







Java 8 函数式编程 阅读记录
章节要点概览
第二章【 Lambda 表达式 】
- Lambda 表达式是一个匿名方法, 将行为像数据一样进行传递。
- Lambda 表达式的常见结构:
BinaryOperator<Integer> add = (x, y) → x + y。- 函数接口指仅具有单个抽象方法的接口, 用来表示 Lambda 表达式的类型。
第三章 【 流 】
- 内部迭代将更多控制权交给了集合类。
- 和 Iterator 类似,Stream 是一种内部迭代方式。
- 将 Lambda 表达式和 Stream 上的方法结合起来,可以完成很多常见的集合操作。
第四章 【 类库 】
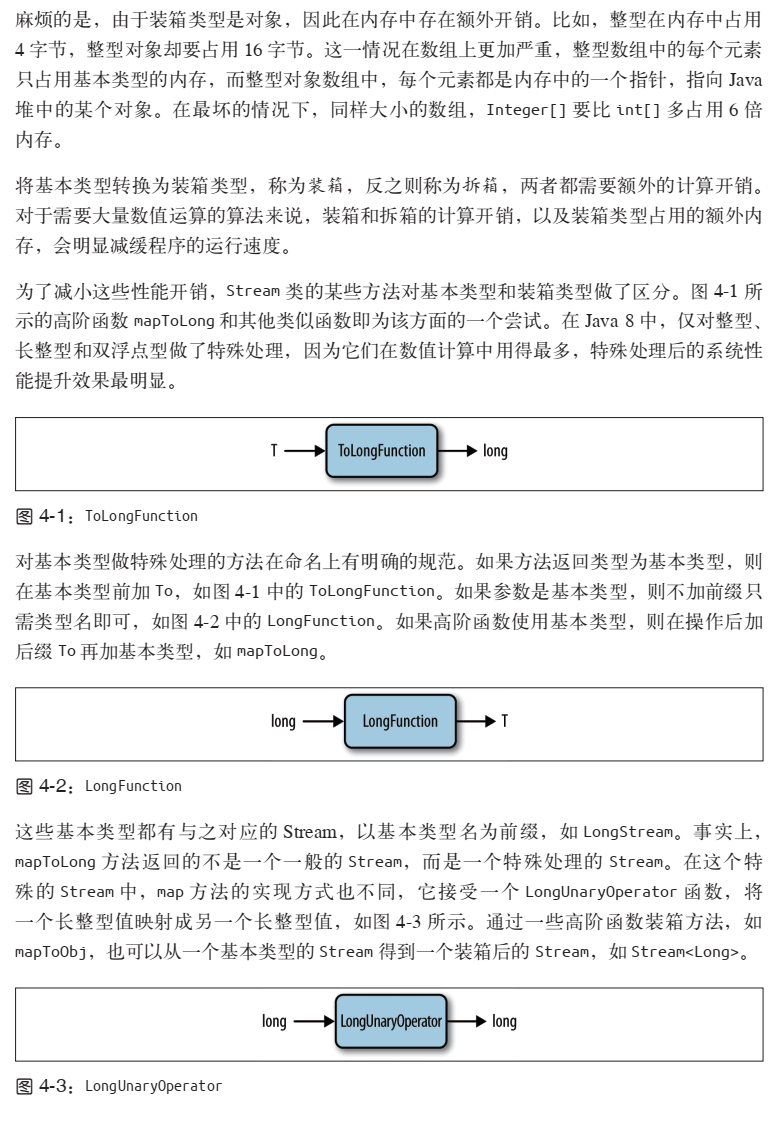
- 使用为基本类型定制的 Lambda 表达式和 Stream,如
IntStream可以显著提升系统性能。- 默认方法是指接口中定义的包含方法体的方法,方法名有 default 关键字做前缀。
- 在一个值可能为空的建模情况下,使用 Optional 对象能替代使用 null 值。
第五章 【 高级集合类和收集器 】
方法引用是一种引用方法的轻量级语法, 形如:
ClassName::methodName。收集器可用来计算流的最终值,是 reduce 方法的模拟。
Java 8 提供了收集多种容器类型的方式,同时允许用户自定义收集器。
第六章 【 数据并行化 】
数据并行化是把工作拆分,同时在多核 CPU 上执行的方式。
如果使用流编写代码,可通过调用
parallel或者parallelStream方法实现数据并行化
操作。影响性能的五要素是:数据大小、 源数据结构、值是否装箱、可用的 CPU 核数量,以
及处理每个元素所花的时间。
第七章 【 测试、 调试和重构 】
重构遗留代码时考虑如何使用 Lambda 表达式,有一些通用的模式。
如果想要对复杂一点的 Lambda 表达式编写单元测试,将其抽取成一个常规的方法。
peek方法能记录中间值,在调试时非常有用。
第八章 【 设计和架构的原则 】
Lambda 表达式能让很多现有设计模式更简单、可读性更强,尤其是命令者模式。
在 Java 8 中,创建领域专用语言有更多的灵活性。
在 Java 8 中,有应用
SOLID原则的新机会。
第九章 【 使用 Lambda 表达式编写并发程序 】
使用基于 Lambda 表达式的回调,很容易实现事件驱动架构。
CompletableFuture代表了 IOU,使用 Lambda 表达式能方便地组合、合并。
Observable继承了 CompletableFuture 的概念,用来处理数据流。

