







工作也有两年了,在研究很多项目时发现很多问题追根溯源都会到计算机底层的知识,也是越来越发现编程语言只是一层外壳,这个外壳需要去和操作系统协商使用后者管理的的计算机资源,包括存储资源和计算资源。如果计算机底层知识不牢靠,遇到一些问题还真是不好分析,也很容易成为职业上升的瓶颈。现在回想起大学时学习这么课时是比较抽象的,那时没有太多编程经验,知识很难落地,造成了只知其然不知其所以然的情况,所以现在重新梳理一下计算机操作系统的一些底层知识,在这里记录一下。
这篇文章我们来看看计算机的存储结构,之后主要研究一下操作系统的虚拟内存机制。
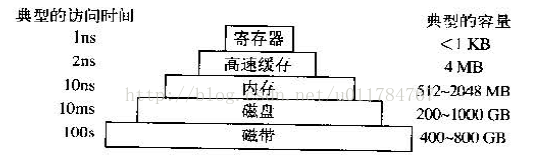
上图为典型的计算机存储层次结构,从上往下依次是寄存器、高速缓存、内存、磁盘、磁带。如果从缓存原理的角度讲,上层存储是下层存储的缓存。
- 寄存器:它是由和cpu同种材料制作而成,cpu访问寄存器是最快的,而且没有时钟时延,但是寄存器的容量在存储系统中是最小的。
- 高速缓存(Cache):高速缓冲存储器是存在于主存与CPU之间的一级存储器, 由静态存储芯片(SRAM)组成,容量比较小但速度比主存高得多, 接近于CPU的速度。这里要提一点就是"CPU是直接与寄存器和高速缓存打交道,他不与内存直接沟通"。
- 内存:Random Access Memory(RAM)随机访问存储器,它的访问速度是慢于寄存器和高速缓存,同时CPU要想访问内存中的数据,需要将访问请求通过总线发送给指定的硬件。同时注意 寄存器、高速缓存、内存中的数据断电即丢失。
- 磁盘,磁带:这是一种机械装置,访问这些存储器上的数据耗费的时间是最长的,通常都需要阻塞响应的程序,当时他们断电不丢失数据,并且具有较大的存储空间。
讲完了计算机存储结构,接下来我们讲讲计算机对内存的使用这块。
计算机在发展的初期,程序是直接使用内存的物理地址的,但是这样带来的很多的问题:
(1)直接使用物理地址,无法或者很难正确安全的进行多道程序设计。
(2)直接使用物理地址,程序很可能会占用系统所使用的内存,导致操作系统逐渐死掉。
后来人们逐渐设计出了一套抽象的逻辑地址,每个进程都有一套可寻址的逻辑地址空间的范围,这些逻辑地址对应的物理地址空间是其他进程不可见的。“不管你的内存有多大,程序最终都会填满它”为了解决内存空间有限而又想运行多道程序的问题,之后诞生了“虚拟内存”的策略。
虚拟内存的大体思想是:每个进程都有自己独立的地址空间,这些地址空间被划分为很多块称为页面,每个页面都是连续的地址范围,这些页面被映射到物理内存,但是并不是所有的页面都在内存中程序才能运行,当程序引用到当前在物理内存中的页面时,由硬件立即执行必要的映射,当程序引用了不在物理内存中的地址空间时,操作系统将缺失的页面装到内存,并重新执行失败的命令。
虚拟内存是单机系统最重要的几个底层原理之一,它由底层硬件和操作系统两者软硬件结合来实现,是硬件异常,硬件地址翻译,主存,磁盘文件和内核的完美交互。
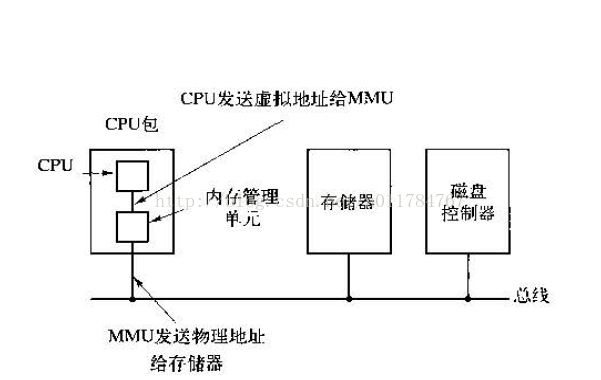
CPU当访问一个物理内存中的值时,通常要经过以下几个步骤:
- 将虚拟地址通过MMU(Memory Management Unit)内存管理单元转换为物理内存
- 检查当前高速缓存行内是否有该值,如果有称为缓存命中,直接返回该值
- 如果高速缓存中没有,则将该物理地址通过总线访问主存,同时CPU陷入内核,这个陷阱成为“缺页中断”
为了实现虚拟内存的策略,将虚拟内存的连续地址空间划分为多个小的连续地址空间称之为"页面",同时将物理内存也按照虚拟页面的大小划分为连续的地址空间称之为“页框”。
假设在32位系统中我们有一个64KB的程序,物理内存为32KB,采用虚拟内存机制分页和页框,如下图所示。页面大小的设置是操作系统的一个重要参数,太大容易造成内存浪费,太小会产生大量页面,从而产生很大的页表,降低了从虚拟内存到物理内存的映射速度。

页表
为了高效的进行虚拟地址到物理地址之间的映射,虚拟地址为分为多个部分,如上面提到的16为虚拟地址,高4可以指定为16个虚拟页号,低12为作为偏移量。在MMU维护了一个数据结构,这个数据结构对虚拟页号和物理页号进行了映射,这个数据结构成为页表,可以把它看做成一个函数,输入为虚拟页号,输出为物理页号。
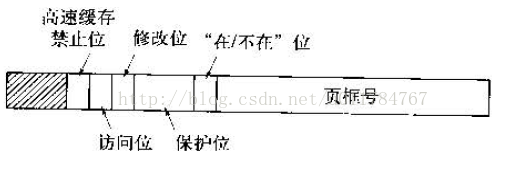
上图为一个典型的页表的数据结构项,我们依次来看看这些项的作用:
高速缓存位:禁止CPU高速缓存 缓存该页面的值,比如映射到寄存器中的值,这个值是不能缓存需要每次都要访问其他存储而获得。
- 保护位:用户指定该页面的访问类型0 读/写,1为只读。为了更详细的指明和后期置换页又引入了访问位和修改位。
- 访问位:每次访问该页面时置位。
- 修改位:每次修改该页面时置位,如果一个页面被修改过则需要写入磁盘,如果没被修改过可以直接替换。
- 页框号:对应的物理内存的页框号,这也是页表最重要的一个域。
- 在/不在:1表示该页框已经使用,0表示该页不在内存,需要产生缺页中断来加载到内存。















 895
895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









