






C++实现MD5摘要算法加盐salt值
1.信息摘要函数
1.1Hash函数
哈希函数就是能将任意长度的数据映射为固定长度的数据的函数。哈希函数返回的值被叫做哈希值、哈希码、散列,或者直接叫做哈希。
1.2消息摘要
将长度不固定的消息(message)作为输入参数,运行特定的Hash函数,生成固定长度的输出,这个输出就是Hash,也称为这个消息的消息摘要(Message Digest)
1.3信息摘要算法是hash算法的一种,具有以下特点:
①无论输入的消息有多长,计算出来的消息摘要的长度总是固定的,计算出的结果越长,一般认为该摘要算法越安全,MD5 128位 SHA-1 160位
②输入的消息不同,产生的消息摘要必不同,输入的消息相同,产生的消息摘要一定是相同的
③单向不可逆。
④消息摘要看起来是“随机的。这些比特看上去是胡乱的杂凑在一起的。可以用大量的输入来检验其输出是否相同,一般,不同的输入会有不同的输出,而且输出的摘要消息可以通过随机性检验。但是,一个摘要并不是真正随机的,因为用相同的算法对相同的消息求两次摘要,其结果必然相同;而若是真正随机的,则无论如何都是无法重现的。因此消息摘要是“伪随机的”。
⑤好的摘要算法,没有人能从中找到“碰撞”,虽然“碰撞”是肯定存在的。即对于给定的一个摘要,不可能找到一条信息使其摘要正好是给定的。或者说,无法找到两条消息,是它们的摘要相同。
1.4消息摘要的应用——数字签名
1.4.1数据的完整性
数据的完整性是指信宿接收到的消息一定是信源发送的信息,而中间绝无任何更改。
1.4.2信息的不可否认性
信息的不可否认性是指信源不能否认曾经发送过的信息
一般地,把对一个信息的摘要称为该消息的指纹或数字签名。数字签名是保证信息的完整性和不可否认性的方法。其实,通过数字签名还能实现对信源的身份识别(认证),即确定“信源”是否是信宿意定的通信伙伴。
数字签名应该具有唯一性,即不同的消息的签名是不一样的;同时还应具有不可伪造性,即不可能找到另一个消息,使其签名与已有的消息的签名一样;还应具有不可逆性,即无法根据签名还原被签名的消息的任何信息。这些特征恰恰都是消息摘要算法的特征,所以消息摘要算法适合作为数字签名算法。
数字签名方案是一种以电子形式存储消息签名的方法。一个完整的数字签名方案应该由两部分组成:签名算法和验证算法。一般地说,任何一个公钥密码体制都可以单独地作为一种数字签名方案使用。如RSA作为数字签名方案使用时,可以定义如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qE8TaKD0-1607785105922)(images\20161029105448942.png)]](https://img-blog.csdnimg.cn/20201212230704805.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTE4NzAwMjI=,size_16,color_FFFFFF,t_70)
1.5RSA作为数字签名
RSA是非对称加密
概念:
公钥:给需要加密方
私钥:解密者自己留
密钥生成过程:
1:随机选择两个质数p、q,计算出 n=p x q
2:计算出不大于N与N互质的数的数量 f(n)=(p-1) x (q-1).
3:取e不大于f(n)且与f(n)互质的数.
4:计算出e x d mod f(n) = 1 时 d的值.