-
Java8之Predicate函数

public static boolean judgeConditionByFunction(int value, Predicate<Integer> predicate) { return predicate.test(value); } /** * - 1.判断传入的字符串的长度是否大于5 * - 2.判断传入的参数是否是偶数 * - 3.判断数字是否大于10 */ @Test public void test1() { /* - 1.判断传入的字符串的长度是否大于5 */ System.out.println(CommonTest.judgeConditionByFunction(123456, value -> String.valueOf(value).length() > 5)); /* - 2.判断传入的参数是否是奇数 */ System.out.println(CommonTest.judgeConditionByFunction(4, value -> value % 2 == 0)); /* - 3.判断数字是否大于10 */ System.out.println(CommonTest.judgeConditionByFunction(-1, value -> value > 10)); }
-
stream流的惰性求值

判断一个操作是惰性求值还是及早求值很简单: 只需看它的返回值。 如果返回值是 Stream,
那么是惰性求值; 如果返回值是另一个值或为空, 那么就是及早求值。 使用这些操作的理
想方式就是形成一个惰性求值的链, 最后用一个及早求值的操作返回想要的结果, 这正是
它的合理之处。
-
stream流的reduce方法
一个reduce操作(也称为折叠)接受一系列的输入元素,并通过重复应用操作将它们组合成一个简单的结果。
-
reduce(accumulator) -
reduce(identity,accumulator) -
reduce(identity,accumulator,combiner)
identity是reduce进行迭代操作的初始值。accumulator是用来迭代的。combiner是并发时用来合并各线程结果的。下面的代码实例代码展示了这一过程。 Lambda 表达式就是 reducer, 它执行求和操作, 有两个参数: 传入 Stream 中的当前元素和 acc。 将两个参数相加, acc 是累加器, 保存着当前的累加结果 。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5); Integer reduce2 = list.stream().reduce(1,(acc, element)->acc + element );//初始值1,初始值依次和list值相加,再赋值给初始值 //上面这一行等价于 // Integer reduce = 1; // for (Integer i : list) { // reduce = reduce + i; // } //同样可以简化为方法引用 Integer reduce2 = list.stream().reduce(1, Integer::sum); System.out.println("reduce = " + reduce); //16不过需要注意的一点是,上面实例代码的
identity值是有问题的。在单线程的时候不会看出来,但是当使用parallel并发操作时就会出现初始值多次叠加的问题。List<Integer> list = Arrays.asList(1, 2, 3, 4, 5); Integer reduce = list.stream().parallel().reduce(1, Integer::sum); System.out.println("reduce = " + reduce); //20可以看到最终结果是20,初始值1一共相加了5次。这是由于reduce内部使用了fork-join框架 把大任务转小任务,然后并发运行,但是为了保证并发安全,他把每个输入数据都复制了一份,这样自然不用🔓了,但同时导致初始值多加4遍。

