







全文检索
目前,数据从类型上可以分为三类:
- 结构化数据
- 非结构化数据
- 半结构化数据
针对非结构化数据。最简单的全文检索算法就是顺序扫描法,很明显当文档量上升到一定数量时,代价极大。另一种即全文检索法,先对文档建立索引,然后根据索引进行查询。
倒排索引(inverted-index)
倒排表的结构很简单,本质上就是以词查文,简单的理解为一个HashMap机构, 其key为词term也就是文档中的词汇,而value则是一个list结构记录了哪些文档包含了这个词。当query一个关键词“love”时候,就可以简单的获取所有包含该词汇的文档,进行相关性排序,获取结构。
| 词term | 文档列表 |
|---|---|
| love | 1,2,3,4,45,5, |
| anger | 2,5,11,7 |
当然,一个查询可能包含的关键词不只是一个,比如说“i love China”,这时候简单的将query分成三个"i", “love”, “China”,此时我们就需要额外的一些操作,简单的我们称这种叫做联合查询
- 利用跳表(Skip list)的数据结构快速做“与”运算。
- 利用上面提到的bitset按位“与”。
1.跳表(skip list)
每一个index的查询结果都是有序的,以下假设是三个index的查询结果,可以看做是三个链表。将链表按照长度从小到大排列。我们对与长度最小的链表开始遍历元素,对于一个候选元素,若其值等于下一个链表的当前值,则遍历下一个链表;若小于下一个链表的当前元素,则当前链表遍历下一个节点;直到把最短链表遍历完成。
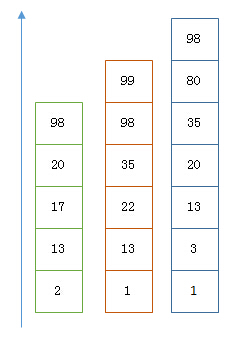
2.bitset实现
对于每一个index的查询结果,将其转化成一个bitmap数组,然后对所有index的位图数组进行与操作,最后结果便是查询结果。
索引过程
- 输入原文档。
- 将原文档传给分词器tokenizer(分词、去除标点、去停留词)
- 将词元token传给语言处理组建linguistic Processor(缩减为词根,转换为词根以及大小写转换)。
- 将词term传给索引组件indexer,其首先根据输入的term建立一个词典,然后对字典进行排序,最后合并相同的词组成倒排表posting list。
在lucene的倒排表中还包含了两个概念:
document frequency:文档频次,多少个文档包含此词。
frequency:词频率,这个文档包含某个词多少个。
检索过程
检索过程相对与索引过程,同样需要对query进行分词等处理,最后最重要的是对文档根据相关性进行排序。
a) 用户输入查询语句。
b) 对查询语句经过语法分析和语言分析得到一系列词(Term)。
c) 通过语法分析得到一个查询树。
d) 通过索引存储将索引读入到内存。
e) 利用查询树搜索索引,从而得到每个词(Term)的文档链表,对文档链表进行交,差,并得
到结果文档。
f) 将搜索到的结果文档对查询的相关性进行排序。
g) 返回查询结果给用户。















 1992
1992











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









