







目录
1 什么是监控
通常从技术角度来看,监控是衡量和管理技术系统的工具和流程。
但实际上,监控价值不止如此,它可以将系统和应用程序生成的指标转换成对应的业务价值。监控系统会将这些指标转换为衡量用户体验的依据,为业务提供反馈,确保为客户提供了所需的产品。监控不仅提供业务反馈,也提供对技术的反馈,指出哪些组件不起作用或者导致服务质量下降。
简而言之,监控系统有以下两个“客户”:
- 技术
- 业务
1.1 技术作为客户
监控系统第一个客户是技术,可能是研发、运维工程师、DevOps或者SRE。可以通过监控来了解技术环境状况,借用监控可以帮助检测、诊断和解决技术环境中的故障和问题。
同时,监控提供了大量的数据,帮助洞察关键的产品和技术决策,并衡量这些项目是否成功。监控也是产品管理生命周期以及内部客户关系的基础,有助于验证项目资金是否得到充分利用。
如有监控,且监控有效,就能拦截到线上很多的问题。
1.2 业务作为客户
业务是监控系统的第二个客户。监控系统是为了支撑业务,并确保业务持续开展。监控可以提供报告,使企业能够进行良好的产品和技术投资,有助于企业衡量技术带来的价值。
2. 监控基础知识
监控是管理基础设置和业务的核心工具。监控是必需的,应该和应用程序一起构建和部署。没有监控,相关人员无法了解系统环境、进行故障诊断、制定容量计划,也无法向组织提供系统的性能、成本和状态等信息。
好的监控实施不易,如果监控了错误的东西或者滥用监控,那么监控系统的价值将大大降低。以下列举监控的反例和解决措施。
2.1 事后监控
预则立,不预则废。监控也要在项目开发前考虑,很多不好的习惯喜欢在部署后进行监控指标设计。
与安全性一样,监控也应该是应用程序的核心功能。在为应用程序构建规范时,做概要设计时,务必考虑应用程序每个组件的监控指标。同时监控又是上线后的最后一个环节。
千万不要等到项目结束或者部署之前再做监控,否则可能有错过需要监控的指标的风险。

2.2 机械式/模板式/无脑式监控
许多公司或者团队始终复用它们过去使用的检查机制,而不会为新系统进行更新。常见的例子监控每台主机的CPU、内存和磁盘,但不监控可以知识主机上应用程序是否正常运行的关键指标(如返返回的HttpStatus、errorCode等与业务强相关的东西)。这种情况下的监控没有监控到关键的业务指标,收益不大,需要考虑监控的内容是否合理。
根据服务价值设计自上而下的监控系统是一个很好的方式,会帮助明确应用程序中更有价值的部分,并优先监控这些内容,再从技术堆栈中依次向下推进。

从业务逻辑和业务输出开始,向下到应用程序逻辑,最后再到基础设施。收集基础设施或操作系统/NODE指标可以协作定位问题以及容量规划,但不太能使用这些来报告应用程序的价值。切记不要机械式监控。
PS: 如果无法从业务指标开始,可以试着从靠近用户侧的地方开始监控。用户体验是推动业务发展的动力,了解它们的体验并发现它们合适遇到问题本身就很有价值。
2.3 不够准确的监控
这个监控中的大忌,常见形式是虽然监控了主机上的服务状态,但不够准确。比如监控HTTP项目,只通过检查Http 200的状态码衡量WEB应用程序是否征程运行,是不合理且不准确的。这种监控只会告诉应用程序正在响应请求,但不会反应业务是否返回了正确的数据。
所以需要找准服务监控的内容。比如监控业务的内容(Http返回的body)或者速率。这种情况下程序bug导致内容不正确马上能监控到。
2.4 静态监控
