






01
我们面临的问题
1.1
现状
Shopee 是一家电子商务公司,我们为世界各地的人们提供服务,每天都会产生数 TB 级的数据。Shopee 一直致力于构建大数据平台,为业务提供数据支持。我们提供了涵盖数据开发整个生命周期的多种工具。
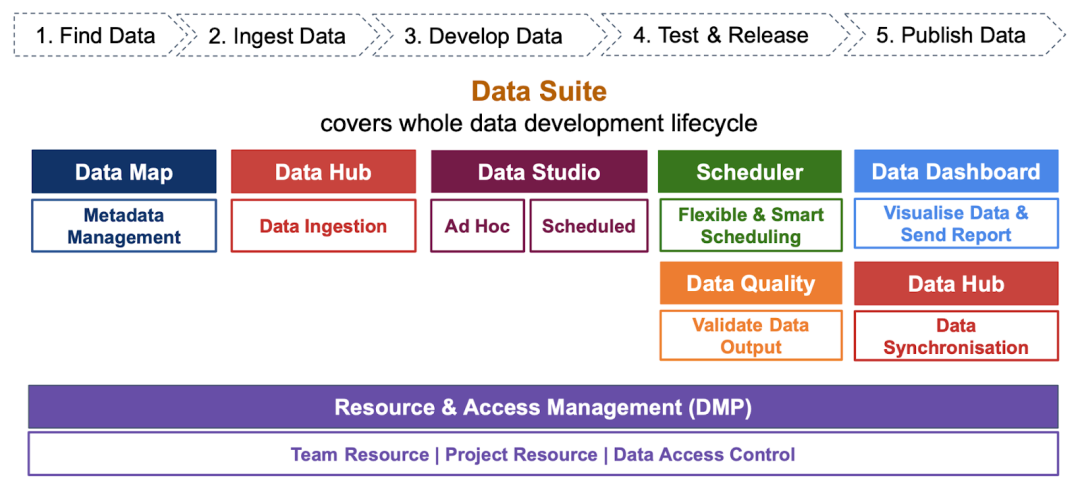
用户可以在 Datahub 中管理数据获取作业,还可以浏览数据,并用从 DataStudio 中获取的数据来创建不标准的数据管道。在 Datahub 或 DataStudio 中创建作业后,调度程序将按预期在特定时间运行这些作业。目前,平台上每天会创建并运行数以万计的作业,包括在 Datahub 中运行的批量获取和实时连续数据获取。
目前为止一切看起来都不错,但仍有许多不在我们平台上管理,且无法迁移到我们平台中的作业。因此,创建和维护、管理这些作业非常耗时,导致我们经常无法及时交付工作。
1.2
多种数据来源
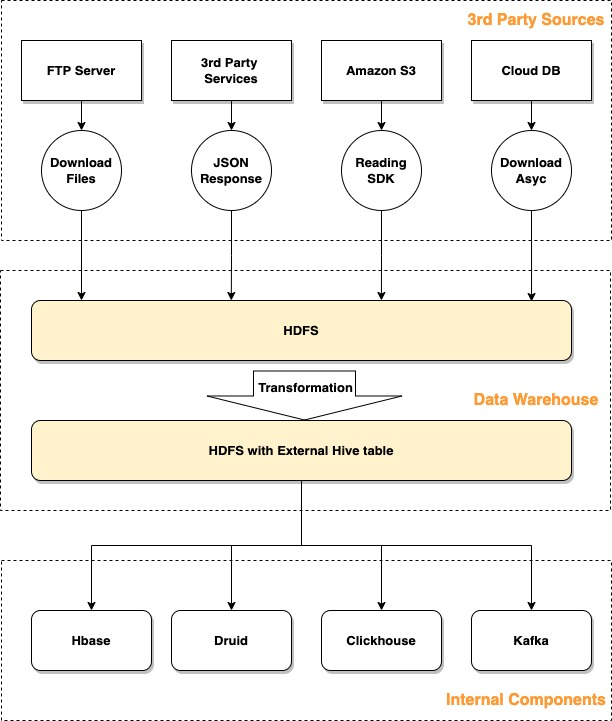
导致我们延误的原因很多。
首先,数据获取类型的作业请求很频繁,但其支持的数据源有限,主要包括 MySQL 和 TiDB。其次,数据源必须标准化,这就需要用 DBA 来管理,以保证分表名称遵循一定的规定,并且架构不会经常更改。然而,因为大量数据存储在不同地区,我们无法在短时间内构建标准化的产品。如上图所示,这些非标准数据源(第三方源)包括 FTP、API、S3、CloudDB 等。
除了从外部源将数据导入 Hive 之外,许多团队还使用 Clickhouse 和 Druid 等大数据存储。这些组件中的数据通常是从 Hive 导出的,但有些还需要把数据下沉到 Hive。目前,这些组件都有独立的传输组件,对应不同的代码库,这给开发人员在沟通和理解流程上带来了很多麻烦。
1.3
数据处理的多样性
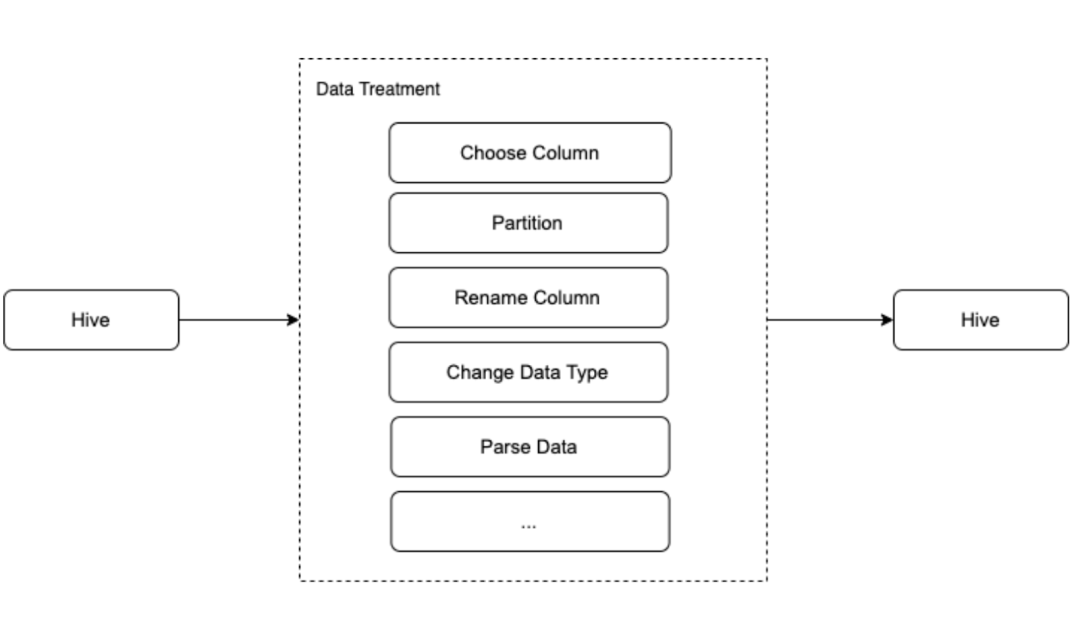
由于系统复杂,还有各种数据清理和处理的请求我们无法满足。来自生产环境的原始数据在分析之前必须经过数据清理,而每个传输组件进行数据清理的过程不同让问题变得复杂。
其次,用户构建数据仓库并不方便。目前,DataStudio 中的所有数据处理都是由用户自行维护,需要大量的数据处理工作。但大多数用户仍在直接使用数据获取的 ODS 表,缺乏统一的方式来构建 DW 表。