5:则(e,n)为公钥(d,n)为私钥
加密过程:
原文^e mod n = 密文
解密过程:
密文^d mod n = 原文
这种签名实际上就是用信源地私钥加密消息,加密后地消息即成了签体;而用对应地公钥进行验证,若公钥解密后的消息与原来的消息相同,则消息是完整的,否则消息不完整。它正好和公钥密码用于消息保密是相反的过程。因为只有信源才拥有自己地私钥,别人无法重新加密源消息,所以即使有人截获且更改了源消息,也无法重新生成签体,因为只有用信源的私钥才能形成正确地签体。同样信宿只要验证用信源的公钥解密的消息是否与明文消息相同,就可以知道消息是否被更改过,而且可以认证消息是否是确实来自意定的信源,还可以使信源不能否认曾将发送的消息。所以这样可以完成数字签名的功能
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rMzuPDDA-1607785105944)(images\662236-20180823173238402-2085730366.png)]](https://img-blog.csdnimg.cn/20201212230717988.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTE4NzAwMjI=,size_16,color_FFFFFF,t_70)
但这种方案过于单纯,它仅可以保证消息的完整性,而无法确保消息的保密性。而且这种方案要对所有的消息进行加密操作,这在消息的长度比较大时,效率使非常低的,主要原因在于公钥体制的加解密过程的低效性。所以这种方案一般不可取。
几乎所有的数字签名方案都要和快速高效的**摘要算法(Hash函数)**一起使用,当公钥算法与摘要算法结合起来使用时,便构成了一种有效地数字签名方案。
这个过程是:首先用摘要算法对消息进行摘要,然后在把摘要值用信源的私钥加密;接收方先把接收的明文用同样的摘要算法摘要,形成“准签体”,然后再把准签体与用信源的公钥解密出的“签体”进行比较,如果相同就认为消息是完整的,否则消息不完整。
这种方法使公钥加密只对消息摘要进行操作,因为一种摘要算法的摘要消息长度是固定的,而且都比较“短”(相对于消息而言),正好符合公钥加密的要求。这样效率得到了提高,而其安全性也并未因为使用摘要算法而减弱。
1.6 MD5信息摘要算法(不是加密算法)
MD5信息摘要算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,可以产生出一个128位(16字节)的散列值(hash value),用于确保信息传输完整一致。MD5由美国密码学家罗纳德·李维斯特(Ronald Linn Rivest)设计,于1992年公开,用以取代MD4算法。这套算法的程序在 RFC 1321 标准中被加以规范。1996年后该算法被证实存在弱点,可以被加以破解,对于需要高度安全性的数据,专家一般建议改用其他算法,如SHA-2。2004年,证实MD5算法无法防止碰撞(collision),因此不适用于安全性认证,如SSL公开密钥认证或是数字签名等用途。
1.6.1原理
· MD5算法的原理可简要的叙述为:MD5码以512位分组来处理输入的信息,且每一分组又被划分为16个32位子分组,经过了一系列的处理后,算法的输出由四个32位分组组成,将这四个32位分组级联后将生成一个128位散列值。
总体流程如下图所示,每次的运算都由前一轮的128位结果值和当前的512bit值进行运算 。
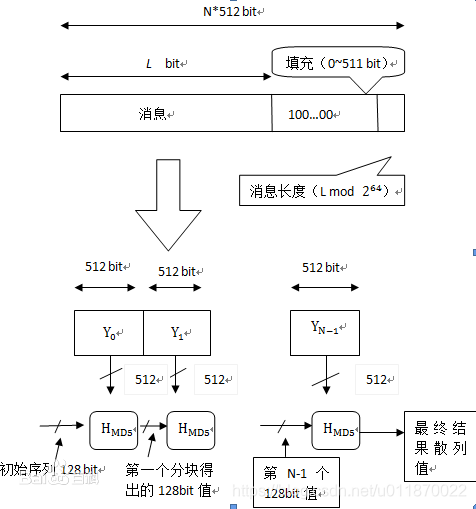
1.6.2算法步骤
1.6.2.1按位补充数据
在MD5算法中,首先需要对信息进行填充,这个数据按位(bit)补充,要求最终的位数对512求模的结果为448。也就是说数据补位后,其位数长度只差64位(bit)就是512的整数倍。即便是这个数据的位数对512求模的结果正好是448也必须进行补位。补位的实现过程:首先在数据后补一个1 bit; 接着在后面补上一堆0 bit, 直到整个数据的位数对512求模的结果正好为448。总之,至少补1位,而最多可能补512位 [8] 。
1.6.2.2扩展长度
在完成补位工作后,又将一个表示数据原始长度的64 bit数(这是对原始数据没有补位前长度的描述,用二进制来表示)补在最后。当完成补位及补充数据的描述后,得到的结果数据长度正好是512的整数倍。也就是说长度正好是16个(32bit) 字的整数倍。
1.6.2.3初始化MD缓存器
MD5运算要用到一个128位的MD5缓存器,用来保存中间变量和最终结果。该缓存器又可看成是4个32位的寄存器A、B、C、D,初始化为 :
A : 01 23 45 67
B: 89 ab cd ef
C: fe dc ba 98
D: 76 54 32 10
1.6.2.4处理数据段
首先定义4个非线性函数F、G、H、I,对输入的报文运算以512位数据段为单位进行处理。对每个数据段都要进行4轮的逻辑处理,在4轮中分别使用4个不同的函数F、G、H、I。每一轮以ABCD和当前的512位的块为输入,处理后送入ABCD(128位) 。
1.62.5输出
信息摘要最终处理成以A, B, C, D 的形式输出。也就是开始于A的低位在前的顺序字节,结束于D的高位在前的顺序字节 。
1.6.3安全性分析
MD5相对MD4所作的改进:
1.6.3.1增加了第四轮。
1.6.3.2每一步均有唯一的加法常数。
1.6.3.3减弱第二轮中函数的对称性。
1.6.3.4第一步加上了上一步的结果,这将引起更快的雪崩效应(就是对明文或者密钥改变 1bit 都会引起密文的巨大不同)。
1.6.3.5改变了第二轮和第三轮中访问消息子分组的次序,使其更不相似。
1.6.3.6近似优化了每一轮中的循环左移位移量以实现更快的雪崩效应,各轮的位移量互不相同。
1.7MD5算法的缺点
MD5 算法自诞生之日起,就有很多人试图证明和发现它的不安全之处,即存在碰撞(在对两个不同的内容使用 MD5算法运算的时候,有可能得到一对相同的结果值)。2009年,中国科学院的谢涛和冯登国仅用了 的碰撞算法复杂度,破解了MD5的碰撞抵抗,该攻击在普通计算机上运行只需要数秒钟。
1.8MD5算法加盐
