







课程目标:
1.聊聊翻译能力落地时需要考虑的方方面面
2.如何根据业务需求定制一个翻译模型
3.谈谈一些快速提升翻译质量的小技巧
为什么要做机器翻译?
日常人们如何使用翻译?
手机上的翻译产品形态:
机器翻译如何落地?
目录:
-
做算法前先了解你的业务
-
算法不仅是NMT模型
-
数据决定了翻译效果的上限
-
科学评测指引优化方向
-
工程工作同样很重要
-
做算法前先了解你的业务
核心人群:

高频场景分析:

需要的翻译技术类型:
-
算法不仅是NMT模型
总体流程:

语种检测:

中英文分词:
中文分词:优化分词错误,提升翻译质量。
英文分词:将用户拼写错误、OCR错误粘贴的英文单词分割开。

文本处理:
模块作用:主要包括Tokenize,Detokenize,Truecase,Detruecase, Recase做翻译前后的大小写和标点处理。

长句拆分:
模块作用:将长句子、段落拆分成合适模型长短的句子。

混合语种文本拆分:
模块作用:将不同语种的句子拆开处理。

模型领域适应:
1.领域数据微调
•领域分类器
•领域相似句子检索

2.模型领域自适应
•数据侧:训练领域分类器,打上领域Label;
•模型侧:在每个encoder 和 decoder 添加一层Adapter层训练。

模型鲁棒性增强:
•随机替换ground truth单词
论文:Bridging the Gap between Training and Inference for Neural Machine Translation
•平滑标签算法( graduated label smoothing )
论文: On the Inference Calibration of Neural Machine Translation
•生成对抗样本
论文: Robust Neural Machine Translation with Doubly Adversarial Inputs
论文: Robust Adversarial Augmentation for Neural Machine Translation
•随机修改数据
修改句末标点、单词粘粘、句末单词不完整等

3. 数据质量决定了翻译效果的上限
拆解分析训练数据:


单语数据搜集与清洗:
•单语数据作用:增强生成译文流畅度、地道程度
•筛选方法:语言模型(ppl)、分类模型

双语数据搜集与清洗:
开源双语数据源:
•历年的WMT、CCMT、statmt会议提供数据
•UN联合国平行语料库
•维基百科语料
•Opus多语种网站
•Github开源数据
•可可英语、沪江英语的双语例句
01规则过滤方法
•长度信息:长度、长度比、平均token长度
•编码范围:有效token占比、 其他语言占比、特殊字符占比
02概率模型方法
•句子中词、短语互译概率
•句子语言模型概率
•I8M对齐模型、Moses词对齐模型
•WMT04 top1 阿里
03损失函数方法
•高质量基础翻译模型
•模型预测与目标译文的loss值
•代表工作:WMT04 top0 微软 对偶条件交叉嫡损失函数
04向量相似度方法
•多语言句子向量表示
•动态词向量表示
•计算源端目标端向量距离、余弦相似度
05分类模型方法
•将语料清洗任务转化为二分类任务
•高质量句对正例样本和噪声句对负例样本
06预训练模型方法
•阿里WMT1-1- 训练双向双语GPT+1模型
•华为WMT1-1- 微调跨语言预训练模型XLM+R
•字节WMT1-1- 训练2个XLM模型,模型集成+重排序
翻译模型如何"本土化":

从细节处优化翻译体验:
-
俚语翻译增强:

-
数字、时间、日期表达式翻译增强

-
缩写翻译增强

-
序号翻译增强
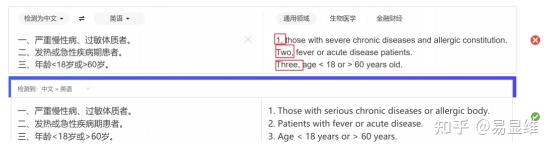
-
人名翻译增强

-
地名翻译增强

从细节处优化翻译体验——业务场景
 4. 科学评测指引优化方向
4. 科学评测指引优化方向
翻译评测:
"信"指意义不悖原文,即译文要准确,不偏离, 不遗漏,也不可随意增减含义;
"达"指不拘泥于原文形式,译文通顺明白;
"雅"则指译文时选用的词语要得体,追求文章本身的古雅,简明优雅。

5. 工程工作同样很重要
性能优化:

线上快速修复:
•检索库:紧急修复错误翻译
•翻译干预:快速修复句中术语翻译错误

模型迭代优化闭环:

总结&展望:
技术层面
•预训练模型,充分应用海量单语文本数据
•多模态翻译能力,图像翻译、语音翻译
用户导向
•将技术落地到真正解决用户问题的地方去
•提升场景下用户的翻译交互体验















 286
286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