最后,复杂的数据转换必须通过开发对应的独立管道来进行,例如连接不同表或不同类型源的 SQL 作业。
1.4
总结
总结起来,我们面临的问题主要有:
对用户不友好
维护过程不透明
需要长时间等待请求完成
目标表需要用户手动请求和创建,数据存储之间的数据转换需要具有开发能力的用户手动完成。
对于开发人员来说效率不高
自建数据转换管道不可复现、耗时长且难以调试
维护工作量大
其他问题
数据处理工作量大,BI 团队无法在短时间内建立数据仓库,导致 BI 团队仍在使用原始数据
以非标准方式处理每个任务数据,缺乏统一的数据指标管理
02
为什么选择 Apache SeaTunnel
2.1
解决方案对比
我们开始寻找开源的解决方案,避免重复造轮子。为了解开源工具的利弊和边界,我们在选型之前做了一些对比研究。
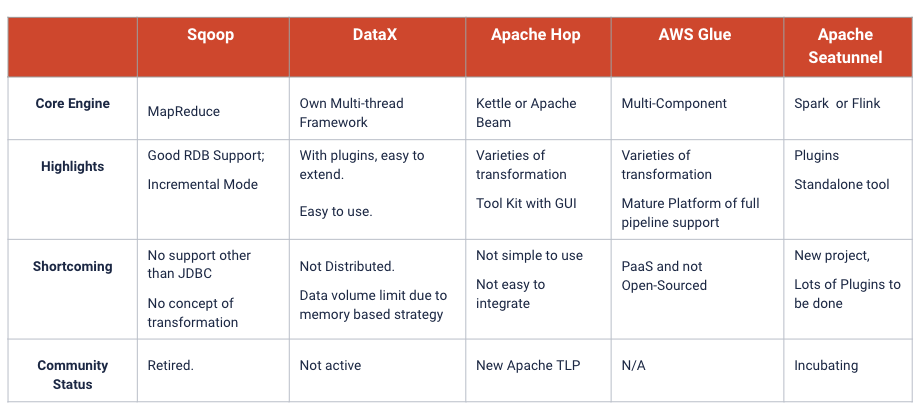
Sqoop 虽然是“老牌”,但只支持关系型数据库,很难处理分表。此外,它已经“退役”,这意味着 Apache 社区不会有进一步的支持。
DataX 是阿里巴巴内部广泛使用的数据同步工具。优势是易于使用且易于使用插件进行扩展。但是开源版本缺乏分布式能力,且内存使用策略会给单机带来很大压力。
Apache Hop 是一个基于 Kettle 或 Apache Beam 的“新星”,很多方面看起来都不错,但对我们来说太重了,它旨在创建一个一站式的数据处理平台,但我们需要的是一个轻量级的工具。
AWS Glue 也是同样的原因,甚至不开源,被我们 pass 了。
接着是对 Apache SeaTunnel 进行评估。
2.2
Apache SeaTunnel 简介
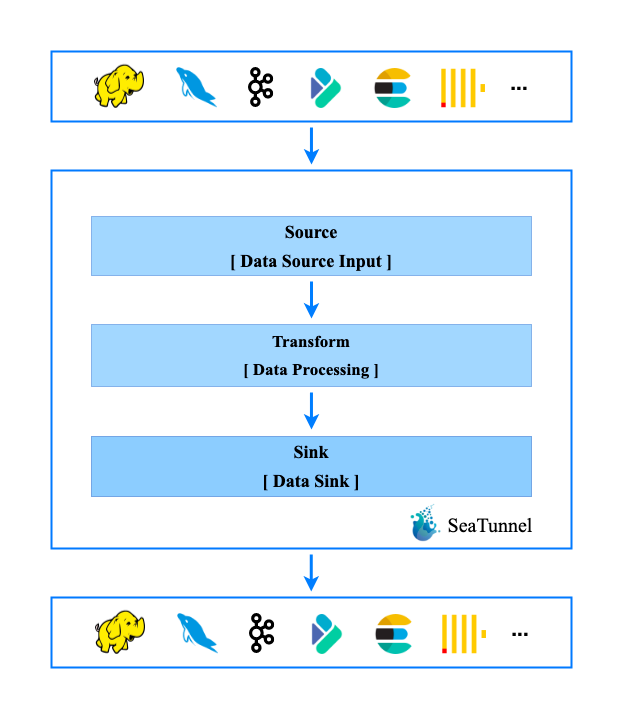
Apache SeaTunnel 是一款非常好用的超高性能分布式数据集成工具,支持海量数据的实时同步。因为使用了 java SPI 机制,SeaTunnel 可以方便地进行扩展,这正是我们所渴望的。
总的来说,Apache SeaTunnel 是一款功能强大、可扩展且易于使用的,适合所有平台的数据获取工具:
易于编辑配置并开箱即用地运行作业。