根据MD5的存在的缺点,为了加强MD5加密算法的安全性(本身是不可逆的),从而加入了新的算法部分即加盐值,加盐值是随机生成的一组字符串,可以包括随机的大小写字母、数字、字符,位数可以根据要求而不一样,使用不同的加盐值产生的最终密文是不一样的。由于使用加盐值以后的密码相当的安全,即便是你获得了其中的salt和最终密文,破解也是一个耗费相当多时间的过程,可以说是破解单纯MD5的好几倍。并且同一个明文在经过加盐(这个盐是随机的,不同的)后进行MD5算法产生的密文也是不同的。这就使得MD5算法的抗碰撞性得到大幅度增强。
2.MD5+盐的实现步骤
1).首先获取需要进行md5普摘要算法的明文text。
2).随机生成加盐值(可以由字母,数字,字符组成,位数可以自己决定,这里使用16位的字符串)salt字符串.
3)将生成的salt字符串追加到明文text中,得到组合的字符串 mergeText = text +salt。
4)使用md5普通摘要算法获取mergeText 的hash值得到一个32位的字符串decodeText。
5).将盐salt字符串的每个字符逐个插入到字符串decodeText是 i *3+1(i = 0,1,2,…16)的位置上,得到一个新的48位的字符串 decode。
6)最终的decode字符串就是所要的密文,位长为48个字符。
3.代码实现
这里主要借助已经使用C++实现的MD5算法类来实现MD5+盐的原理。
3.1产生盐值字符串的算法
/**
产生盐值字符串salt
*/
string EncryptUtil::createSalt()
{
//随机生成两个随机数
int num1 = rand() % 99999999;
int num2 = rand() % 99999999;
string salt = "";
//将这两个随机数转换为字符串后追加到salt中
salt.append(to_string(num1));
salt.append(to_string(num2));
//salt不够十六位就在后面加0
int len = salt.size();
if (len < 16) {
for (int i = 0; i < 16 - len; i++) {
salt.append("0");
}
}
return salt;
}
3.2获取md5普通摘要函数+盐值salt操作后的最终密文
/**
* 加盐MD5
* @param text : 需要进行加盐后摘要的text明文
* @return string:返回进行摘要算法后的字符串
*/
string EncryptUtil::encryptBySalt(const string& text) {
//产生盐值字符串salt
string salt = createSalt();
//将产生的salt追加到需要进行摘要的明文text中,得到由明文text和salt组成的字符串
string merge_str = text + salt;
//使用md5算法进行摘要计算得到相应的32位的密文
string encodeText = md5Hex(merge_str);
char cs [48];
//将32位的密文和产生的16位的salt进行重组形成新的48位的字符串。
//这里表示,在新的字符数组cs中,salt中的字符添加到cs字符数组中位置是i*3+1的位置,其它位置由摘要密文encodeText中的字符填充
for (int i = 0; i < 48; i += 3) {
cs[i] = encodeText[i / 3 * 2];
char c = salt[i / 3];
cs[i + 1] = c;
cs[i + 2] = encodeText[i / 3 * 2 + 1];
}
//将组合成的cs字符数组转化为字符串得到48位的加盐后形成的md5摘要密文
string code = "";
for (int i = 0; i < 48; i++)
{
code.append(1,cs[i]);
}
return code;
}
3.4校验加盐后是否和原文一致
/**
* 校验加盐后是否和原文一致
* @param text : 进行摘要算法的明文
* @param encryptText : 进行加盐摘要算法后的密文
* @return 如果加盐后和原明文text一致则返回true,否则返回false
*/
bool EncryptUtil::verify( string text, string encryptText) {
char md5Text[32];
char salt[16];
//首先将加盐后md5算法摘要得到的encryptText密文进行拆分成一个32位的普通md5摘要算法密文md5Text和一个16位的字符串salt。
//这里就是进行salt和md5摘要密文形成48位新的字符串encryptText时的逆向操作。encryptText中salt[i] = encryptText[ 3* i + 1], i = 0,1,2,...15
for (int i = 0; i < 48; i += 3) {
md5Text[i / 3 * 2] = encryptText[i];
md5Text[i / 3 * 2 + 1] = encryptText[i + 2];
salt[i / 3] = encryptText[i + 1];
}
//将拆分的16个随机字符串追salt加到明文text中
for (int i = 0; i < 16; i++)
{
text.append(1,salt[i]);
}
//使用md5摘要算法进行生成密文得到enCs2
string enCs2 = md5Hex(text);
//比较两个字符串相等,如果相等则返回true,只要有一个字符不相等就返回false
for (int i = 0; i < enCs2.size(); i++)
{
if (enCs2[i] != md5Text[i])
{
return false;
}
}
return true;
}
4.具体代码
其中MD5算法的实现引用了博客https://blog.csdn.net/flydream0/article/details/7049322中实现的md5算法代码
4.1EncryptUtil.h文件
#pragma once
#include<iostream>
#include<string>
