







前一篇文章介绍了如何通过元素的id值来定位web元素,本文介绍如何通过tag name来定位元素。个人认为,通过tag name来定位还是有很大缺陷,定位不够精确。主要是tag name有很多重复的,造成了选择tag name来定位页面元素不准确,所以使用这个方法定位web元素的机会很少。
什么是tag name? 还是以百度首页搜索输入框,在火狐浏览器,右键,通过firepath,检查元素,看下图:
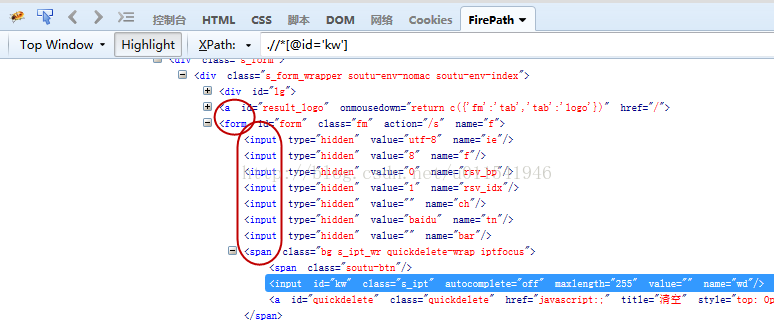
上面图片中红色圈选区域的标签名称都是tag name;实际上我们目标元素是输入框,应该是input这个tag name,在图中蓝色高亮区域。但是如果只是通过input这个tag name来定位,发现上面有很多input的选项。所以我们扩大节点的参照选择,我们选择上面这个form来作为我们tag name。
看看如何写定位form这个元素的脚本:
# coding=utf-8
from selenium import webdriver
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(6)
driver.get("https://www.baidu.com")
try:
driver.find_element_by_tag_name("form")
print ('test pass: tag name found')
except Exception as e:
print ("Exception found", format(e))
driver.quit()测试结果:
test pass: tag name found
总结:本文介绍了webdriver 八大定位元素方法中的
从实际项目中自动化脚本开发来看,使用这个方法定位元素的机会比较少,知道有这么一种方法就好了。driver.find_element_by_tag_name("form") # form是tag name

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