支持 Spark 或 Flink 引擎。
可以添加和更新 Source/ Sink Connector。
社区非常活跃。
SeaTunnel 应用程序的配置非常简洁。环境定义了 Spark 相关或 Flink 相关的环境设置。Source 定义数据的来源。Transform 定义了结果数据。Sink 定义了数据写入的位置和方式。
03
使用内部 SeaTunnel 版本进行重构
3.1
让端用户能够使用 SeaTunnel
在向用户提供正式服务之前,我们希望用户 可以尽快自己上手。我们选择用 Spark Engine 这个临时的解决方案。
这个方案需要用户在运行SeaTunnel(2.0.5 版本)前做一些准备工作:
一个上传 SeaTunnel jar 文件的地方,且部署前必须经过测试。
在测试期间,用户需要创建并更新 SeaTunnel 的应用程序配置文件。
此外,团队合作和管理很重要,用户应该能够与团队成员分享他们的工作。
幸运的是,我们有一个对用户友好的服务 DataStudio。之前在使用 Airflow 时我们把其分成了两项服务,DataStudio 和 Internal Scheduler。现在用户可以在 Datastudio 中做很多事情,例如使用 Presto/Spark 进行 Adhoc 查询,上传 shell 脚本和 Jar 进行测试,以及部署到调度程序。
我们想要教会用户在这个平台上使用 SeaTunnel。经过基础测试,我们编写了用户指南,支持用户在 DataStudio 中 运行 SeaTunnel,同时正在开发 SeaTunnel 的内部版本,当前最新版本为 V2.0.5。
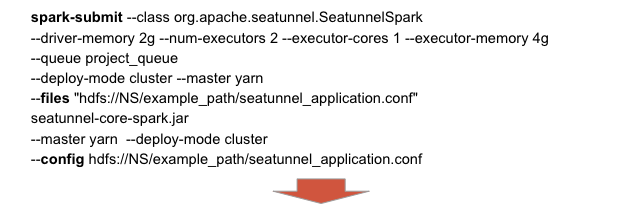
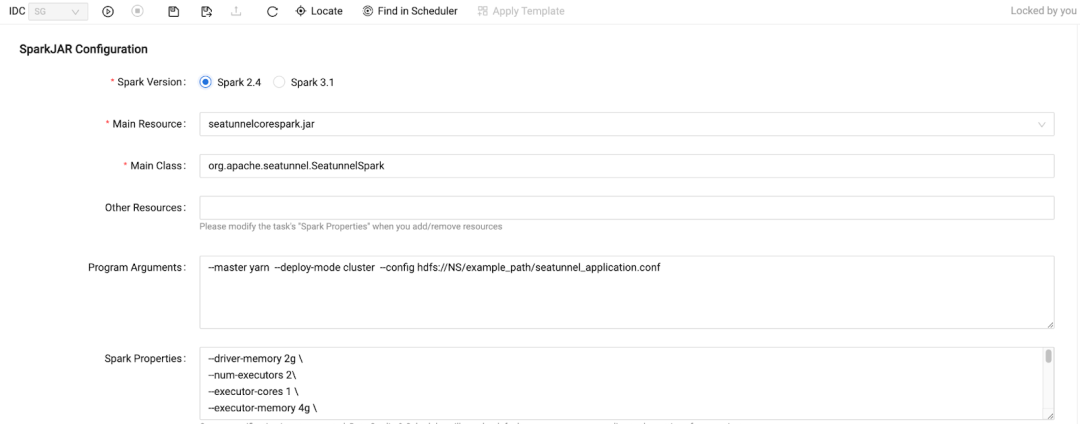
我们可以通过 SSH 使用 Spark Driver 部署 Spark 作业,但这个方法有几个缺点:
许多终端用户不熟悉 Linux 命令行,运行和调试可能是一场噩梦;
每个成员只能访问自己的目录,团队成员合作是不可行的;
在 Spark Driver 中很难对 yarn queue 等设置进行权限控制。
如果用户在 DataStudio 中执行这些操作,就不会有问题。