#include"Md5.h"
#include<time.h>
using namespace std;
class EncryptUtil
{
public:
EncryptUtil();
/**
*@param text:需要进行普通md5摘要算法计算的明文
*@return string:返回普通md5摘要算计算后的字符串
*/
string md5Decode(const string& text);
/**
产生盐值字符串salt
*/
string createSalt();
/**
* 加盐MD5
* @param text : 需要进行加盐后摘要的text明文
* @return string:返回进行摘要算法后的字符串
*/
string encryptBySalt(const string& text);
/**
* 获取十六进制字符串形式的MD5摘要
* @param text: 需要进行摘要算法的明文
* @return string: 返回进行普通md5摘要后的字符串
*/
string md5Hex(const string& src);
/**
* 校验加盐后是否和原文一致
* @param text : 进行摘要算法的明文
* @param encryptText : 进行加盐摘要算法后的密文
* @return 如果加盐后和原明文text一致则返回true,否则返回false
*/
bool verify( string text, string md5Text);
/**
逐个比较两个密文相同位置上字符是否相同来计算两个进行md5加密后的相似度。
@param str1: md5摘要算法后的字符串
@param str2:md5摘要算法后的字符串
@return double: 返回相似度
*/
double similarityDegree(const string& str1, const string& str2);
~EncryptUtil();
private:
MD5* md5 = nullptr;
};
4.2EncryptUtil.cpp
#include "EncryptUtil.h"
EncryptUtil::EncryptUtil()
{
//初始化MD5这个类
this->md5 = new MD5();
//设置随机数种子,在产生盐时可以产生随机数。
srand(time(NULL));
}
/**
*@param text:需要进行普通md5摘要算法计算的明文
*@return string:返回普通md5摘要算计算后的字符串
*/
string EncryptUtil::md5Decode(const string & text)
{
//调用md5Hex(text)函数即可
return this->md5Hex(text);
}
/**
产生盐值字符串salt
*/
string EncryptUtil::createSalt()
{
//随机生成两个随机数
int num1 = rand() % 99999999;
int num2 = rand() % 99999999;
string salt = "";
//将这两个随机数转换为字符串后追加到salt中
salt.append(to_string(num1));
salt.append(to_string(num2));
//salt不够十六位就在后面加0
int len = salt.size();
if (len < 16) {
for (int i = 0; i < 16 - len; i++) {
salt.append("0");
}
}
//cout << "产生的盐值字符串为:" <<salt<< endl;
return salt;
}
/**
* 加盐MD5
* @param text : 需要进行加盐后摘要的text明文
* @return string:返回进行摘要算法后的字符串
*/
string EncryptUtil::encryptBySalt(const string& text) {
//产生盐值字符串salt
string salt = createSalt();
//将产生的salt追加到需要进行摘要的明文text中,得到由明文text和salt组成的字符串
string merge_str = text + salt;
//使用md5算法进行摘要计算得到相应的32位的密文
string encodeText = md5Hex(merge_str);
char cs [48];
//将32位的密文和产生的16位的salt进行重组形成新的48位的字符串。
//这里表示,在新的字符数组cs中,salt中的字符添加到cs字符数组中位置是i*3+1的位置,其它位置由摘要密文encodeText中的字符填充
for (int i = 0; i < 48; i += 3) {
cs[i] = encodeText[i / 3 * 2];
char c = salt[i / 3];
cs[i + 1] = c;
cs[i + 2] = encodeText[i / 3 * 2 + 1];
}
//将组合成的cs字符数组转化为字符串得到48位的加盐后形成的md5摘要密文
string code = "";
for (int i = 0; i < 48; i++)
{
code.append(1,cs[i]);
}
return code;
}
/**
* 获取十六进制字符串形式的MD5摘要
* @param text: 需要进行摘要算法的明文
* @return string: 返回进行普通md5摘要后的字符串
*/
string EncryptUtil::md5Hex(const string& text) {
//首先更新md5中需要进行摘要的字符串
this->md5->update(text);
//使用md5的方法生成对应的摘要后的字符串
return this->md5->toString();
}
/**
* 校验加盐后是否和原文一致
* @param text : 进行摘要算法的明文
* @param encryptText : 进行加盐摘要算法后的密文
* @return 如果加盐后和原明文text一致则返回true,否则返回false
*/