这种反例叫做静态阀值。常见如主机的CPU利用率超过80%就发出告警。这种检查通常是不灵活的布尔逻辑或者一段时间内的静态阈值,它们通常会匹配特定的结果或范围,这种模式有些情况还是较为适用,但是没有考虑到大多数复杂系统的动态性。
尽量不要用静态阈值,比较我们查看监控的时候,更喜欢查看数据窗口(如一段时间内的指标祈起伏变化的),而不是某个固定的时间点,需要使用更智能的技术来分析指标和阈值。笔者统计某些接口失败率,喜欢采用折线图,X轴是时间,Y轴是失败率,这样较为直观。
2.5 不频繁的监控
这种反例叫做不频繁的监控,即设置监控周期太长了(如每个2小时检查一次应用程序),导致检查之间丢失关键时间。合理设置监控周期,有以下好处:
- 识别故障或异常
- 满足响应时间预期——能在用户报告故障前找到问题。
- 提供更细粒度的数据,以识别性能的问题和趋势。
存储足够多的历史数据或者告警日志,能有效帮助识别性能的问题,解决偶现的重复问题。
2.6 缺少自动化或操作繁琐/不便
这也是一种反例。监控系统本身很难用,不方便用且使用门槛高的话,监测应用程序、收集数据或者可视化很难完成,那么应用程序开发人员会没有太多的使用欲望。
比如监控基础设施是经常挂不稳定的、手动维护的、过于复杂,由此可能产生问题,开发人员去配置这种复杂的监控规则是额外的工作量和负担。
应尽可能让监控系统的实施和部署自动化:
- 应该由配置管理进行部署,
- 主机和服务的配置应该通过自动发现或者自助提交来完成,这样的自动监控新的应用程序,而不需要人为添加。
- 添加检测应该很简单,而且是基于插件模式,开发人员应该能够把它放置在库中,或者使用图形化界面进行操作
- 数据和可视化应该是自助服务且有权限的。每个需要查看监控输出的人都应该能够查询和可视化这些内容。
2.7 监控模式总结
一个良好的监控系统能提供以下内容:
- 全局视角,从最高层(业务)依次展开。
- 协助故障诊断。
- 作为基础设施、应用程序开发和业务人员的信息源
- 内置于应用程序的设计、开发和部署的生命周期中
- 尽可能自动化,使用门槛低,能自己动手构建数据可视化。
3.监控机制
监控的方法有很多种,从单元测试、集成测试、冒烟测试或者是检查线上日志都可以算作监控的某种形式。监控和测试有一定的关联关系。
传统意义上,监控的定义侧重于检查和衡量应用程序的状态。
3.1 探针和内省
监控应用程序主要有两种方法:探针(probing)和内省(introspection)。探针监控是在应用程序的外部,通过查询应用程序的外部特征,如监控端口是否响应并返回正确的数据或状态码。K8S检查服务是否存活就是用的探针。Nagios也是一个主要基于探针监控的监控系统。
内省监控主要查看应用程序内部的内容。应用程序经过检测,并返回状态、内部组件,或者事务和事件性能的度量。这些数据可准确显示应用程序的运行方式,而不仅仅是其可用性或其表面行为。内省监控可以直接将事件、日志和指标发送到监控工具,也可以将信息发送给状态或者健康检查接口,然后由监控工具收集。Prometheus就是内省监控。
内省方法提供服务实际运行的状态,传递比探针监控更丰富的服务上下文信息,更贴近于实际业务指标。
这并不是说探针监控没有作用,了解应用程序的外部状态通常很有用,特别是如果服务由第三方提供,在没有深入了解其内部原理时,从外部查看服务的网络、安全性或可用性问题很有帮助。通常建议对安全网络进行探针监控以发现问题,使用内省监控进行报告和诊断。
3.2 拉取和推送
当前有两种执行监控检查的方式,即拉取(pull)和推送(push)。
基于拉取的监控方式会提取或检查远程应用程序——例如包含指标的端点,或者K8S探针检查。