Yarn 队列由底层逻辑设置,由用户的项目决定。其他一些设置是默认设置,用户不必填写。作业设置看起来非常简洁。
让我们看看用户如何设置管道:
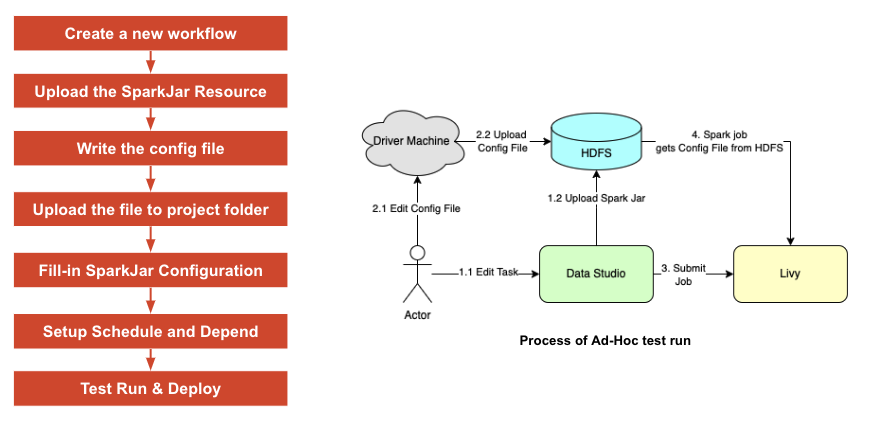
用户需要在 DataStudio 中创建一个新的工作流并上传 SeaTunnel Spark jar。用户可以从 HDFS 或 google drive 上下载 jar 文件,并确保他们可以访问我们其中一台 HDFS 驱动器,把应用程序配置文件上传到他们项目下的路径。之后,填写 Studio 的 Spark 配置。最后,可以做个运行测试,如果没有错误,可以通过查询输出表来检查数据,或者直接在 HDFS 或其他 sink 中检查。如果一切正常,则可以设置调度器时间并将其部署到调度器。
我们遇到了几个问题,并提出了相应的解决方案,如:
问题 1
DataStudio 仅支持上传小于 200MB 的 jar。
降低下载和上传负担。
解决方案
通过排除不必要的连接器和依赖项,尽可能多地构建更小的 jar。
问题 2
内部组件版本与 SeaTunnel 官方支持版本不同,如 Elastic-Search 和 HBase
解决方案
更新相关的 POM 依赖并重新编译。
问题 3
我们的 HDFS 路径在数据管理下,用户只能在特定路径上创建外部 Hive 表。
Hive sink 只会在默认路径下创建托管 Hive 表。
解决方案
从 HDFS Spark sink 扩展一个名为 HdfsHiveTable Extended 的新 Spark sink connector。
问题 4
一些用户无法访问驱动程序机器,无法将配置文件上传到 HDFS
解决方案:
提供了一种管理应用程序配置的新方法,使用户能够直接在 DatatStudio 中上传 JSON 字符串,而不是配置文件。
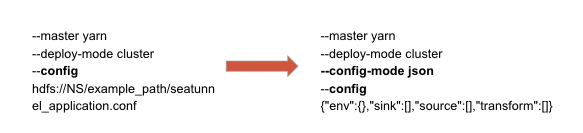
-
重用 config 变量:如果 config mode 是 json,那么可以用一个小型离线工具将 config 解析为 json 字符串,而不是 config 文件的路径。对于旧版本的 SeaTunnel,这似乎是唯一可行的方法。在最新版本中,SeaTunnel 提供了一种解析此配置变量的新方法。
