达式其实是一个ObjectFactory对象 是一个工厂
//如果有创建标记将A对象封装到一个工厂中,在将工厂封装到三级缓存中
//这个工厂是为动态代理设计的,暂时理解拿到工厂即可拿到A对象的引用就行
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
// Initialize the bean instance.
Object exposedObject = bean;
try {
//初始化参数 依赖注入 跟这里
populateBean(beanName, mbd, instanceWrapper);
//bean实例初始化方法
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
catch (Throwable ex) {
。。。省略代码
}
。。。省略代码
//完全体的A对象 如果到这里 其实A和B对象
return exposedObject;
}
这个方法主要做了三件事
1 实例化A对象
2 基于标记判断,将A对象封装进工厂放入三级缓存
3 完成A对象的依赖注入
3.4.2跟populateBean方法
这里主要完成bean的依赖注入
protected void populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) {
。。。省略代码
PropertyValues pvs = (mbd.hasPropertyValues() ? mbd.getPropertyValues() : null);
int resolvedAutowireMode = mbd.getResolvedAutowireMode();
//依赖注入主要是@AUTOWIRE注解 所以看这个
if (resolvedAutowireMode == AUTOWIRE_BY_NAME || resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
MutablePropertyValues newPvs = new MutablePropertyValues(pvs);
// Add property values based on autowire by name if applicable.
if (resolvedAutowireMode == AUTOWIRE_BY_NAME) {
//跟autowireByName方法
autowireByName(beanName, mbd, bw, newPvs);
}
// Add property values based on autowire by type if applicable.
if (resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
//这个就不跟了 和上边的差不多
autowireByType(beanName, mbd, bw, newPvs);
}
pvs = newPvs;
}
。。。省略代码
3.4.2跟autowireByName方法
这里主要就是A对象发现需要依赖B对象,于是触发了对B对象的 getBean操作。
这波操作让流程又回到了起点
protected void autowireByName(
String beanName, AbstractBeanDefinition mbd, BeanWrapper bw, MutablePropertyValues pvs) {
String[] propertyNames = unsatisfiedNonSimpleProperties(mbd, bw);
for (String propertyName : propertyNames) {
if (containsBean(propertyName)) {
//这里发现A需要依赖B对象 于是对B对象调用getBean方法
Object bean = getBean(propertyName);
pvs.add(propertyName, bean);
registerDependentBean(propertyName, beanName);
。。。省略代码
}
else {
。。。省略代码
}
}
}
3.4.3整体流程在来一遍
这里简述下后边会发生的问题
1 getBean()发现对象B不存在
2 会调用到doCreateBean方法创建B对象
3 doCreateBean创建对象B时会对B进行依赖注入
4 又回到了上边的autowireByName方法 ,发现B对象需要依赖A对象,于是执行getBean 去拿对象A,哈哈看到这个方法!没错整体流程又要来一次
3.4.4整体流程在在来一遍
执行doGetBean()方法去拿对象A
这次会不太一样了,因为doGetBean会走另一个分支。循环依赖在这里被解决了
protected <T> T doGetBean(final String name, @Nullable final Class<T> requiredType,
@Nullable final Object[] args, boolean typeCheckOnly) throws BeansException {
。。。省略代码
//还记得单参getSingleton做了什么吗
//最终会将A对象从三级缓存中取出来,放到二级缓存并返回A对象的引用
Object sharedInstance = getSingleton(beanName);
//B对象还未创建所以缓存里没有 这个if不会进
if (sharedInstance != null && args == null) {
。。。省略代码
bean = getObjectForBeanInstance(sharedInstance, name, beanName, null);
}
//在缓存中取到A对象了 这个分支不会执行了
else {
。。。省略代码
}
catch (BeansException ex) {
cleanupAfterBeanCreationFailure(beanName);
throw ex;
}
}
...省略代码
return (T) bean;
}
后续流程简述下
1 回到autowireByName方法中,B对象顺利拿到A对象的引用 ,完成依赖注入
2 回到doGreateBean方法中,B对象的完全体被返回
3 回到双参getSingleton方法,B对象被放到了一级缓存中
4 又回到了autowireByName方法中,A对象顺利拿到B对象的引用 ,完成依赖注入
5 又回到doGreateBean方法中,A对象的完全体被返回
6 回到双参getSingleton方法,A对象被放到了一级缓存中
7 最终A和B两个对象都顺利的添加到了容器中
3.5 各个方法所在类
总结
1 知道什么是循环依赖
2 知道为什么要解决循环依赖
3 知道容器解决循环依赖的原理
4 知道容器解决循环依赖的过程















 3989
3989











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









