






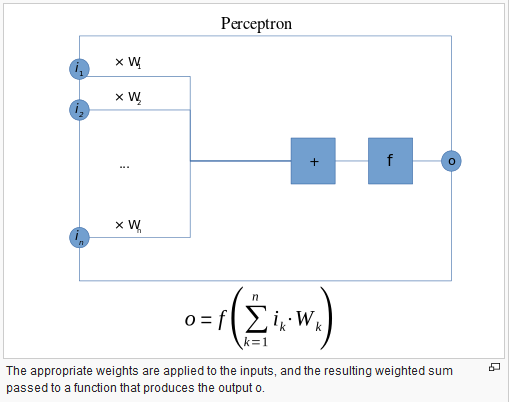
Perceptron感知机
简单说明
在机器学习中,Perceptron是一种针对监督学习的二元分类的算法,函数可以判定输入输入的是numbers类型 向量,还是属于一些特殊的类型或者都不属于。Perceptron是一种线性分类器、一个分类算法,它的预测是基于一个linear predictor function(权重的集合与特征向量的结合)。
定义

输出f(x)是一个二元值;
w是一个真实值的权重向量,其中

m是输入的数量;
b是偏差(偏差判定边界远离原点不依赖于任何的输入值);

如果学习集合不是线性可分的,感知学习算法将不能终止。如果向量不是线性可分的将不会达到一个point(所有向量是合理分类的)。在神经网络的背景下,一个Perceptron是一个 artificial neuron(是一个构思成生物神经元模型的数学函数)使用Heaviside step function(https://en.wikipedia.org/wiki/Heaviside_step_function)作为激活函数。perceptron 也是single-layer perceptron的术语,区别于 multilayer perceptron(对于更复杂的神经网络是一个误称),single-layer perceptron是最简单的 feedforward neural network。
算法学习
举一个例子对于single-layer perceptron。在 multilayer perceptrons中有一个隐藏层存在,更多的随机算法比如backpropagation被使用。 如果函数是非线性且可微的情况下,delta rule方法可能被使用。当multilayer perceptrons结合一个人工神经网络时候,每一个输出神经元的操作独立于其他的,因此每个输出可以被单独的考虑。
首先定义几个变量
- y=f(z) 对于输入向量z的输出符号表示
- xj 是n维的输入向量
- xji(j,i是x的下标表示) 是对于第j个输入的训练向量的第i个特征的值
- xj0=1
- 由于xj0=1则w0=0
不像其他的分类算法如逻辑回归,感知机算法是不需要学习率的
步骤
- 初始化权重和阈值,权重可能被初始化为0或者更小的随机值,下面的例子初始化为0。
- 对于训练集D中的每一个j,遵循下面的步骤,输入xj, 渴望得到值dj:
a. 计算实际的输出
b. 更新权重
- 对于离线学习,步骤2可能一直被重复操作直到迭代错误
可能是更少的对于一个用户的阈值r,或者一个预先迭代值已经被完成的,经历过2a,2b立即去应用到新的一个训练集合中的样本,重复操作继续,直到所有的样本都经历完。
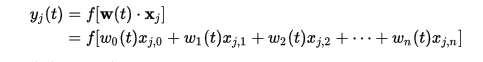
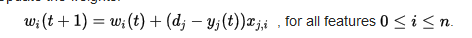
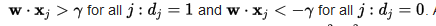
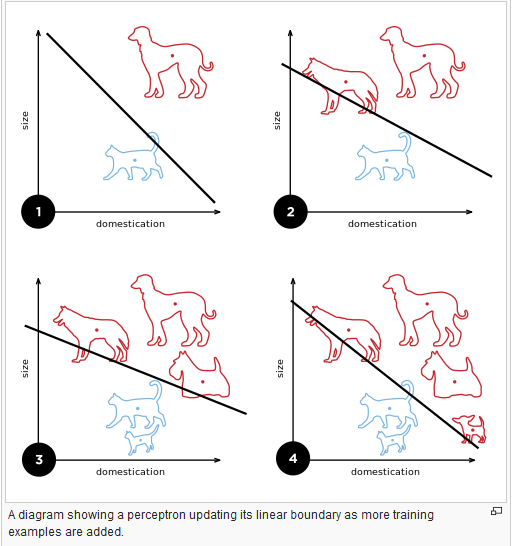















 534
534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