问题 5
用户需要更多类型的 connector
解决方案
部署 File、JDBC(AWS Redshift)、SSL enabled MySQL、Google sheet等。
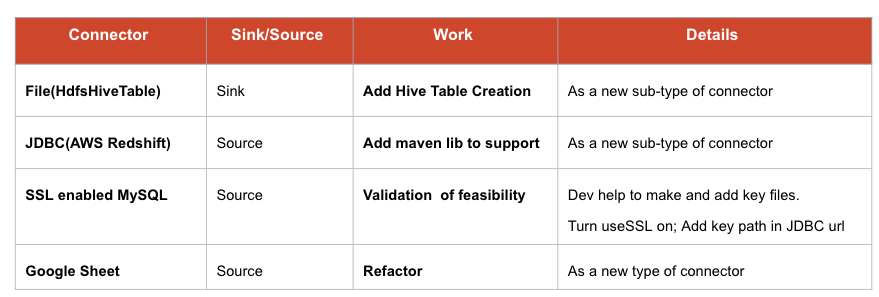
我们也在尝试在 SeaTunnel 中实现一些运行管道,例如 Google Sheet 数据获取。之前我们开发了一个 Spark 数据源从 Google sheet 中获取数据,但是需要重构和解耦 source 和 sink,SeaTunnel 帮助我们轻松做到这一点。在这个例子中,我们把原来的 Spark 数据源和 HdfsHiveTable 作为我们的 connector。
3.2
改造批量获取
这个临时解决方案为用户解决了燃眉之急,事情开始走向正轨。于是我们开始思考 SeaTunnel 是否可以帮助我们的开发人员更有效地开发和管理不同类型的管道。
我们内部有个 BTI 批处理获取系统。BTI 解决了业务分析问题,对在线 OLTP 系统的影响最小,尤其是在及时性要求不高的情况下。
通常,实时和离线数据处理需求占比约为 20-80%,所以 BTI 主要是用来同步大部分对实时性要求不高,但需要分析的数据,比如把数据从在线 OLTP 数据库(如 MySQL)同步到 OLAP 数据库(如 Hive)。这个系统遇到了不稳定的问题,需要大量时间来维护。众所周知,它是 Lambda 大数据架构的一部分。
Shopee 的批量获取系统的演进历史很长,过程我就不多介绍了。
总之,当我们决定引入 SeaTunnel 时,已经放弃了 Airflow。所以目前批量数据获取是由 Datahub 和内部 Scheduler 触发的,但是执行是由一个独立的服务来管理的。这个 DB 批量获取服务很复杂,用户不可见,且难以维护。
以下是我们决定重构批量获取系统的两个主要原因:
第一,因为 SeaTunnel 的优势潜力已经很明显了,我们计划将它作为我们长期的统一传输组件。
其次,遗留系统的复杂性困扰着我们,随着每天创建越来越多的作业,系统就更加脆弱,调试是一场噩梦。
重构包含三个子任务:
使用 SeaTunnel 重新部署原来的传输组件。
重构相关服务以降低复杂性。
迁移历史作业
原来的批次获取是用来做什么的呢?