上面的源代码注释里面可以看到,
identity需要符合两个条件。上面例子里,0是符合的,1是不符合的。List<Integer> list = Arrays.asList(1, 2, 3, 4, 5); Integer reduce = list.stream().parallel().reduce(1, Integer::sum, (acc, element) -> acc + element - 1); System.out.println("reduce = " + reduce); //16传入第三个参数
combiner,对结果进行并发合并,可以对最终结果进行修正。 -
-
方法引用表达式
标准语法为
Classname::methodName。 虽然这是一个方法,但不需要在后面加括号,因为这里并不调用该方法。方法引用只是提供了和 Lambda 表达式等价的一种结构,在需要时才会调用。凡是使用 Lambda 表达式的地方,就可以使用方法引用。 -
值的转换
toList,toSet,toCollection等方法,对stream的值进行收集并生成集合。stream.collect(toCollection(TreeSet::new));maxBy,minBy,averagingInt等函数,对值进行数学操作。 -
数据分块
收集器
Collectors.partitioningBy函数接受一个流, 并将其分成两部分 。它使用Predicate对象判断一个元素应该属于哪个部分,并根据布尔值返回一个 Map 到列表。因此,对于 true List 中的元素,Predicate 返回 true;对其他 List 中的元素,Predicate 返回 false。@Test public void test6_partitioningBy() { List<Student> students = Arrays.asList( new Student("zhangsan", "22", "男"), new Student("lisi", "14", "男"), new Student("wangwu", "25", "女"), new Student("wangwuhe", "18", "男"), new Student("zhaoliu", "4", "女")); Map<Boolean, List<Student>> collect = students.stream() // 先用年龄排了个序 .sorted(Comparator.comparing(student -> Integer.parseInt(student.getAge()))) // 用分块方法对list进行分块。isAudlt是在实体类里自定义的根据年龄判断的方法 .collect(Collectors.partitioningBy(Student::isAudlt)); collect.forEach((aBoolean, students1) -> { System.out.println(aBoolean ? "成年" : "未成年"); students1.forEach(System.out::println); }); } /** * 根据年龄判断,18或以上则返回true。 * @return boolean */ public boolean isAudlt() { return Integer.parseInt(age) >= 18; } /* 输出结果 未成年 Student(name=zhaoliu, age=4, sex=女) Student(name=lisi, age=14, sex=男) 成年 Student(name=wangwuhe, age=18, sex=男) Student(name=zhangsan, age=22, sex=男) Student(name=wangwu, age=25, sex=女) */ -
数据分组
数据分组可以使用
Collectors.groupingBy函数。使用方法与partitioningBy类似,不过更有优势。partitioningBy函数返回的Map的key是boolean类型,也就是这个函数的返回值只能将数据分为两组也就是ture和false两组数据。groupingBy的函数参数的返回值也是Map,但是他的key是泛型,那么这个分组就会将数据分组成多个key的形式。@Test public void test7_groupingBy(){ List<Student> students = Arrays.asList( new Student("zhangsan", "22", "男"), new Student("lisi", "14", "男"), new Student("wangwu", "25", "女"), new Student("wangwuhe", "18", "男"), new Student("wwh", "18", "未知"), new Student("zjh", "18", "未知"), new Student("zhaoliu", "4", "女")); Map<String, List<Student>> collect = students.stream() // 先用年龄排了个序 .sorted(Comparator.comparing(student -> Integer.parseInt(student.getAge()))) // 根据年龄进行分类 .collect(Collectors.groupingBy(Student::getSex)); collect.forEach((sex, students1) -> { System.out.println(sex+":"); students1.forEach(System.out::println); }); } /* 输出结果 女: Student(name=zhaoliu, age=4, sex=女) Student(name=wangwu, age=25, sex=女) 未知: Student(name=wwh, age=18, sex=未知) Student(name=zjh, age=18, sex=未知) 男: Student(name=lisi, age=14, sex=男) Student(name=wangwuhe, age=18, sex=男) Student(name=zhangsan, age=22, sex=男) */-
根据实体对象进行属性分组计数