bool EncryptUtil::verify( string text, string encryptText) {
char md5Text[32];
char salt[16];
//首先将加盐后md5算法摘要得到的encryptText密文进行拆分成一个32位的普通md5摘要算法密文md5Text和一个16位的字符串salt。
//这里就是进行salt和md5摘要密文形成48位新的字符串encryptText时的逆向操作。encryptText中salt[i] = encryptText[ 3* i + 1], i = 0,1,2,...16
for (int i = 0; i < 48; i += 3) {
md5Text[i / 3 * 2] = encryptText[i];
md5Text[i / 3 * 2 + 1] = encryptText[i + 2];
salt[i / 3] = encryptText[i + 1];
}
//将拆分的16个随机字符串追salt加到明文text中
for (int i = 0; i < 16; i++)
{
text.append(1,salt[i]);
}
//使用md5摘要算法进行生成密文得到enCs2
string enCs2 = md5Hex(text);
//比较两个字符串相等,如果相等则返回true,只要有一个字符不相等就返回false
for (int i = 0; i < enCs2.size(); i++)
{
if (enCs2[i] != md5Text[i])
{
return false;
}
}
return true;
}
/**
逐个比较两个密文相同位置上字符是否相同来计算两个明文进行md5加密后的相似度。
@param str1: md5摘要算法后的字符串密文
@param str2:md5摘要算法后的字符串密文
@return double: 返回相似度
*/
double EncryptUtil::similarityDegree(const string& str1, const string& str2)
{
if (str1.size() <= 0 && (str1.size() != str2.size()))
{
return 0;
}
int count = 0;
//统计对应位置上字符相同的个数
for (int i = 0; i < str1.size(); i++)
{
if (str1[i] == str2[i])
{
count++;
}
}
//计算相似度
double result = count * 1.0 / str1.size();
return result;
}
EncryptUtil::~EncryptUtil()
{
}
4.3 MD5.h
#pragma once
#ifndef MD5_H
#define MD5_H
#include <string>
#include <fstream>
using namespace std;
/* Type define */
typedef unsigned char byte;
typedef unsigned int uint32;
/* MD5 declaration. */
class MD5 {
public:
MD5();
MD5(const void *input, size_t length);
MD5(const string &str);
MD5(ifstream &in);
void update(const void *input, size_t length);
void update(const string &str);
void update(ifstream &in);
const byte* digest();
string toString();
private:
void reset();
void update(const byte *input, size_t length);
void final();
void transform(const byte block[64]);
void encode(const uint32 *input, byte *output, size_t length);
void decode(const byte *input, uint32 *output, size_t length);
string bytesToHexString(const byte *input, size_t length);
/* class uncopyable */
MD5(const MD5&);
private:
uint32 _state[4]; /* state (ABCD) */
uint32 _count[2]; /* number of bits, modulo 2^64 (low-order word first) */
byte _buffer[64]; /* input buffer */
byte _digest[16]; /* message digest */
bool _finished; /* calculate finished ? */
static const byte PADDING[64]; /* padding for calculate */
static const char HEX[16];
static const size_t BUFFER_SIZE = 1024;
};
#endif/*MD5_H*/
4.4
#include "md5.h"
/* Constants for MD5Transform routine. */
#define S11 7
#define S12 12
#define S13 17
#define S14 22
#define S21 5
#define S22 9
#define S23 14
#define S24 20
#define S31 4
#define S32 11
#define S33 16
#define S34 23
#define S41 6
#define S42 10
#define S43 15
#define S44 21
/* F, G, H and I are basic MD5 functions.