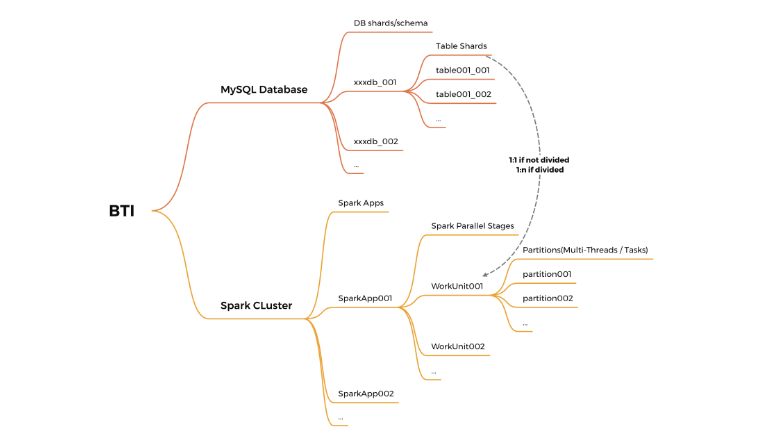
简单来说,因为它支持分表、分库,甚至分片主机,所以我们需要多个 Spark 作业来运行它。每个 Spark 作业负责一个物理数据库,作业内部的每个阶段负责一个物理表,我们称之为 WorkUnit。
在 Spark 应用中,单个 Spark 应用相对于一个子数据库,也称为 schema,一个子数据库通常包含多个表分片。如果没有数据倾斜(没有划分),则一个子表由一个 WorkUnit 同步,否则由多个 WorkUnit 同步(取决于部分)。
Spark 并行阶段(WorkUnit)可以引发多线程/任务来执行同步。

如本示例图所示,一个完整的批量获取作业包括 4 个步骤:获取、分区、转换和表创建。每一步都是一个 Spark 应用程序。所以一个 BTI 作业就是一个 DAG 或者我们可以称之为 WorkFlow,它由几个自定义的步骤组成。其中,获取和建表贯穿整个过程。
我们需要在从数据库表中取数据之前检查心跳,以保持数据质量。可以通过从源数据库的心跳表中做一个简单的查询来检查。
获取是主要的步骤,不断将数据下沉到 HDFS。
分区是可选的,有时它被用于最小化 Hive 分区的数量。如果我们只是简单地通过 sharding DB 或 sharding host 来对表进行分区,可能会导致新增数千个分区,危及的 Hive megastore。
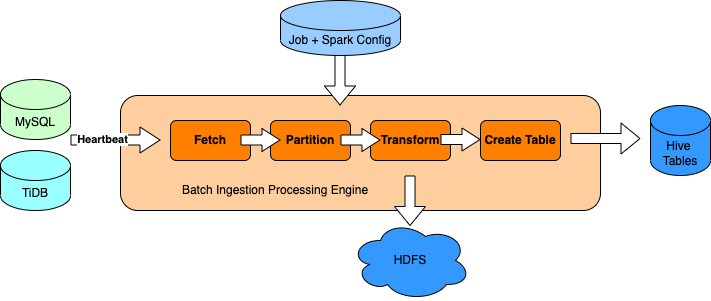
转换是在 HDFS 进行另一轮获取,并将数据写回 HDFS。
最后,创建 Hive 表和相应的标记,在调度程序中做个标记,让下游知道这个任务已完成。
我们已经在 SeaTunnel 中实现了将批量获取作为 source connector 的插件。

这是我们所做的工作。
以前的心跳检查是由 Apache Nifi 触发的脚本。我们可以将其视为上游依赖项。
在 SeaTunnel 中实现心跳很简单,只需要在心跳检查失败时确保作业失败。
至于获取、分区和建表阶段,我们将所有原始逻辑原样搬到 SeaTunnel中,只是重构了一些数据结构,让 sink step 成为 SeaTunnel Source 中的一个函数。
我们将所有内容都放入源任务中,因为我们的批量获取作业中包含很多数据框架,因此我们无法通过创建临时视图将所有数据传输到 sink connector。
我们想出了这个解决方法,虽然不优雅,但确实有效。
对于转换,我们定义了一个分区步骤,但我们还是把相关逻辑放在源连接器中。与接收器路径相关的配置也是如此。

对于配置细节,您可以看到之前它依赖于 2 个文件,作业属性定义了整个获取作业。
Fetch 定义了 fetch 步骤。重构之后,配置清晰、简洁多了。
最后,让我们看看 Datahub 如何创建重构的批量获取作业。
下表是基本任务配置的项目。
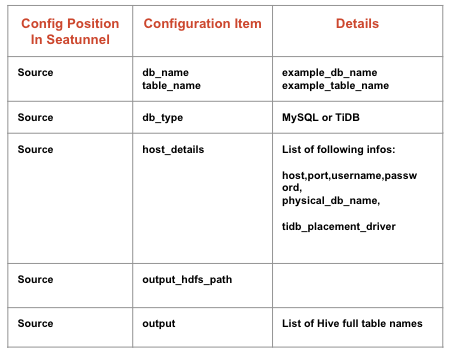
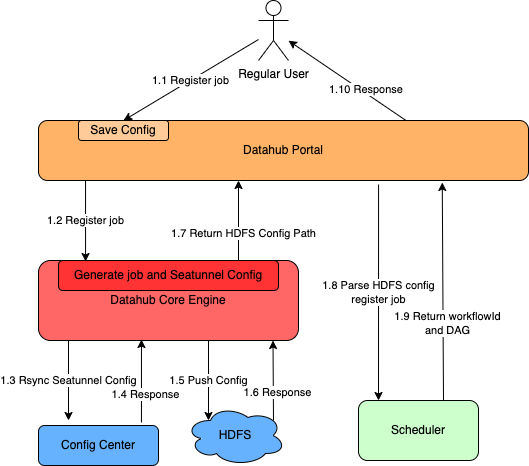
用户点击注册按钮后,这些 JSON 格式的消息传递给 Datahub 的核心引擎,核心引擎会与配置中心通信,得到 SeaTunnel 格式的配置,并在 HDFS 中更新。
