







前面博客分析了,设置的时候,如果参数里面包含有–rerunfailed选项,那么就会去收集失败的用例,并放到case执行的列表当中的, 那么具体收集过程是怎么样子的了,大体过程如下:
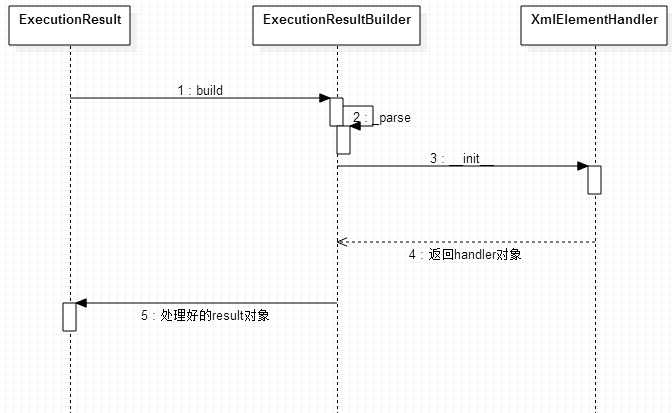
首先, 要达到的目标是, ExecutionResult 会依赖于 ExecutionResultBuilder 并通过它的build方法,生成一个Result对象,最后通过访问者模式来操作Result对象,这里主要访问它来获取失败的case。
其次,在整个oupxml分析的过程中是用到XmlElementHandler类, 它通过一个列表维持着当前的handler来处理遇到的xml节点,每个节点的开始会生成一个handler加入到列表中,每个节点处理完成后会从列表中pop这个handler,每个节点都有与之对应的handler,它们通过名字关联起来,XmlElementHandler采用了fascade模式,无需知道它内部是如何来处理的,只要把result对象给它,然后遍历xml节点,最后就回得到一个处理好
result对象,这些handler会自动根据名字来处理节点,并把结果放到result对象当中。
一个简单的顺序图如下:
而这里做的比较巧妙的是,充分利用python自省的特性,将handler与xml节点进行关联,可以通过pycharm生成一个类关系图,可以看到除了包含一些在settings, keyword, tescase等的hander之外,还有一些别的handler,如doc handler 因为output.xml中有什么样的元素,就必需有其对应的handler

在handler处理的过程当中,如何知道当前是哪个handler在处理,是根据XmlElementHandler当中的_stack来维系的,_stack是一个列表,但每次都返回其最后一个元素,模拟栈的存储方式,后进先出。 其实这符合xml的节点分解方式,如以下面的关键字解析为例
...
<kw type="kw" name="common.Get_Token">
<doc>每个测试集执行前都必需获取对应的token</doc>
<arguments>
<arg>${username}</arg>
<arg>${password}</arg>
</arguments>
<kw type="kw" name="RequestsLibrary.Create Session">
<doc>Create Session: create a HTTP session to a server</doc>
<arguments>
<arg>TOKEN_SESSION</arg>
<arg>${URL}</arg>
</arguments>
<msg timestamp="20150605 11:34:57.786" level="DEBUG">Creating session: TOKEN_SESSION</msg>
<msg timestamp="20150605 11:34:57.787" level="INFO">Argument types are:
<type 'bool'></msg>
<status status="PASS" endtime="20150605 11:34:57.787" starttime="20150605 11:34:57.785"></status>
</kw>
...具体解析过程如下:
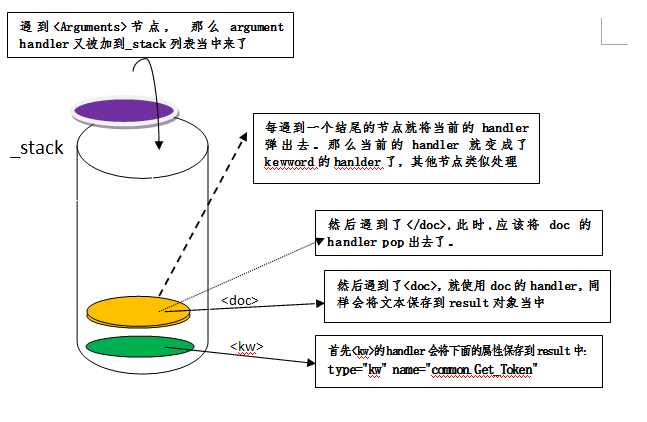
注: 这种解析方式,属于sax解析方式,用到内存非常少,而且很快,因此不论output.xml多大,都可以解析出来。
下面是主要的解析代码:
def build(self, result):
# Parsing is performance optimized. Do not change without profiling!
handler = XmlElementHandler(result)
with self._source as source:
self._parse(source, handler.start, handler.end)
result.handle_suite_teardown_failures()
if not self._include_keywords:
result.suite.visit(RemoveKeywords())
return result
def _parse(self, source, start, end):
context = ET.iterparse(source, events=('start', 'end'))
if not self._include_keywords:
context = self._omit_keywords(context)
elif self._flattened_keywords:
context = self._flatten_keywords(context, self._flattened_keywords)
for event, elem in context:
if event == 'start':
start(elem)
else:
end(elem)
elem.clear()如果不理解xml的解析过程,下面是一个简单的iterparse例子:
#将xml转换成csv文件
import csv
from xml.etree.ElementTree import iterparse
import sys
writer = csv.writer(sys.stdout, quoting=csv.QUOTE_NONNUMERIC)
group_name = ''
for (event, node) in iterparse('podcasts.opml', events=['start']):
if node.tag != 'outline':
# Ignore anything not part of the outline
continue
if not node.attrib.get('xmlUrl'):
# Remember the current group
group_name = node.attrib['text']
else:
# Output a podcast entry
writer.writerow( (group_name, node.attrib['text'],
node.attrib['xmlUrl'],
node.attrib.get('htmlUrl', ''),
)
)当得到了result对象之后, 是需要它里面的测试用例的状态信息的,
Result中只有suite
def __init__(self, source=None, root_suite=None, errors=None):
#: Path to the XML file where results are read from.
self.source = source
#: Hierarchical execution results as a
#: :class:`~.result.testsuite.TestSuite` object.
self.suite = root_suite or TestSuite()
#: Execution errors as a
#: :class:`~.executionerrors.ExecutionErrors` object.
self.errors = errors or ExecutionErrors()
self.generated_by_robot = True
self._status_rc = True
self._stat_config = {}所以要通过suite的visit方法来访问test case的相关信息:
def visit(self, visitor):
visitor.visit_suite(self)因此最后在gather方法中,将visitor传进去就可以了
def gather_failed_tests(output):
if output.upper() == 'NONE':
return []
gatherer = GatherFailedTests() # 需要实现的访问者
try:
ExecutionResult(output, include_keywords=False).suite.visit(gatherer) # 将访问者传进去
if not gatherer.tests:
raise DataError('All tests passed.')
except:
raise DataError("Collecting failed tests from '%s' failed: %s"
% (output, get_error_message()))
return gatherer.tests最后实现visitor,它需要是SuiteVisitor的子类, 然后实现自己的visit_test方法
class GatherFailedTests(SuiteVisitor):
def __init__(self):
self.tests = []
def visit_test(self, test):
if not test.passed: # 实现自己的visit_test来收集失败的测试用例
self.tests.append(test.longname)
def visit_keyword(self, kw):
pass














 2359
2359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









