







代码下载: http://pan.baidu.com/s/1kTr9eAj
以下是我对CART的一些理解,剪枝部分随后会和大家一起分
享,欢迎大家一起讨论。
分类回归树算法:CART (Classification And Regression Tree) 算法采用一种二分递归分割的技术,将当前的样本集分为两个子样本集,使得生成的每个非叶子节点都有两个分支。CART算法生成的决策树是结构简洁的二叉树。
CART使用如下结构的学习样本集:L={X_1,X_2,...X_3,Y}
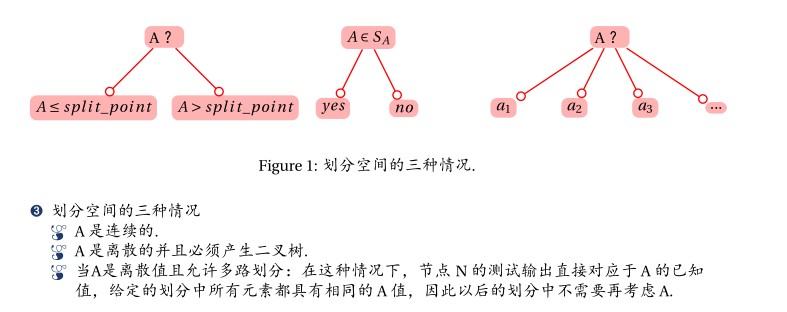
其中,X_1-X_m称为属性向量,既可以为连续属性,也可以是离散属性,Y称为标签向量,他们所包含的属性既可以是有序或连续的(ordered or numerical),也可以是离散的。当Y为有序数量值时,称为回归树;当Y是离散值时,称为分类树。
分类树两个基本思想:第一个是将训练样本进行递归地划分自变量空间进行建树的想法,第二个是用验证数据进行剪枝。

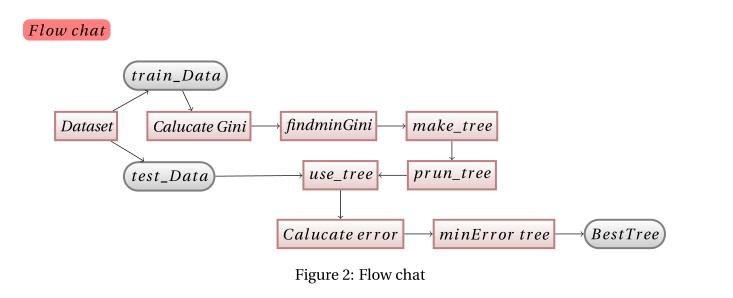
生成决策树
建树:在分类回归树中,我们用类别集Targets表示因变量,选取的属性集 Attributelist 表示自变量,通过递归的方式利用 Attributelist 把p 维空间划分为不重叠的矩形.