作业注册后,Portal 会将批量获取 DAG 注册到调度器。
04
基于 SeaTunnel 构建 ETL 产品
4.1
ETL模块边界
最后,让我们看看如何基于 SeaTunnel 从头开始创建一个全新的功能。
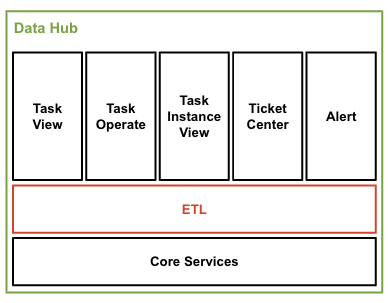
除了我们已经在 Datahub 中为标准化数据源提供的工具外,这个 ETL 模块还针对仓库中现有数据之间的非标准化数据摄取和数据转换。通常,这些管道的数据处理更加复杂。
目前,考虑到资源使用难以控制和估计,我们暂不支持管道中的多来源。出于安全考虑,我们禁止终端用户将数据导出到我们的数据仓库外。
4.2
用户任务端到端工作流

首先,我们从用户的角度来看,他们是如何创建 ETL 管道的。
由于这是一项个性化功能,所以会比普通的获取工具复杂一些。
除了选择和设置 source 和 sink 信息外,用户还必须配置和检查源表和目标表之间的模式映射规则,这是因为模式自动推断在多次转换后是不可行的,特别是对于数据类型信息。
设置完所有配置后,用户可以进行 Adhoc 执行以查看运行情况。
只有当用户确认提交任务时,后端才会生成实际的配置文件,让调度器工作。
4.3
流程图

后端系统包含 5 个主要组件。
Datahub 是用户的接口,是协调一切的中心。它向 ETL 服务发送 ETL 管道创建和预览管道创建请求,为预览创建调度程序任务和 AdHoc 调度程序任务,使用调度程序 OpenAPI 来获取任务实例信息和日志,从 Kafka 主题中读取任务实例状态和 Adhoc 实例状态。最后,作业提交到 Flink 平台。
4.4
预览

SeaTunnel 的一大亮点就是预览功能,也包含了我们系统的主要逻辑。
预览使用户能够查看过程中的结果。在预览功能中,Datahub 和 ETL 之间会有两个接口。
首先,Datahub 将当前管道配置提供给 ETL,并像普通管道一样创建预览管道。我们没有把数据下沉到用户配置的目标,而是创建了一个临时配置文件,将数据下沉到 S3。
其次,Datahub 需要手动触发任务,这样预览管道才能在调度器中创建实例并运行。
之后,Scheduler 收到临时配置文件的路径以及其他信息,并开始 Ad-hoc 执行。
最后,Datahub 可以通过 S3 API 获取 Scheduler 给出的当前管道的输出数据。
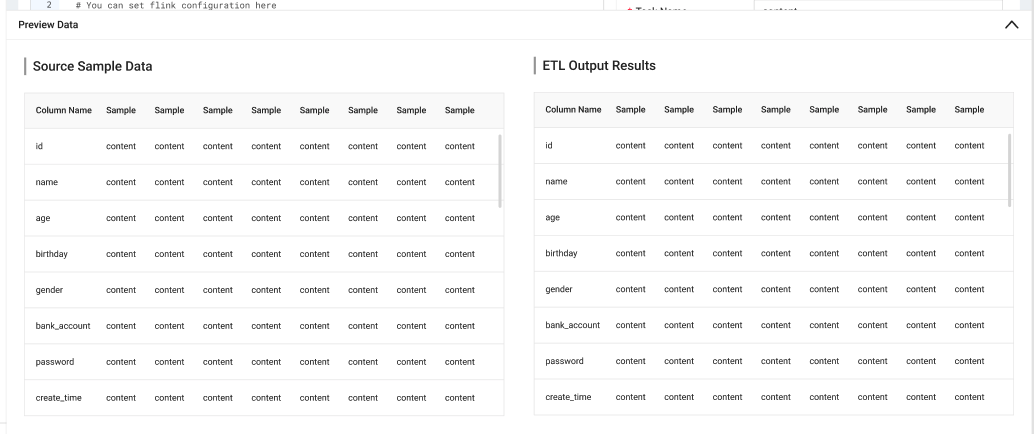
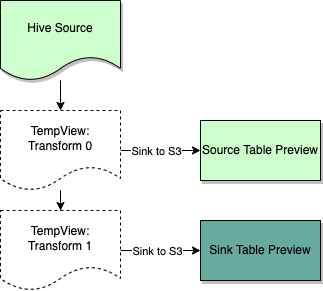
预览版 SeaTunnel 作业是一个 hive-to-hive ETL 任务,因为用户需要用它在数据仓库中以 dwd(数据仓库详细信息)或 dws(服务)级别构建表,所以这种管道以后将会被广泛使用。
Transform 和 sink 配置都有一些细微的变化。
在 Transform 中,我们对 SQL 脚本添加了一个限制来控制数据传输的大小。
至于 Sink,我们把目标改成了 S3,connector 是在建表时在 Flink SQL 的 properties 中定义的,而且源表和目标表的路径不同。