基于推送的监控方式中,应用程序发送事件给监控系统接收。
两种方法有利有弊,没有绝对的好坏,使用过程中可以结合公司目前的技术栈进行抉择。
3.3 监控数据的类型
监控工具可以收集各种不同类型的数据,主要有以下两种形式:
- 指标:指标存储为时间序列数据,用于记录服务的状态,如接口请求次数、成功率、失败率等指标。
- 日志:日志通常是服务运行过程中产生的文件。ELK是常见的收集和管理日志的工具,可以在ELK做监控数据报表。
实际监控的过程中经常是指标+日志的方式进行监控。
4. 指标
指标在监控体系结构中相对直接,也常被视为故障检测的补充或手段。
但Prometheus改变了“指标作为补充”的观念,指标变成了检测工作流程中最重要的部分,也可以用来反应环境的状态、可用性以及性能。
正确使用指标可以提供基础设施的动态实时信息,有助于服务管理和做出有关系统的最佳决策。相信很多产品都问研发要过线上的运维指标,如日活、月活等指标,研发也关注过时延、成功率等指标,利用好指标能更好的优化服务。
同时,通过异常的检测和模式分析,指标有可能在故障或者问题发生前,就能提前察觉(比如CPU使用率持续攀高),最差也能在问题发生后立马能让相关人员有所反应。
4.1 什么是指标
指标是软件和硬件组件属性的度量。为了使指标有价值,我们会跟踪其状态,通常记录一段时间内的数据点。这些数据点称为观察点(observation),观察点通常包含值、时间戳,有时也涵盖描述观察点的一系列属性(如源或者标签)。观察的集合称为时间序列。
时间序列数据典型的范例是网站访问量、点击量等指标,在不同时间点记录不同的访问/点击数,组成对应的报表/折线图。
我们常以固定的时间间隔收集数据,该时间间隔被称为颗粒度(granularity)或者分辨率(resolution),取值可以从1S到5Min,甚至1H或者更长。合理选择指标颗粒度很重要,颗粒度越大容易错过细节。颗粒度越小,则需要存储和分析大量数据。
另外就是以图形展示指标比较直观,如统计服务总请求量时,X轴是时间,Y轴是各时间请求量大小。
4.2 指标类型
指标类型有很多种。
| 指标类型 | 说明 | 使用场景 |
| 测量型(gauge) | 是上下增减的数字,本质上是特定度量的快照。 | CPU使用率 内存使用率 磁盘使用率 网站客户数量 |
| 计数型(counter) | 随着时间增加而不会减少的数字。虽然永远不会减少,但有时可以将其重置为0并再次递增。 优势:可以让你计算变化率,并通过变化率理解很多有用信息。如登录次数指标,可以计算变化率查看每秒的登录次数,有助于确定网站在某个时间段受欢迎的程度。 | 用户登录次数 月销售商品数量 日收到订单数量 |
| 直方图 (histogram) | 是对观察点进行采样的指标类型,可以展现数据集的频率分布。将数据分组在一起并以这样的方式显示,这个被称为“分箱”(binning)的过程可以直观地查看数值的相对大小。 直方图可以很好地展现时间序列数据,尤其适用于数据的可视化,如请求时延分位。 | 身高频率分布样本直方图(x轴是身高分布,y轴是对应的频率值) 年龄人口分布样本直方图(x轴是年龄分布,y轴是对应的频率值) |
4.3 指标摘要
一般来说,单个指标对我们价值很小,往往需要联合并可视化多个指标,该过程需要应用一些数学变换。如将统计函数应用于指标或指标组,常见的函数如下:
- 计数:计算特定时间间隔内的观察点数。
- 求和:将特定时间间隔内所有观察点的值累计相加。
- 平均值:提供特定时间间隔内所有值的平均值。
- 中间数:数值的几何中点,正好50%的数值位于它前面,而另外50%则位于它后面。
