







什么是JPA
SpringData是Spring提供的一个数据操作框架,而SpringData JPA则是该框架下基于JPA标准进行数据操作的模块。
SpringData JPA简化了持久层代码的操作,只需编写接口即可实现。
JPA,全称Java Persistence API,是Spring Data的子项目之一。它是JDK 5.0的注解或XML描述对象与关系表映射关系的工具,可以将运行时的实体对象持久化到数据库中。
JPA和Mybatis都是持久层框架,具有相同的功能。然而,由于Mybatis的广泛使用,现在了解和使用JPA的人较少。
JPQL 是从 Hibernate 的 HQL 演变而来的,其语法与 HQL 非常相似。HQL,即 Hibernate Query Language(Hibernate查询语言),而 SQL 是 Structure Query Language(结构化查询语言)。
它们的主要区别在于:SQL 直接操作数据库中的表和字段,而 HQL 则操作实体对象和属性。
需要注意的是,我们编写的 JPQL 最终仍会被转换成 SQL 语句进行执行。
接口继承关系

Repository<T, ID>接口 最顶层接口 作用自定义JPQL语句
/**
* 使用@Query注解,自定义JPQL语句
* JPQL语句中,使用的不是表名,而是实体类名,不是列名,而是属性名,
* 例如SQL语句:select * from user JPQL语句是:select User from User
* 如果是条件查询,之前语句中的占位符?可以使用(:xxx)进行表示
* 此时xxx会根据方法中同名的形参自动绑定值
*/
public interface UsersRepositoryByQuery extends Repository<User, Integer> {
//如果是查询所有列,可以省略select ....,从from开始写
@Query("from User where name=:name")
List<User> selectByName(String name); //select * from user where name=?
@Query("select u from User u where name=:name and age=:age")
List<User> selectByNameAndAge(String name, Integer age); //select * from user where name=? and age=?
@Query("from User where name=:name and age=:age")
List<User> selectByNameLike(String name);//select * from user where name like ?
//除了使用JPQL语句,也是可以使用sql原生语句,在注解中设置参数nativeQuery = true,不推荐!
@Query(value = "select * from user where name=:name",nativeQuery = true)
List<User> selectByNameSQl(String name);//select * from user where name=?
}
CrudRepository接口 继承了Repository接口,内置类增删改查的方法
PagingAndSortingRepository接口继承了CrudRepository接口
增加了分页和排序方法
@Autowired
private UserRepositoryPage userRepositoryPage;
/**
* 分页
*/
@Test
void testPage(){
//第一个参数是页码数,0表示第一页;第二参数是分页单位;
Pageable Pageable = PageRequest.of(0, 2);
Page<User> page = userRepositoryPage.findAll(Pageable);
System.out.println("总数据量"+page.getTotalElements());
System.out.println("总页数"+page.getTotalPages());
List<User> content = page.getContent();
for (User user : content) {
System.out.println(user);
}
}
/**
* 排序
*/
@Test
void testSort(){
//根据id排序
Sort sort = Sort.by(Sort.Order.desc("id"));
Iterable<User> all = userRepositoryPage.findAll(sort);
for (User user : all) {
System.out.println(user);
}
}
JpaRepository<T, ID> 接口
继承了 PagingAndSortingRepository<T, ID>
和查询接口 QueryByExampleExecutor
特点是可以帮助我们将其他接口的方法的返回值做适配处理。可以使得我们在开发时更方便的使用这些方法
JpaSpecificationExecutor 接口 主要提供了多条件查询的支持,并且可以在查询中添加分页与排序
JpaSpecificationExecutor接口与以上接口没有关系,完全独立。
不能单独使用,需要配合着JPA 中的其他接口一起使用。
//接口
public interface UserRepositoryExJPA extends JpaRepository<User,Integer>,JpaSpecificationExecutor<User> {
}
//使用
@Autowired
private UserRepositoryExJPA userRepositoryExJPA;
/**
* 自定义规则,可以多条件查询
*/
@Test
void testExJPA2() {
Specification<User> specification = new Specification<User>() {
@Override
public Predicate toPredicate(Root<User> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) {
//模糊查询
Predicate predicate = criteriaBuilder.like(root.get("name"), "张%");
//模糊查询+性别筛选+年龄筛选
Predicate predicate2 = criteriaBuilder.and(criteriaBuilder.like(root.get("name"), "张%"),
criteriaBuilder.equal(root.get("sex"), "男"), criteriaBuilder.gt(root.get("age"), 24));
return predicate2;
}
};
//进行排序年龄进行倒序排列
Sort sort = Sort.by(Sort.Order.desc("age"));
//分页+追加排序
Pageable pageable = PageRequest.of(0, 2, sort);
Page<User> page = userRepositoryExJPA.findAll(specification, pageable);
System.out.println("根据条件查询到" + page.getTotalElements() + "条数据");
System.out.println("根据条件查询到" + page.getTotalPages() + "页数据");
System.out.println("当页数据");
for (User user : page) {
System.out.println(user);
}
}
JpaRepositoryImplementation<T, ID> 接口
继承了 JpaRepository<T, ID>, JpaSpecificationExecutor 接口
实现类为SimpleJpaRepository<T, ID> 接口 功能最强大
关键命名查询
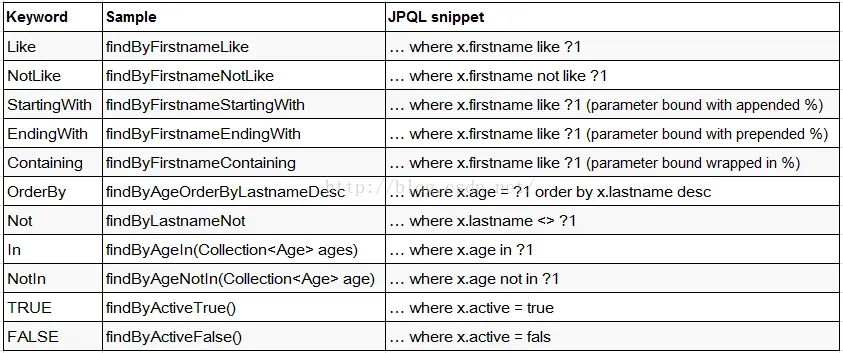
根据 Spring Data 的规范,查询方法应以 find、read 或 get 开头(例如 find、findBy、read、readBy、get、getBy)。当涉及到查询条件时,应使用条件关键字连接属性,并确保条件属性的首字母大写。在解析方法名时,框架会先去除多余的前缀,然后对剩余部分进行解析。
你可以直接在接口中定义查询方法,只要符合规范,就无需编写实现或 SQL。目前支持的关键字写法如下:

关注公众号,程序员三时 持续输出优质内容 希望给你带来一点启发和帮助















 967
967











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