Collectors.groupingBy(Function.identity(),Collectors.counting())@Test public void test7_groupingBy(){ List<Student> students = Arrays.asList( new Student("zhangsan", "22", "男"), new Student("lisi", "14", "男"), new Student("wangwu", "25", "女"), new Student("wangwuhe", "18", "男"), new Student("wwh", "18", "未知"), new Student("zjh", "18", "未知"),//这里加了三个相同的对象,注意输出结果 new Student("zjh", "18", "未知"), new Student("zjh", "18", "未知"), new Student("zhaoliu", "4", "女")); //根据实体对象进行属性分组计数。注意Map的key值 Map<Student, Long> collect = students.stream().collect(Collectors.groupingBy(Function.identity(),Collectors.counting())); collect.forEach((sex, students1) -> System.out.println(sex+":"+students1+"人")); /* 输出结果 Student(name=wangwuhe, age=18, sex=男):1人 Student(name=wwh, age=18, sex=未知):1人 Student(name=zhaoliu, age=4, sex=女):1人 Student(name=zjh, age=18, sex=未知):3人 Student(name=zhangsan, age=22, sex=男):1人 Student(name=lisi, age=14, sex=男):1人 Student(name=wangwu, age=25, sex=女):1人 */ }其他还有诸如根据属性分组后对某个属性进行统计相加
,Collectors.summingInt()等。
-
-
使用流收集并得到一个字符串
@Test public void test8_joining(){ List<Student> students = Arrays.asList( new Student("zhangsan", "22", "男"), new Student("lisi", "14", "男"), new Student("wangwu", "25", "女"), new Student("wangwuhe", "18", "男"), new Student("zjh", "18", "未知"), new Student("zhaoliu", "4", "女")); // 使用流收集姓名并得到一个字符串,同时可以提供分隔符( 用以分隔元素)、 前缀和后缀 String namesStr = students.stream().map(Student::getName).collect(Collectors.joining(",","姓名:","。")); /* 输出结果 姓名:zhangsan,lisi,wangwu,wangwuhe,zjh,zhaoliu。*/ System.out.println( namesStr); } -
组合收集器
根据属性分组计数,将
groupingBy和Collectors.counting()组合起来使用。其中里面的收集器可以称之为下游收集器。//根据年龄进行属性分组计数 Map<String, Long> collect = students.stream().collect(Collectors.groupingBy(Student::getSex,Collectors.counting())); collect.forEach((sex, students1) -> System.out.println(sex+":"+students1+"人")); /* 输出结果 女:2人 未知:2人 男:3人 */mapping允许在收集器的容器上执行类似 map 的操作。 但是需要指明使用什么样的集合类存储结果, 比如 toList。@Test public void test10_groupingBy() { List<Student> students = Arrays.asList( new Student("zhangsan", "22", "男"), new Student("lisi", "22", "男"), new Student("wangwu", "23", "女"), new Student("wangwuhe", "23", "男"), new Student("zjh", "24", "未知"), new Student("zhaoliu", "22", "女")); // 使用流收集不同年龄的姓名list Map<String, List<String>> collect = students.stream().collect(Collectors.groupingBy(Student::getAge, Collectors.mapping(Student::getName, Collectors.toList()))); System.out.println(collect); /* 输出结果 {22=[zhangsan, lisi, zhaoliu], 23=[wangwu, wangwuhe], 24=[zjh]}*/ } -
定制收集器
…
书上实现了类似于
StringJoiner类的操作。 JAVA8——StringJoiner类 -
Map的新方法
Map的
computeIfAbsent方法,类似于Optional的orElse的效果,当通过第一个参数key值获取不到value值时,使用第二个参数参与运算,一般会返回一个默认值。public static Map<String, Student> studentCache = Stream.of( new Student("zhangsan", "22", "男"), new Student("lisi", "22", "男"), new Student("wangwu", "23", "女"), new Student("wangwuhe", "23", "男"), new Student("zjh", "24", "未知"), new Student("zhaoliu", "22", "女")) .collect(Collectors.toMap(Student::getName, Function.identity())); @Test public void test11_compute() { System.out.println(this.getStudent("zhangsan").toString());// 缓存中可以拿到值 System.out.println(this.getStudent("王五").toString());// 不能拿到值 /* 输出结果 Student(name=zhangsan, age=22, sex=男) Student(name=王五, age=0, sex=unknown) */ } // 通过姓名从缓存内获取对象的方法,使用Map的computeIfAbsent方法,在从缓存map中拿不到值时,使用默认方法。 public Student getStudent(String name) { return studentCache.computeIfAbsent(name, Student::getStudentDefault); } // 实体类内的获取default对象方法 public static Student getStudentDefault(String name) { return new Student(name, "0", "unknown"); } -
并行和并发
并发是两个任务共享时间段,并行则是两个任务在同一时间发生,比如运行在多核 CPU上。如果一个程序要运行两个任务,并且只有一个 CPU 给它们分配了不同的时间片,那么这就是并发,而不是并行。

