









参考:https://blog.csdn.net/Floatiy/article/details/80961870
Power Network
| Time Limit: 2000MS | Memory Limit: 32768K | |
| Total Submissions:30761 | Accepted: 15835 |
Description
A power network consists of nodes (power stations, consumers and dispatchers) connected by power transport lines. A node u may be supplied with an amount s(u) >= 0 of power, may produce an amount 0 <= p(u) <= pmax(u) of power, may consume an amount 0 <= c(u) <= min(s(u),cmax(u)) of power, and may deliver an amount d(u)=s(u)+p(u)-c(u) of power. The following restrictions apply: c(u)=0 for any power station, p(u)=0 for any consumer, and p(u)=c(u)=0 for any dispatcher. There is at most one power transport line (u,v) from a node u to a node v in the net; it transports an amount 0 <= l(u,v) <= lmax(u,v) of power delivered by u to v. Let Con=Σuc(u) be the power consumed in the net. The problem is to compute the maximum value of Con.
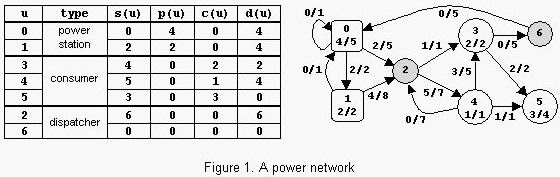
An example is in figure 1. The label x/y of power station u shows that p(u)=x and pmax(u)=y. The label x/y of consumer u shows that c(u)=x and cmax(u)=y. The label x/y of power transport line (u,v) shows that l(u,v)=x and lmax(u,v)=y. The power consumed is Con=6. Notice that there are other possible states of the network but the value of Con cannot exceed 6.
Input
There are several data sets in the input. Each data set encodes a power network. It starts with four integers: 0 <= n <= 100 (nodes), 0 <= np <= n (power stations), 0 <= nc <= n (consumers), and 0 <= m <= n^2 (power transport lines). Follow m data triplets (u,v)z, where u and v are node identifiers (starting from 0) and 0 <= z <= 1000 is the value of lmax(u,v). Follow np doublets (u)z, where u is the identifier of a power station and 0 <= z <= 10000 is the value of pmax(u). The data set ends with nc doublets (u)z, where u is the identifier of a consumer and 0 <= z <= 10000 is the value of cmax(u). All input numbers are integers. Except the (u,v)z triplets and the (u)z doublets, which do not contain white spaces, white spaces can occur freely in input. Input data terminate with an end of file and are correct.
Output
For each data set from the input, the program prints on the standard output the maximum amount of power that can be consumed in the corresponding network. Each result has an integral value and is printed from the beginning of a separate line.
Sample Input
2 1 1 2 (0,1)20 (1,0)10 (0)15 (1)20
7 2 3 13 (0,0)1 (0,1)2 (0,2)5 (1,0)1 (1,2)8 (2,3)1 (2,4)7
(3,5)2 (3,6)5 (4,2)7 (4,3)5 (4,5)1 (6,0)5
(0)5 (1)2 (3)2 (4)1 (5)4
Sample Output
15 6
Hint
The sample input contains two data sets. The first data set encodes a network with 2 nodes, power station 0 with pmax(0)=15 and consumer 1 with cmax(1)=20, and 2 power transport lines with lmax(0,1)=20 and lmax(1,0)=10. The maximum value of Con is 15. The second data set encodes the network from figure 1.
Source
引入
Ek的核心是执行bfs,一旦找到增广路就停下来进行增广。换言之,执行一遍BFS执行一遍DFS,这使得效率大大降低。于是我们可以考虑优化。
核心思路
在一次BFS中,找到的增广路可能不止一条,这时我们可以本着“尽量少进行BFS”的想法,在一次bfs后把所有能增广的路径全部增广。
具体怎么做呢?
