







WordCount:
简单解析wordcount小例子的代码,对应于新版的API进行处理。
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.examples.WordCount.TokenizerMapper;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
/**
* @param
* @XD 2014-8-16
*/
public static class TokenzierMapper extends Mapper<Object,Text,Text,IntWritable>{
//对于切下的单词赋予出现频数1
private final static IntWritable one = new IntWritable(1);
//存储切下的单词
private Text word = new Text();
public void map(Object key,Text value,Context context) throws IOException, InterruptedException{
//StringTokenizer 对输入单词进行切分
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()){
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
//存取对应单词总频数
private IntWritable result = new IntWritable();
public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException{
//计算频数
int sum = 0;
for(IntWritable value:values){
sum+=value.get();
}
result.set(sum);
//写入输出
context.write(key, result);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
//初始化配置
Configuration conf = new Configuration();
Job job = new Job(conf,"word count");
job.setJarByClass(WordCount.class);
//设置map,combine,reduce处理
job.setMapperClass(TokenizerMapper.class);
job.setReducerClass(IntSumReducer.class);
job.setCombinerClass(IntSumReducer.class);
//设置输出格式处理类
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输入输出路径
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
System.out.println("任务名称: "+job.getJobName());
System.out.println("任务成功: "+(job.isSuccessful()?"Yes":"No"));
}
}
在eclipse中实现此过程,需要先导入自己hadoop安装目录下面的jar包,eclipse导入jar如下:
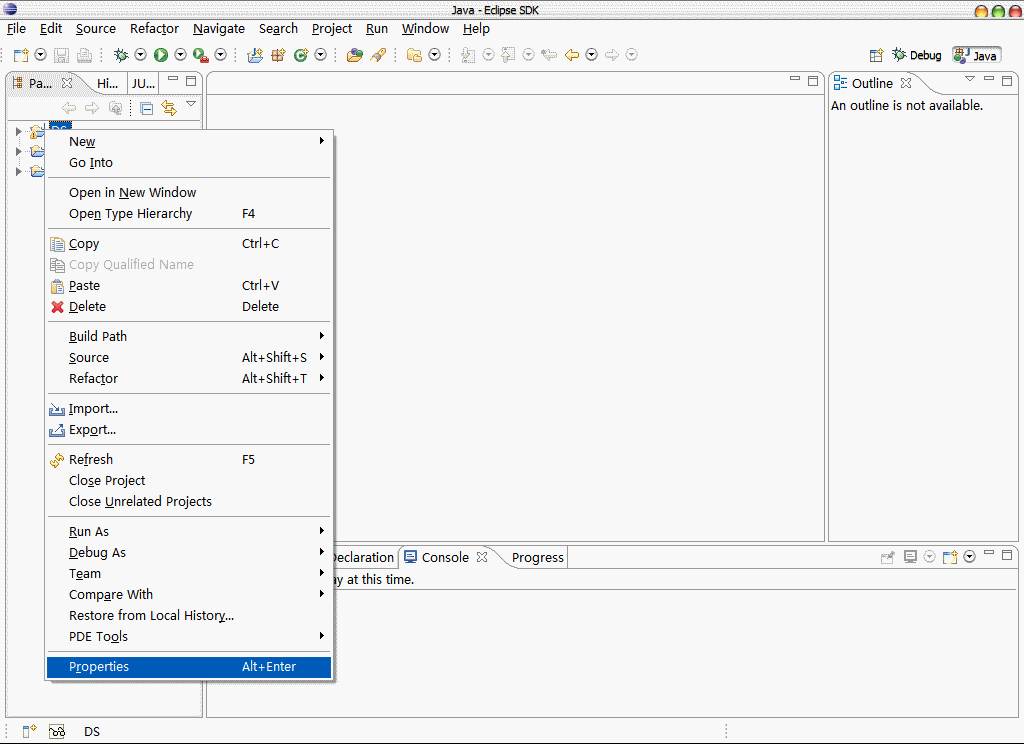
1.右击工程的根目录,点击Properties进入Properties。或者选中工程根目录,按Alt-Enter即可。
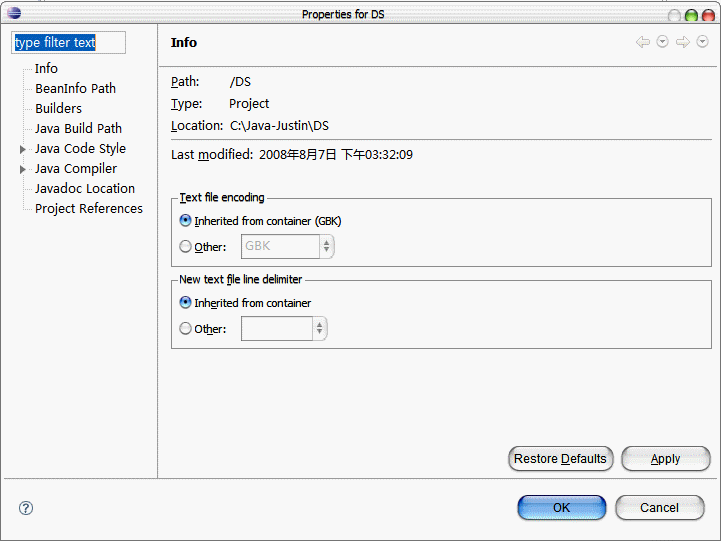
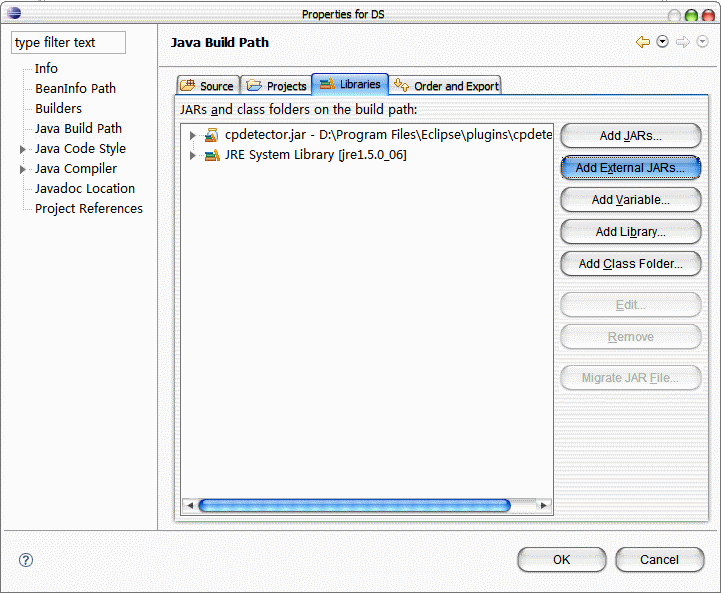
2.在Properties页面中选中Java Build Path,选中Libraries标签,点击Add External JARs。
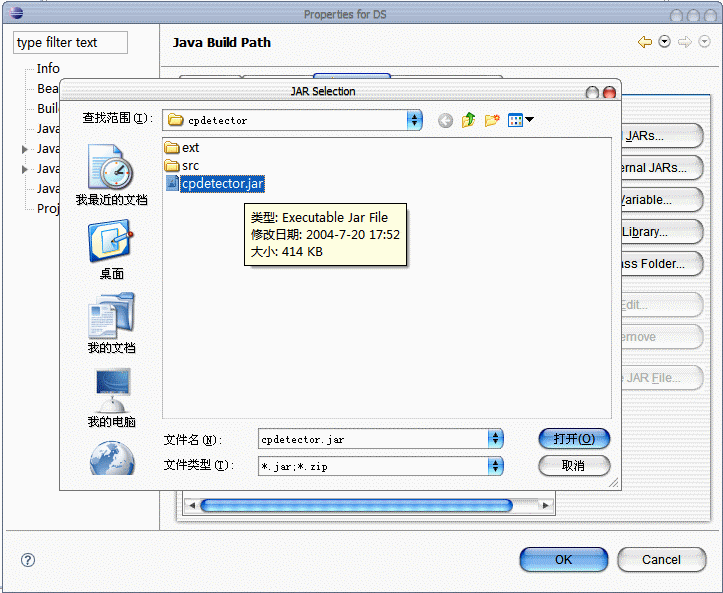
3.找到需要添加的jar包,确定即可。















 222
222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