function tree = make_tree(patterns, targets,Dlength, split_type, inc_node)
%Build a tree recursively
%Dlength为样本个数
% 判断是否为单节点树
if (length(unique(targets)) == 1),
%There is only one type of targets, and this generates a warning, so deal with it separately
tree.right = [];
tree.left = [];
tree.Raction = targets(1);
tree.Laction = targets(1);
tree.Resub = 0;
tree.label = targets(1);
return
end
% Ni始终等于属性个数
[Ni, M] = size(patterns);
Nt = unique(targets); % 分类情况
N = hist(targets, Nt); % N为分类个数统计情况
tree.Resub = ( M - max(N) )/ Dlength;
tree.label = Nt(N == max(N));
% if T都属于同一类别or T中只剩下 一个样本
% 结束条件
% 分配类别的方法可以用当前节点中出现最多的类别
% tree's last level | tree.Resub < 1e-3
if ((sum(N < Dlength*inc_node) == length(Nt) - 1) | (M == 1)),
%No further splitting is neccessary
tree.right = [];
tree.left = [];
if (length(Nt) ~= 1),
% 找到实例数最大的类作为该结点的类标记
MLlabel = find(N == max(N));
else
MLlabel = 1;
end
tree.Raction = Nt(MLlabel);
tree.Laction = Nt(MLlabel);
else
%Split the node according to the splitting criterion
% 分裂标准
deltaI = zeros(1,Ni); % Ni=2
split_point = zeros(1,Ni);
for i = 1:Ni,
% 'CARTfunctions' 得到Gini最小的划分
% 'feval' 调用函数
% varargin提供了一种函数可变参数列表机制
% split_point(i) = fminbnd('CARTfunctions', min(patterns(i,:)), max(patterns(i,:)), op, patterns, targets, i, split_type);
split_point(i) = findminGini( patterns, targets, i );
I(i) = feval('CARTfunctions', split_point(i), patterns, targets, i);
end
% 选择最优特征和最优切分点
[m, dim] = min(I);
loc = split_point(dim);
%So, the split is to be on dimention 'dim' at location 'loc'
indices = 1:M; %M为样本个数
tree.Raction = ['patterns(' num2str(dim) ',indices) ~= ' num2str(loc)];
tree.Laction = ['patterns(' num2str(dim) ',indices) == ' num2str(loc)];
in_right = find(eval(tree.Raction));
in_left = find(eval(tree.Laction));
if isempty(in_right) | isempty(in_left)
%No possible split found
tree.right = [];
tree.left = [];
if (length(Nt) ~= 1),
MLlabel = find(N == max(N));
else
MLlabel = 1;
end
tree.Raction = Nt(MLlabel);
tree.Laction = Nt(MLlabel);
else
%...It's possible to build new nodes
% 递归 targets(in_right)... targets(in_left)
tree.right = make_tree(patterns(:,in_right), targets(in_right), Dlength, split_type, inc_node);
tree.left = make_tree(patterns(:,in_left), targets(in_left), Dlength, split_type, inc_node);
end
endfunction index = findminGini( patterns, targets, dim)
%UNTITLED Summary of this function goes here
% Detailed explanation goes here
% Fin minimum Gini
Nt = unique(patterns(dim,:));
% 测试属性的每个取值
for i = 1:length(Nt)
Gini(i) = CARTfunctions(Nt(i), patterns, targets, dim);
end
% 取最小基尼系数,返回index
D = find(Gini == min(Gini));
index = Nt(D(1));
end
function delta = CARTfunctions(split_point, patterns, targets, dim)
%Calculate the difference in impurity for the CART algorithm
Uc = unique(targets);
% D1,D2
for i = 1:length(Uc),
in = find(patterns(dim,:) == split_point);
out = find(patterns(dim,:) ~= split_point);
if numel(in) == 0,
Pl(i) = 0 ;
else
Pl(i) = length(find(targets(in) == Uc(i)))/length(in);
end
if numel(out) == 0,
Pr(i) = 0 ;
else
Pr(i) = length(find(targets(out) == Uc(i)))/length(out);
end
end
%Gini=1-sum(pi(n)^2)
Er = 1 - sum(Pr.^2);
El = 1 - sum(Pl.^2);
P = length(find(patterns(dim, :) == split_point)) / length(targets);
delta = P*El + (1-P)*Er;
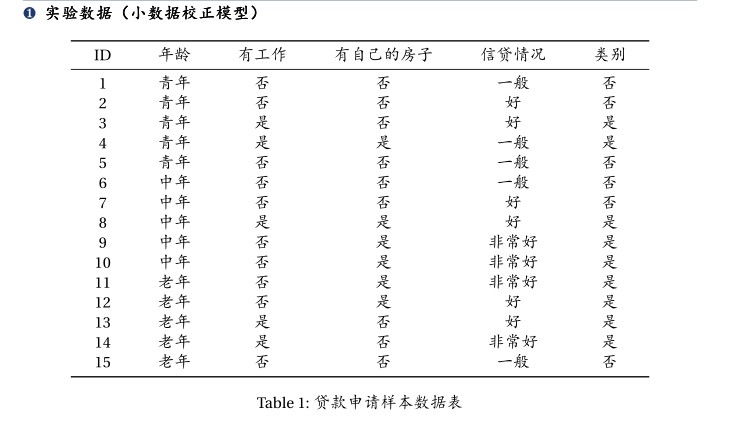


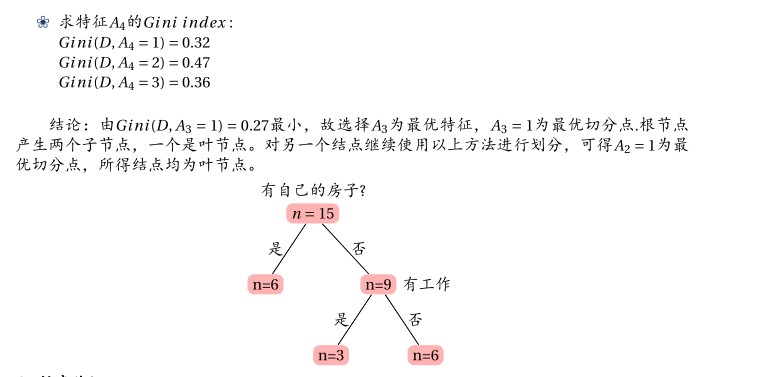


<pre name="code" class="python">















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









