






前戏作者:Dhruvil Karani
编译:ronghuaiyang
给大家介绍一些词嵌入和word2vec的一些基础内容,非常的浅显,都可以看得懂。
词嵌入是文档词汇表最常用的表示形式之一。它能够捕捉文档中某个单词的上下文、语义和句法相似性、与其他单词的关系等。
词嵌入到底是什么?粗略地说,它们是特定单词的向量表示。说了这么多,接下来是我们如何生成它们?更重要的是,它们如何捕获上下文的?
Word2Vec是利用浅层神经网络学习词嵌入的最常用技术之一。它由Tomas Mikolov于2013年在谷歌开发。
让我们一步一步来解决这个问题。
我们为什么需要词嵌入?
考虑下面类似的句子: Have a good day 和 Have a great day.。它们几乎没有不同的意思。如果我们构建一个详尽的词汇表(我们称它为V),那么V = {have, a, good, great, day}。
现在,让我们为V中的每一个单词创建一个独热编码的向量。我们的独热编码向量的长度等于V(=5)的大小。我们会得到一个除了表示词汇表中相应单词的索引处的元素,这个特定的元素是1,其他全是0的向量。下面的编码可以更好地解释这一点。
Have = [1,0,0,0,0]‘; a=[0,1,0,0,0]’ ; good=[0,0,1,0,0]‘ ; great=[0,0,0,1,0]’ ; day=[0,0,0,0,1]’ (‘ 表示转置)
如果我们试着去可视化这些编码,我们可以想象一个5维空间,其中每个单词占据一个维度,而与其他维度无关(没有沿其他维度的投影)。这意味着“good”和“great”的不一样的程度就像“day”和“have”的不一样的程度是相同的,这是不对的。
我们的目标是让具有相似上下文的单词具有相近的空间位置。从数学上讲,这两个向量夹角的余弦值应该接近1,也就是角度接近0。

这就产生了生成分布表示的想法。直观地说,我们引入了一个单词对另一个单词的依赖关系。在这个单词的上下文中,这些单词会得到更多的这种依赖性。在一个独热编码表示中,所有单词都是相互独立的。
Word2Vec该怎么得到呢?
Word2Vec是一种构造这种嵌入的方法。它可以通过两种方法得到(都涉及到神经网络):Skip Gram和Continuous Bag Of Words, CBOW。
CBOW模型:该方法将每个单词的上下文作为输入,并尝试预测与上下文对应的单词。考虑我们的例子:Have a great day.