*/
#define F(x, y, z) (((x) & (y)) | ((~x) & (z)))
#define G(x, y, z) (((x) & (z)) | ((y) & (~z)))
#define H(x, y, z) ((x) ^ (y) ^ (z))
#define I(x, y, z) ((y) ^ ((x) | (~z)))
/* ROTATE_LEFT rotates x left n bits.
*/
#define ROTATE_LEFT(x, n) (((x) << (n)) | ((x) >> (32-(n))))
/* FF, GG, HH, and II transformations for rounds 1, 2, 3, and 4.
Rotation is separate from addition to prevent recomputation.
*/
#define FF(a, b, c, d, x, s, ac) { \
(a) += F ((b), (c), (d)) + (x) + ac; \
(a) = ROTATE_LEFT ((a), (s)); \
(a) += (b); \
}
#define GG(a, b, c, d, x, s, ac) { \
(a) += G ((b), (c), (d)) + (x) + ac; \
(a) = ROTATE_LEFT ((a), (s)); \
(a) += (b); \
}
#define HH(a, b, c, d, x, s, ac) { \
(a) += H ((b), (c), (d)) + (x) + ac; \
(a) = ROTATE_LEFT ((a), (s)); \
(a) += (b); \
}
#define II(a, b, c, d, x, s, ac) { \
(a) += I ((b), (c), (d)) + (x) + ac; \
(a) = ROTATE_LEFT ((a), (s)); \
(a) += (b); \
}
const byte MD5::PADDING[64] = { 0x80 };
const char MD5::HEX[16] = {
'0', '1', '2', '3',
'4', '5', '6', '7',
'8', '9', 'a', 'b',
'c', 'd', 'e', 'f'
};
/* Default construct. */
MD5::MD5() {
reset();
}
/* Construct a MD5 object with a input buffer. */
MD5::MD5(const void *input, size_t length) {
reset();
update(input, length);
}
/* Construct a MD5 object with a string. */
MD5::MD5(const string &str) {
reset();
update(str);
}
/* Construct a MD5 object with a file. */
MD5::MD5(ifstream &in) {
reset();
update(in);
}
/* Return the message-digest */
const byte* MD5::digest() {
if (!_finished) {
_finished = true;
final();
}
return _digest;
}
/* Reset the calculate state */
void MD5::reset() {
_finished = false;
/* reset number of bits. */
_count[0] = _count[1] = 0;
/* Load magic initialization constants. */
_state[0] = 0x67452301;
_state[1] = 0xefcdab89;
_state[2] = 0x98badcfe;
_state[3] = 0x10325476;
}
/* Updating the context with a input buffer. */
void MD5::update(const void *input, size_t length) {
update((const byte*)input, length);
}
/* Updating the context with a string. */
void MD5::update(const string &str) {
update((const byte*)str.c_str(), str.length());
}
/* Updating the context with a file. */
void MD5::update(ifstream &in) {
if (!in)
return;
std::streamsize length;
char buffer[BUFFER_SIZE];
while (!in.eof()) {
in.read(buffer, BUFFER_SIZE);
length = in.gcount();
if (length > 0)
update(buffer, length);
}
in.close();
}
/* MD5 block update operation. Continues an MD5 message-digest
operation, processing another message block, and updating the
context.
*/
void MD5::update(const byte *input, size_t length) {
uint32 i, index, partLen;
//_finished = false;
this->reset();
/* Compute number of bytes mod 64 */
index = (uint32)((_count[0] >> 3) & 0x3f);
/* update number of bits */
if ((_count[0] += ((uint32)length << 3)) < ((uint32)length << 3))
_count[1]++;
_count[1] += ((uint32)length >> 29);
partLen = 64 - index;
/* transform as many times as possible. */
if (length >= partLen) {
memcpy(&_buffer[index], input, partLen);
transform(_buffer);
for (i = partLen; i + 63 < length; i += 64)
transform(&input[i]);
index = 0;
}
else {
i = 0;
}
/* Buffer remaining input */
memcpy(&_buffer[index], &input[i], length - i);
}
/* MD5 finalization. Ends an MD5 message-_digest operation, writing the
the message _digest and zeroizing the context.