- 百分位数:度量占总数特定百分比的观察点的值。
- 标准差:显示指标分布中与平均值的标准差,可以测量出数据集的差异成都。标准差为0表示数据都处于平均值,较高的标准差意味着数据分布的范围很广。
- 变化率:显示时间序列中数据之间的变化程度。
4.4 指标聚合
单一指标和聚合指标的组合可以提供最佳的监控视角,前者可以深入到某个特定问题,而后者可以查看更高阶的状态。
4.4.1 平均值
平均值是标准的指标分析方法。实际上,几乎所有曾经监控或分析过网站及应用程序的人都会使用平均值。许多公司的生死存亡都取决于网站或者api的平均响应时间。
缺点:平均值缺陷,如api的平均值只有3S,但可能有部分用户响应时间会达到5S以上。
4.4.2 中间数
中间数在真实环境中不太现实,全国人民收入的中间数并不能反映出贫富差距。
识别性能问题的另一种常用技术是根据平均值来计算指标的标准差。
4.4.3 标准差
标准差衡量数据集的变化或分布。
与平均值和中间数一样,当数据呈正太分布时,标准差最有效。在正态分布中,有一种简单的方式来阐明分布:经验法则,又称3-sigma法则或者68-95-99.7法则。
经验规则是统计规律,指出了在正态分布,几乎所有数据都将落在均值的三倍标准差内。所述经验规则表明,68%的数据将分布在的第一个标准偏差之内,95%将落在第二个标准差之内,和99.7%将落在均值的前三个标准偏差之内。
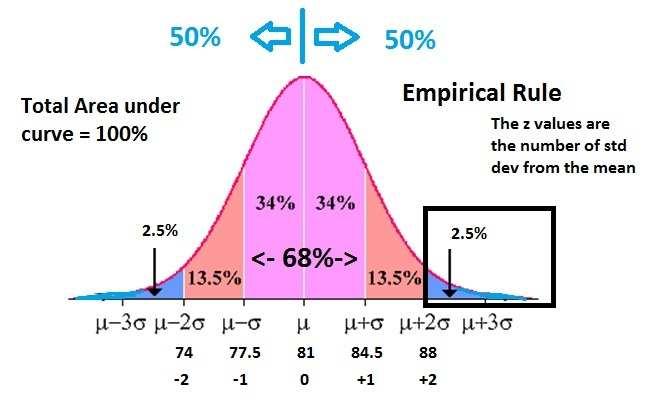
许多监控方法会利用经验法则,当出现超过两个平均值的标准差的事务或事件时触发警报,以捕获性能的异常值。但如果数据不是正太分布的,最终的标准差可能会误导人。
到目前为止,上述方法在识别异常数据方面没有提供很大帮助,但下一个统计方法(百分位数)存在可能。
4.4.4 百分位数
百分位数度量的事占总数特定百分比的观察点的值。从本质上来讲,是展示数据的分布。
我们在上面看到的中间数是50百分位数(或p50)。对于中间数(已排好序的数据)来说,50%的值低于它,50%高于它。对于指标而言,百分位很有意义,因为它可以清晰地展现数值的分布。一个API的99百分位数为10毫秒,就代表99%的API能在10毫秒或更短时间内完成,1%的API事务处理时间超过10毫秒。
百分位数是分位数的一种。
百分位数是识别异常值的理想选择。如上,如果99%的API都能在10毫秒返回,那我们专注于解决1%性能问题就好。当然普通的API能在10毫秒返回结果已经很快了。
另外测量延迟时,最好可以展示以下几项内容:
- 50百分位数(或中间数/50分位)
- 99百分位数(也叫99分位)
- 最大值
添加最大值有助于可视化所测量指标的边界,一个较高的最大值会使图中的其他值显得渺小。实际工作中,构建检查和收集指标时,常会以百分位数和其他指标聚合。
5. 监控方法论
在指标和指标聚合之上结合使用多种监控方法,以帮助加强监控。 我们将结合以下两种监控方法:
- Brendan Gregg 的USE(Utilization、Saturation和Error)方法,侧重于主机级监控。
- Google的四个黄金指标,专注于应用程序级监控。
5.1 USE方法
USE是使用率(Utilization)、饱和度(Saturation)和错误(Error)的缩写,该方法是Netfix的内核和性能工程师Brendan Gregg开发的。USE方法建议创建服务器分析清单,以便快速识别问题。
可以利用从你的环境中收集的数据,对照清单来确定常见的性能问题。
