







- 目的
根据hive表中的多个字段创建一个json字符串,因此需要实现一个udf - 创建udf
package com.ke.search_reco.toJson;
import com.alibaba.fastjson.JSON;
import org.apache.hadoop.hive.ql.exec.UDF;
import java.util.HashMap;
import java.util.Map;
public class toJsonStr extends UDF {
public String evaluate(String... args) {
Map<String, String> res = new HashMap<>();
for(int i=0;i<args.length;i+=2) {
res.put(args[i], args[i+1]);
}
return JSON.toJSONString(res);
}
}
3.pom.xml中添加依赖
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.70</version>
</dependency>
</dependencies>
<build>
<plugins>
<!--以下配置是为了保证打jar包时相关依赖一同打包-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
4.通过maven打jar包
(1)点击idea右侧maven (2)点击package
(2)点击package
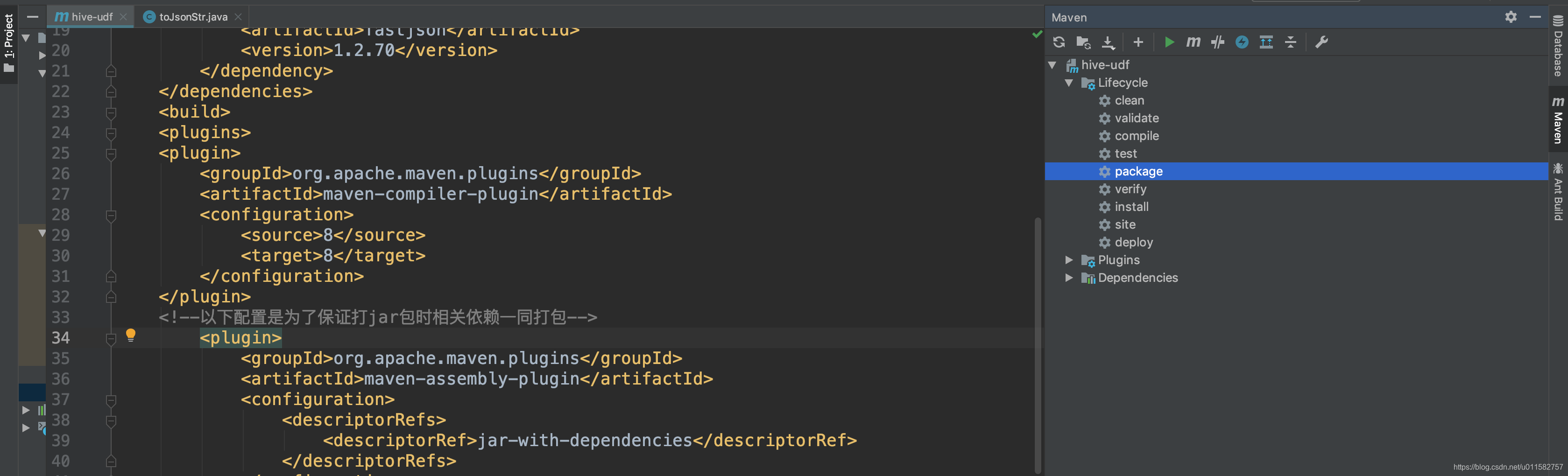 (3)运行后在target目录下生成两个jar文件,一个是带依赖的jar文件,另一个是不带依赖的jar文件
(3)运行后在target目录下生成两个jar文件,一个是带依赖的jar文件,另一个是不带依赖的jar文件
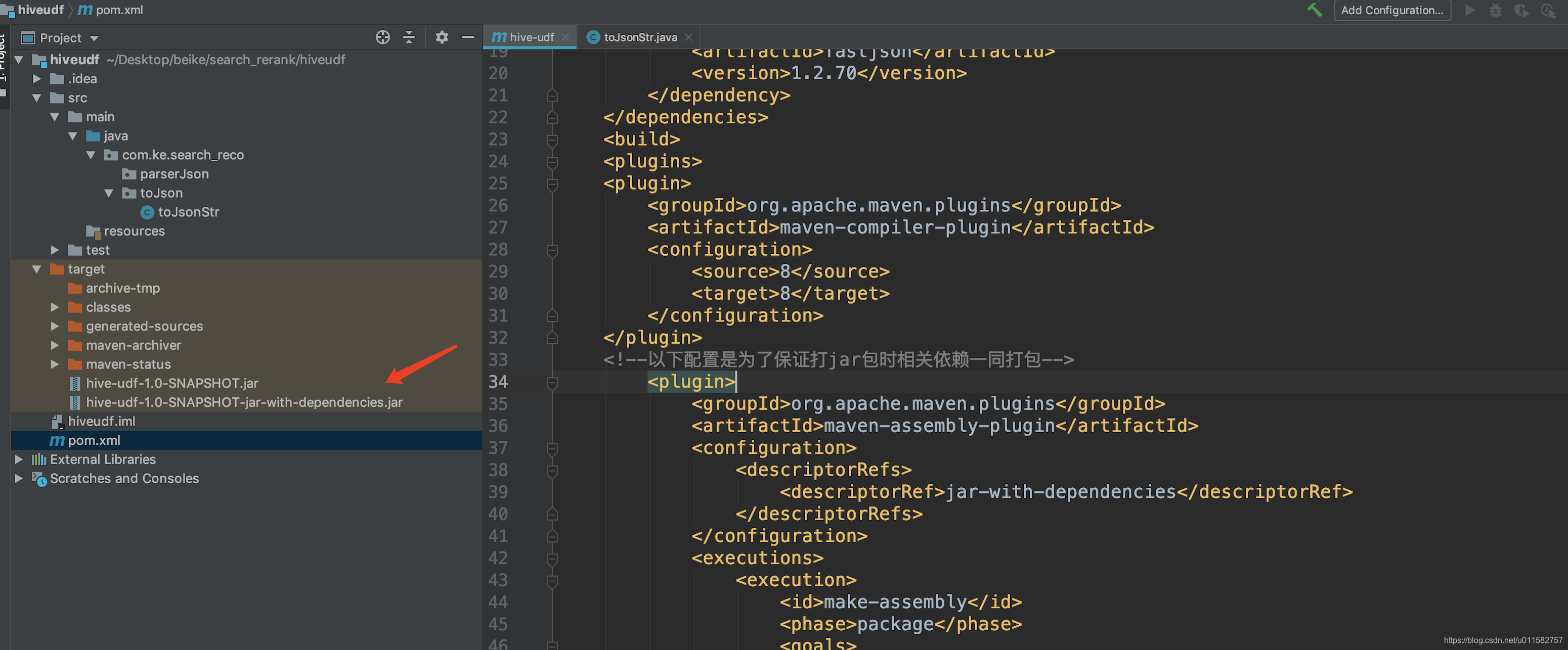
5.将带依赖的jar文件put到hdfs任意目录
hadoop fs -put hive-udf-1.0-SNAPSHOT-jar-with-dependencies.jar /user/lip/tools/
6.在hive sql中使用udf
add jar /user/lip/tools/hive-udf-1.0-SNAPSHOT-jar-with-dependencies.jar;
create temporary function toJsonStr as 'com.ke.search_reco.toJson.toJsonStr';
select
id,
toJsonStr(
'key_1', col_1,
'key_2', col_2)
from test_tb














 3173
3173











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