这样用户会看到 2 张预览表,方便很多,因为他们不用在很长一段时间后查询该表。
4.5
常用解决方案
现在我们可以回顾一下 ETL 特性是如何解决我们一开始提到的问题的。
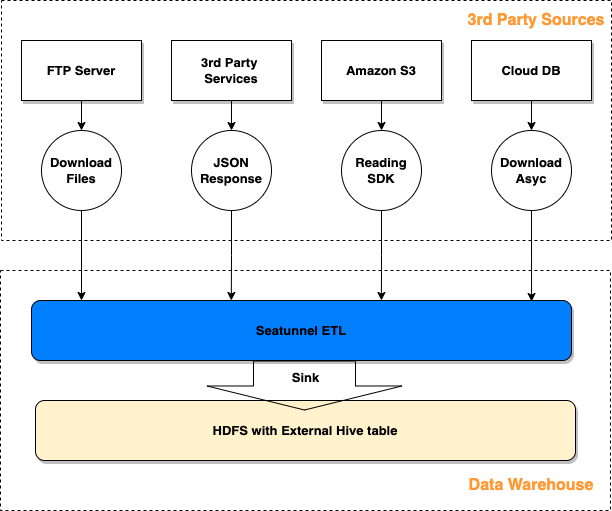
对于第 3 方获取问题,数据存储将由 Data Hub ETL 模块直接集中、支持和管理。
所有的数据处理操作(数据解析、数据清洗)都包含在 ETL 管道中。我们正在尝试支持并将更多遗留管道迁移到 ETL 平台。

对于原始数据使用的问题,现在用户可以继续创建原始表,在 Data Hub ETL 模块中构建 ODS 层管道,这比 DataStudio 中创建要容易得多,ETL 不仅支持批量获取 Hive 表,还支持连续获取 Hudi 表。

与原始数据使用问题类似,用户可以使用 ETL 通过创建 hive-to-hive ETL 管道来构建他们的数据仓库。

最后,还可以解决一些内部组件之间的特殊数据传输问题,比如 Hive 和Hbase,或者 ClickHouse 之间的数据传输。

总结一下 ETL 平台会为用户带来什么。
借助 SeaTunnel 的特性,我们可以轻松支持更多类型的数据存储,用户可以用更简单友好的方式学习和设置 ETL 管道,从而专注于数据建模和洞察分析。
与手动在数据套件中部署 Spark 应用程序的临时解决方案相比,ETL 管道将通过其他 DataSuites 产品得到更多的支持,例如数据血缘和数据质量检查等。
最后同样重要的是,这种方法对工程师友好,易于操作和维护,易于开发更多管道。
06
总结
5.1
我们所做的
从最开始开始回顾,我们原来的目的就是希望找到在三个方面都能很好满足我们需求的解决方案:
在短期内:
可以很快解决我们遇到的问题
长期来看:
从开发人员的角度来看:它们应该可以减轻并加速管理各种获取请求的负担。
从用户的角度来看,它们应该提供新的和易于使用的功能。
幸运的是,SeaTunnel 通过了所有测试,并且我们已经实现了很多传输组件,其中一些已经交付给用户,还有一些正在等待外部服务重构。
我们重构了一个系统。
此外,我们还在 Datahub 中发布了 ETL 功能,并将继续为其添加更多类型的管道。
5.2
未来计划
首先,由于我们的大多数 Spark 应用程序都是在 Spark 3.0 中运行的,而且 Spark 3.0 具有 AQE(自适应查询执行)功能,可以或多或少地自动解决数据倾斜问题,所以我们迫切需要 SeaTunnel 支持 Spark 3.0。
我们正在尝试升级一些连接器,例如一些数据获取的连接器优先升级。另外,我们还会继续实现更多的连接器,但主要会集中在 Flink Engine,因为 ETL 平台是我们的长期计划。
我们也在尝试构建一个可观察性的系统,需要添加每个组件中的指标,便于我们收集信息来做统一的警报系统和仪表板。
最后,为社区做更多贡献,互相学习,共同成长。














 1365
1365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