*/
void MD5::final() {
byte bits[8];
uint32 oldState[4];
uint32 oldCount[2];
uint32 index, padLen;
/* Save current state and count. */
memcpy(oldState, _state, 16);
memcpy(oldCount, _count, 8);
/* Save number of bits */
encode(_count, bits, 8);
/* Pad out to 56 mod 64. */
index = (uint32)((_count[0] >> 3) & 0x3f);
padLen = (index < 56) ? (56 - index) : (120 - index);
update(PADDING, padLen);
/* Append length (before padding) */
update(bits, 8);
/* Store state in digest */
encode(_state, _digest, 16);
/* Restore current state and count. */
memcpy(_state, oldState, 16);
memcpy(_count, oldCount, 8);
}
/* MD5 basic transformation. Transforms _state based on block. */
void MD5::transform(const byte block[64]) {
uint32 a = _state[0], b = _state[1], c = _state[2], d = _state[3], x[16];
decode(block, x, 64);
/* Round 1 */
FF(a, b, c, d, x[0], S11, 0xd76aa478); /* 1 */
FF(d, a, b, c, x[1], S12, 0xe8c7b756); /* 2 */
FF(c, d, a, b, x[2], S13, 0x242070db); /* 3 */
FF(b, c, d, a, x[3], S14, 0xc1bdceee); /* 4 */
FF(a, b, c, d, x[4], S11, 0xf57c0faf); /* 5 */
FF(d, a, b, c, x[5], S12, 0x4787c62a); /* 6 */
FF(c, d, a, b, x[6], S13, 0xa8304613); /* 7 */
FF(b, c, d, a, x[7], S14, 0xfd469501); /* 8 */
FF(a, b, c, d, x[8], S11, 0x698098d8); /* 9 */
FF(d, a, b, c, x[9], S12, 0x8b44f7af); /* 10 */
FF(c, d, a, b, x[10], S13, 0xffff5bb1); /* 11 */
FF(b, c, d, a, x[11], S14, 0x895cd7be); /* 12 */
FF(a, b, c, d, x[12], S11, 0x6b901122); /* 13 */
FF(d, a, b, c, x[13], S12, 0xfd987193); /* 14 */
FF(c, d, a, b, x[14], S13, 0xa679438e); /* 15 */
FF(b, c, d, a, x[15], S14, 0x49b40821); /* 16 */
/* Round 2 */
GG(a, b, c, d, x[1], S21, 0xf61e2562); /* 17 */
GG(d, a, b, c, x[6], S22, 0xc040b340); /* 18 */
GG(c, d, a, b, x[11], S23, 0x265e5a51); /* 19 */
GG(b, c, d, a, x[0], S24, 0xe9b6c7aa); /* 20 */
GG(a, b, c, d, x[5], S21, 0xd62f105d); /* 21 */
GG(d, a, b, c, x[10], S22, 0x2441453); /* 22 */
GG(c, d, a, b, x[15], S23, 0xd8a1e681); /* 23 */
GG(b, c, d, a, x[4], S24, 0xe7d3fbc8); /* 24 */
GG(a, b, c, d, x[9], S21, 0x21e1cde6); /* 25 */
GG(d, a, b, c, x[14], S22, 0xc33707d6); /* 26 */
GG(c, d, a, b, x[3], S23, 0xf4d50d87); /* 27 */
GG(b, c, d, a, x[8], S24, 0x455a14ed); /* 28 */
GG(a, b, c, d, x[13], S21, 0xa9e3e905); /* 29 */
GG(d, a, b, c, x[2], S22, 0xfcefa3f8); /* 30 */
GG(c, d, a, b, x[7], S23, 0x676f02d9); /* 31 */
GG(b, c, d, a, x[12], S24, 0x8d2a4c8a); /* 32 */
/* Round 3 */
HH(a, b, c, d, x[5], S31, 0xfffa3942); /* 33 */
HH(d, a, b, c, x[8], S32, 0x8771f681); /* 34 */
HH(c, d, a, b, x[11], S33, 0x6d9d6122); /* 35 */
HH(b, c, d, a, x[14], S34, 0xfde5380c); /* 36 */
HH(a, b, c, d, x[1], S31, 0xa4beea44); /* 37 */
HH(d, a, b, c, x[4], S32, 0x4bdecfa9); /* 38 */
HH(c, d, a, b, x[7], S33, 0xf6bb4b60); /* 39 */
HH(b, c, d, a, x[10], S34, 0xbebfbc70); /* 40 */
HH(a, b, c, d, x[13], S31, 0x289b7ec6); /* 41 */
HH(d, a, b, c, x[0], S32, 0xeaa127fa); /* 42 */
HH(c, d, a, b, x[3], S33, 0xd4ef3085); /* 43 */
HH(b, c, d, a, x[6], S34, 0x4881d05); /* 44 */