仍然是:
while(bfs(源点,汇点)) dfs();每次bfs标记出每个点的“深度”,也就是距离源点的长度。我们将得到的新图称作分层图。接下来我们在分层图上进行增广,把能增广的路径全部增广。
其它部分和Ek大体相同。关于当前弧优化
其实是一个很强的优化
每次增广一条路后可以看做“榨干”了这条路,既然榨干了就没有再增广的可能了。但如果每次都扫描这些“枯萎的”边是很浪费时间的。那我们就记录一下“榨取”到那条边了,然后下一次直接从这条边开始增广,就可以节省大量的时间。这就是 当前弧优化 。
具体怎么实现呢,先把链式前向星的head数组复制一份,存进cur数组,然后在cur数组中每次记录“榨取”到哪条边了。
Code
//by floatiy #include<iostream> #include<cstdio> #include<algorithm> #include<queue> using namespace std; const int MAXN = 10000 + 5; const int MAXM = 100000 + 5; const int INF = 1e9; int n,m; int s,t;//源点 汇点 int maxflow;//答案 struct Edge { int next; int to,flow; } l[MAXM << 1]; int head[MAXN],cnt = 1; int deep[MAXN],cur[MAXN];//deep记录bfs分层图每个点到源点的距离 queue <int> q; inline void add(int x,int y,int z) { cnt++; l[cnt].next = head[x]; l[cnt].to = y; l[cnt].flow = z; head[x] = cnt; return; } int min(int x,int y) { return x < y ? x : y; } int dfs(int now,int t,int lim) {//分别是当前点,汇点,当前边上最小的流量 if(!lim || now == t) return lim;//终止条件 // cout<<"DEBUG: DFS HAS BEEN RUN!"<<endl; int flow = 0; int f; for(int i = cur[now]; i; i = l[i].next) {//注意!当前弧优化 cur[now] = i;//记录一下榨取到哪里了 if(deep[l[i].to] == deep[now] + 1 //谁叫你是分层图 && (f = dfs(l[i].to,t,min(lim,l[i].flow)))) {//如果还能找到增广路 flow += f; lim -= f; l[i].flow -= f; l[i ^ 1].flow += f;//记得处理反向边 if(!lim) break;//没有残量就意味着不存在增广路 } } return flow; } bool bfs(int s,int t) { for(int i = 1; i <= n; i++) { cur[i] = head[i];//拷贝一份head,毕竟我们还要用head deep[i] = 0x7f7f7f7f; } while(!q.empty()) q.pop();//清空队列 其实没有必要了 deep[s] = 0; q.push(s); while(!q.empty()) { int tmp = q.front(); q.pop(); for(int i = head[tmp]; i; i = l[i].next) { if(deep[l[i].to] > INF && l[i].flow) {//有流量就增广 //deep我赋的初值是0x7f7f7f7f 大于 INF = 1e9) deep[l[i].to] = deep[tmp] + 1; q.push(l[i].to); } } } if(deep[t] < INF) return true; else return false; } void dinic(int s,int t) { while(bfs(s,t)) { maxflow += dfs(s,t,INF); // cout<<"DEBUG: BFS HAS BEEN RUN!"<<endl; } } int main() { cin>>n>>m;//点数边数 cin>>s>>t; int x,y,z; for(int i = 1; i <= m; i++) { scanf("%d%d%d",&x,&y,&z); add(x,y,z); add(y,x,0); } // cout<<"DEBUG: ADD FININSHED!"<<endl; dinic(s,t); printf("%d",maxflow); return 0; }
我的代码 (POJ挂了 待测)
#include <iostream>
#include <cstdio>
#include <cstring>
#include <vector>
#include <queue>
using namespace std;
int N, NP, NC, M, cnt;
struct Edge
{
int to, cap, next;
} edges[150 * 150];
int R, S, T;
int dis[109];
int current[109];
int head[109];
void addedge(int fr, int to, int cap)
{
edges[cnt].to = to;
edges[cnt].cap = cap;
edges[cnt].next = head[fr];
head[fr] = cnt++;
}
int BFS()
{
queue<int> q;
q.push(S);
memset(dis, 0x3f, sizeof(dis));
dis[S] = 0;
while (!q.empty())
{
int h = q.front();
q.pop();
for (int i = head[h]; i != -1; i = edges[i].next)
{
if (edges[i].cap > 0 && dis[edges[i].to] == 0x3f3f3f3f)
{
dis[edges[i].to] = dis[h] + 1;
q.push(edges[i].to);
}
}
}
return dis[T] < 0x3f3f3f3f; // 返回是否能够到达汇点
}
int dinic(int x, int maxflow)
{
if (x == T)
return maxflow;
// i = current[x] 当前弧优化
for (int i = current[x]; i != -1; i = edges[i].next)
{
current[x] = i;
if (dis[edges[i].to] == dis[x] + 1 && edges[i].cap > 0)
{
int flow = dinic(edges[i].to, min(maxflow, edges[i].cap));
if (flow)
{
edges[i].cap -= flow; // 正向边流量降低
edges[i^1].cap += flow; // 反向边流量增加
return flow;
}
}
}
return 0; // 找不到增广路 退出
}
int DINIC()
{
int ans = 0;
while (BFS()) // 建立分层图
{
int flow;
for (int i=0; i<cnt; i++){
current[i] = head[i];
}
while (flow = dinic(S, 0x3f3f3f3f)) // 一次BFS可以进行多次增广
ans += flow;
}
return ans;
}
int main()
{
while (scanf("%d%d%d%d", &N, &NP, &NC, &M) != EOF)
{
R = 0;
S = N;
T = N + 1;
memset(head, -1, sizeof(head));
cnt = 0;
for (int i = 0; i < M; i++)
{
int u, v, cap;
scanf(" (%d,%d)%d", &u, &v, &cap);
addedge(u, v, cap);
addedge(v, u, 0);
}
for (int i = 0; i < NP; i++)
{
int u, p;
scanf(" (%d)%d", &u, &p);
addedge(S, u, p);
addedge(u, S, 0);
}
for (int i = 0; i < NC; i++)
{
int u, c;
scanf(" (%d)%d", &u, &c);
addedge(u, T, c);
addedge(T, u, 0);
}
/*
for (int i=0; i<cnt; i++){
printf("edges[%d].to = %d .cap = %d\n", i, edges[i].to, edges[i].cap);
}
*/
printf("%d\n", DINIC());
}
return 0;
}















 1270
1270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









