






 H2O框架是一款强大的机器学习平台,支持多种算法包括深度学习,并能与Spark整合。它能够处理HDFS、S3、SQL及NoSQL数据,利用Hadoop和Spark作为计算引擎,提供基于内存的MapReduce计算,以及快速的查询和评分引擎。
H2O框架是一款强大的机器学习平台,支持多种算法包括深度学习,并能与Spark整合。它能够处理HDFS、S3、SQL及NoSQL数据,利用Hadoop和Spark作为计算引擎,提供基于内存的MapReduce计算,以及快速的查询和评分引擎。
1. H2O框架
优势:自己实现分布式计算框架,算法种类全,有深度学习算法,同时可以通过Sparkling-water将 h2o 和spark 进行完美整合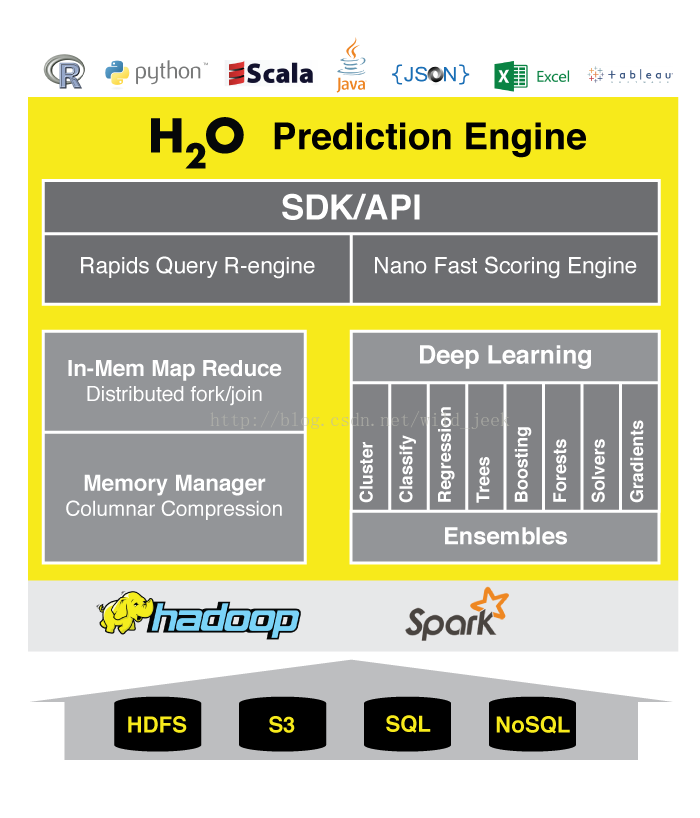
a.底层数据层
底层数据读取Hdfs数据 s3数据 SQL 数据 noSQL数据
s3Amazon Simple Storage Service 亚马逊的云存储结构
Hive其实就是读取HDFS
noSQL:HBase
HQL是一种类SQL语言,这种语言最终被转化为Map/Reduce.虽然Hive提供了SQL查询功能,但是Hive不能够进行交互查询--因为它只能够在Haoop上批量的执行Hadoop 便利全部数据速度慢 老版本不支持更新操作
Hbase的能够在它的数据库上实时运行,而不是运行MapReduce任务在Hbase中,行是key/value映射的集合,这个映射通过row-key来唯一标识。Hbase利用Hadoop的基础设施,可以利用通用的设备进行水平的扩展。
Hive可以用来进行统计查询,HBase可以用来进行实时查询
b. 计算引擎层
hadoop spark
在hadoop中使用mapreduce 所起的任务只是Map任务
使用sparkling-water将H2O和Spark进行整合
c. 核心运算层
算法引擎:深度学习
计算引擎:基于内存的MapReduce 使用分布式的fork/join框架(java并行框架) 内存管理引擎 :采用列式压缩ColumnarCompression
d.接口层
SDK和 REST API
快速查询R引擎 毫秒级评分引擎
---------------------
作者:wild_jeek
来源:CSDN
原文:https://blog.csdn.net/wild_jeek/article/details/71108347
版权声明:本文为博主原创文章,转载请附上博文链接!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