HH(a, b, c, d, x[9], S31, 0xd9d4d039); /* 45 */
HH(d, a, b, c, x[12], S32, 0xe6db99e5); /* 46 */
HH(c, d, a, b, x[15], S33, 0x1fa27cf8); /* 47 */
HH(b, c, d, a, x[2], S34, 0xc4ac5665); /* 48 */
/* Round 4 */
II(a, b, c, d, x[0], S41, 0xf4292244); /* 49 */
II(d, a, b, c, x[7], S42, 0x432aff97); /* 50 */
II(c, d, a, b, x[14], S43, 0xab9423a7); /* 51 */
II(b, c, d, a, x[5], S44, 0xfc93a039); /* 52 */
II(a, b, c, d, x[12], S41, 0x655b59c3); /* 53 */
II(d, a, b, c, x[3], S42, 0x8f0ccc92); /* 54 */
II(c, d, a, b, x[10], S43, 0xffeff47d); /* 55 */
II(b, c, d, a, x[1], S44, 0x85845dd1); /* 56 */
II(a, b, c, d, x[8], S41, 0x6fa87e4f); /* 57 */
II(d, a, b, c, x[15], S42, 0xfe2ce6e0); /* 58 */
II(c, d, a, b, x[6], S43, 0xa3014314); /* 59 */
II(b, c, d, a, x[13], S44, 0x4e0811a1); /* 60 */
II(a, b, c, d, x[4], S41, 0xf7537e82); /* 61 */
II(d, a, b, c, x[11], S42, 0xbd3af235); /* 62 */
II(c, d, a, b, x[2], S43, 0x2ad7d2bb); /* 63 */
II(b, c, d, a, x[9], S44, 0xeb86d391); /* 64 */
_state[0] += a;
_state[1] += b;
_state[2] += c;
_state[3] += d;
}
/* Encodes input (ulong) into output (byte). Assumes length is
a multiple of 4.
*/
void MD5::encode(const uint32 *input, byte *output, size_t length) {
for (size_t i = 0, j = 0; j < length; i++, j += 4) {
output[j] = (byte)(input[i] & 0xff);
output[j + 1] = (byte)((input[i] >> 8) & 0xff);
output[j + 2] = (byte)((input[i] >> 16) & 0xff);
output[j + 3] = (byte)((input[i] >> 24) & 0xff);
}
}
/* Decodes input (byte) into output (ulong). Assumes length is
a multiple of 4.
*/
void MD5::decode(const byte *input, uint32 *output, size_t length) {
for (size_t i = 0, j = 0; j < length; i++, j += 4) {
output[i] = ((uint32)input[j]) | (((uint32)input[j + 1]) << 8) |
(((uint32)input[j + 2]) << 16) | (((uint32)input[j + 3]) << 24);
}
}
/* Convert byte array to hex string. */
string MD5::bytesToHexString(const byte *input, size_t length) {
string str;
str.reserve(length << 1);
for (size_t i = 0; i < length; i++) {
int t = input[i];
int a = t / 16;
int b = t % 16;
str.append(1, HEX[a]);
str.append(1, HEX[b]);
}
return str;
}
/* Convert digest to string value */
string MD5::toString() {
return bytesToHexString(digest(), 16);
}
5.测试
#include<iostream>
#include"Md5.h"
#include<string>
#include"EncryptUtil.h"
using namespace std;
void test() {
string text = "abcd";
EncryptUtil util;
string encodeText = util.encryptBySalt(text);
string encodeText1 = util.encryptBySalt(text);
cout << "md5加盐后加密的md5值:" + encodeText << endl;
cout << "md5加盐后加密的md5值:" + encodeText1 << endl;
if (encodeText.compare(encodeText1) == 0)
{
cout << "两次生成的加盐密文相等!" << endl;
}
else {
cout << "两次生成的加盐密文不相等!" << endl;
}
bool fla = util.verify(text, encodeText);
if (fla == true)
{
cout << "原来的明文和加盐后的明文一致得到验证!" << endl;
}
else {
cout << "原来的明文和加盐后的明文不一致!" << endl;
}
cout<<"相似度为:"<<util.similarityDegree(encodeText,encodeText1)<<endl;
}
int main() {
test();
system("pause");
return 0;
}
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