USE方法可以概括为:针对每个资源,检查使用率、饱和度和错误。以上术语详解如下:
- 资源:系统的一个组件,传统意义上的物理服务器组件,如CPU、磁盘等,当然也可以包含软件资源。
- 使用率:资源忙于工作的平均时间。它通常用随时间变化的百分比表示。
- 饱和度:资源排队工作的指标,无法再处理额外的工作。通常用队列长度表示。
- 错误:资源错误事件的计数。
将使用率、饱和度和错误等定义结合起来创建一份资源清单是常见的做法。但要采用一种方法来监控每个要素,有以下示例。
对于CPU:
- CPU使用率随时间的百分比。
- CPU饱和度,等待CPU的进程数。
- 错误,通常对CPU资源不太影响。
对于内存:
- 内存使用率随时间的百分比。
- 内存饱和度,通过监控swap测量。
- 错误,通常不太关键,但可以捕获。
其他组件以此类推,直到我们找到了问题的瓶颈或信号。
5.2 Google的四个黄金指标
Google的四个黄金指标来自Google SRE手册,指定了监控中的一系列指标类型。该方法中的指标类型主要关注的不是系统级的时间序列数据,更多的是针对应用程序或面向用户的部分:
- 延迟:服务请求所花费的时间,但需区分成功请求和失败请求。如失败请求可以在很短时间内返回结果。
- 流量:针对系统,如 每秒HTTP请求数,或者数据库系统的事务。
- 错误:请求失败的速率,要么是HTTP 500错误等显示失败,要么是返回错误内容或无效内容等隐形失败,或者基于策略原因导致的失败(如强制要求响应时间超过30ms的请求视为错误)。
- 饱和度:服务占用资源的程度,基于受限的资源,如内存或IO。还包括即将饱和的部分,如正在快速填充的磁盘。
黄金指标使用起来很简单,依次选择对应的高阶指标,然后为它们设置警报。如果其中一个指标出现问题,那么警报就会响起,然后你可以去诊断/解决问题。
PS:另外市面上还有RED的监控框架,即Rate、Error和Duration。
6. 警报和通知
监控工具的主要输出是警报和通知。
警报会在某些时间发生(如指标达到阈值)时触发。但并不意味着有人会被告知此事件的发生,通知会解决该问题。通过电子邮件、短信、微信、钉钉等手段,通知接收警报并告知某人或某事是业界常见的做法。
要建立一个优秀的通知系统,需要考虑以下基础信息:
- 哪些问题需要通知
- 谁需要被告知
- 如何告知他们
- 多久告知他们一次
- 何时停止告知以及何时升级到其他人
如果配置不当,或生成过多的通知,那么接收人员无法对它们采取任何行动,甚至可能将它们忽略掉。收件箱中来自监控系统的成千上万封通知邮件会造成警报疲劳,因此需要考虑通知的内容,让其简洁、清晰、准确、易于理解并且可操作。设计有价值、有意义的通知至关重要。
总结优秀的监控通知,需要考虑以下信息:
- 使通知清晰、准确、可操作。【谨记通知是人阅读的而不是计算机阅读的】
- 为通知添加上下文。通知应包含组件的其他相关信息。
- 仅仅发送有意义的通知。
7. 可视化
数据可视化是一门强大的分析和解释技术,也是一种令人惊叹的学习工具。理想的可视化应该能够清晰地显示数据,突出重点而不是仅仅提高视觉效果。
数据可视化可以参考以下规则进行构建:
- 清晰地显示数据
- 可视化数据能引发思考(而不仅仅是为了好看)
- 避免扭曲数据
- 使数据集保持一致
- 允许更改颗粒度而不影响理解















 4910
4910











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