-
并行流
将调用
stream换成调用parallelStream就能立即获得一个并行流。影响并行流性能的因素
-
数据大小 。将问题分解之后并行化处理, 再将结果合并会带来额外的开销。 因此只有数据足够大、 每个数据处理管道花费的时间足够多时, 并行化处理才有意义。
-
源数据结构。每个管道的操作都基于一些初始数据源, 通常是集合。 将不同的数据源分割相对容易,这里的开销影响了在管道中并行处理数据时到底能带来多少性能上的提升。

-
装箱。处理基本类型比处理装箱类型要快。
-
核的数量 。核越多,并行性能越好,单核就完全没必要并行化。
-
单元处理开销。比如数据大小, 这是一场并行执行花费时间和分解合并操作开销之间的战争。 花在流中每个元素身上的时间越长, 并行操作带来的性能提升越明显。
-
流中间操作类型。stream流操作类型可以分为三级,而中间操作又可以分成两类。可以分成两种不同的操作:无状态操作和有状态操作。
无状态操作整个过程中不必维护状态, 有状态操作则有维护状态所需的开销和限制。如果能避开有状态, 选用无状态操作, 就能获得更好的并行性能。 无状态操作包括map、filter和flatMap, 有状态操作包括sorted、skip、distinct和limit。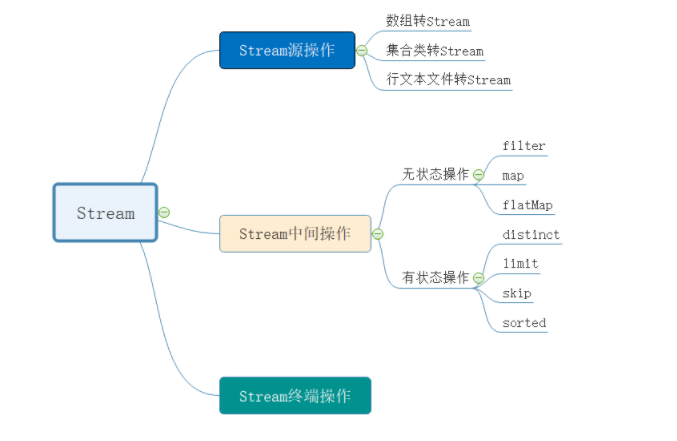
在底层, 并行流还是沿用了
fork/join框架。 fork 递归式地分解问题, 然后每段并行执行,最终由 join 合并结果, 返回最后的值。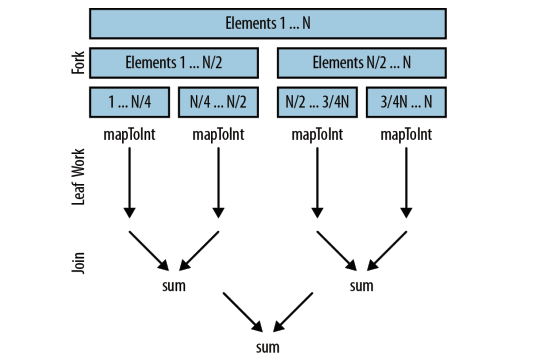
-
-
封装局部状态

-
peek方法
@Test public void test3() { List<Student> list = Arrays.asList( new Student("zhangsan", "22", "男"), new Student("lisi", "23", "女"), new Student("wangwu", "24", "男")); // 使用 forEach 方法打印出流中的值, 这同时会触发求值过程。 但是这样的操作有个缺点: 我们无法再继续操作流了, 流只能使用一次。 如果我们还想继续, 必须重新创建流。 list.stream().filter(student -> student.getSex().equals("男")).forEach(System.out::println); // peek 方法可以操作每个值, 同时能保持流 List<Student> manList = list.stream() .filter(student -> student.getSex().equals("男")).peek(System.out::println).collect(Collectors.toList()); }peek方法同样可以对每个对象的内容进行操作。比如常用的操作:过滤后,对每个对象的值进行修改。 -
设计模式
- 命令者模式
- 策略模式
- 观察者模式
- 模板方法模式
第八章之后的内容看不太动,吸收率可能也就20%左右,就不总结了。















 2121
2121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