让输入到神经网络的单词是,great。注意,这里我们尝试使用单个上下文输入单词great预测一个目标单词(day)。更具体地说,我们使用输入字的一个独热编码,并度量与目标单词(day)的独热编码之间的误差。在预测目标单词的过程中,我们学习了目标单词的向量表示。
让我们更深入地了解实际的架构。
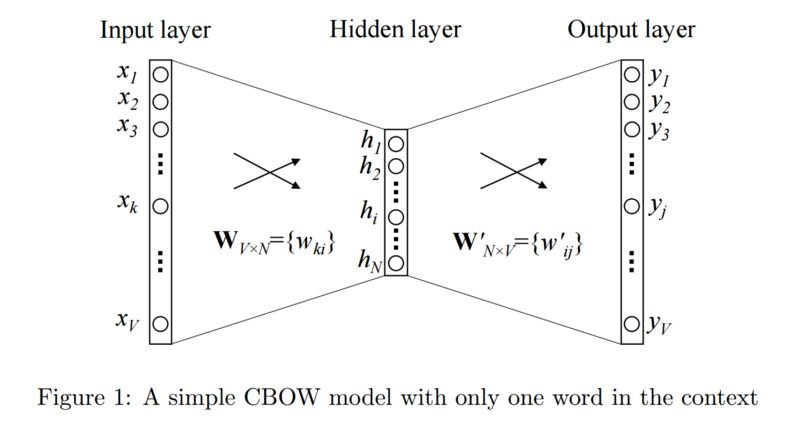
输入或上下文单词是一个长度为V的独热编码向量。隐藏层包含N个神经元,输出也是一个V长度向量,其中元素为softmax值。
让我们了解一些图中的术语:
Wvn是将输入x映射到隐藏层(V*N维矩阵)的权重矩阵
Wnv是将隐藏层输出映射到最终输出层(N*V维矩阵)的权重矩阵
我就不讲数学了。我们只需要知道发生了什么。
隐藏层神经元只是将输入进行加权和复制到下一层。没有像sigmoid, tanh或ReLU那样的激活。唯一的非线性计算是输出层的softmax。
但是,上面的模型使用单个上下文单词来预测目标。我们可以使用多个上下文单词来做同样的事情。
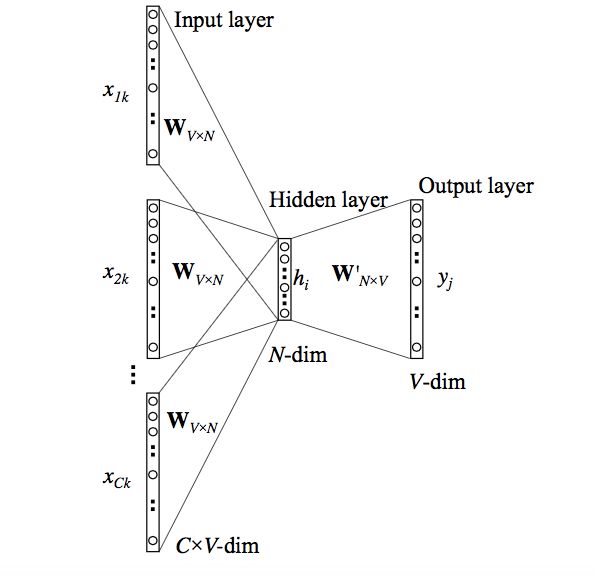
上面的模型使用C个上下文单词。当Wvn用于计算隐藏层输入时,我们对所有这些C上下文字输入取平均值。
我们已经看到了如何使用上下文单词生成单词表示。但是还有一种方法我们可以做同样的事情。我们可以使用目标词(我们希望生成其表示)来预测上下文,并在此过程中生成表示。另一种称为Skip Gram模型的变体可以做到这一点。
Skip-Gram模型:
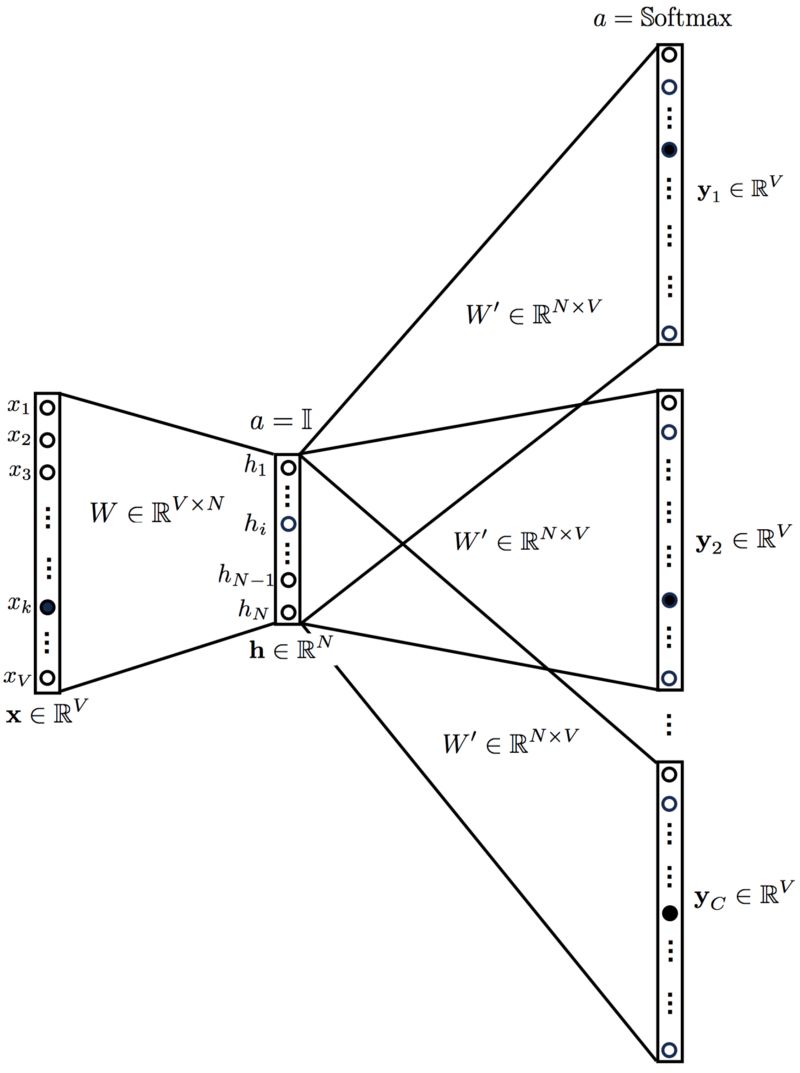
这看起来像是把多上下文CBOW模型翻转过来。这在某种程度上是正确的。
我们把目标词输入网络。模型输出C个概率分布。这是什么意思?
对于每个上下文位置,我们得到V概率的C个概率分布,每个单词一个。
在这两种情况下,网络都使用反向传播来学习。详细的数学计算可这里找到。
谁比较厉害?
两者都有自己的优点和缺点。Mikolov说,Skip Gram可以很好地处理少量数据,并且可以很好地表示罕见的单词。
另一方面,CBOW更快,对于更频繁的单词有更好的表示。
前方还有哪些内容?
以上的解释是一个非常基本的解释。它只是让你对词嵌入是什么,以及Word2Vec如何工作有了一个高层次的了解。
还有很多事情要做。例如,为了提高算法的计算效率,使用了分层Softmax和Skip-Gram负采样等技巧。所有这些都可以在这里(https://arxiv.org/pdf/1411.2738.pdf)找到。
 —
END—
—
END—
英文原文:https://towardsdatascience.com/introduction-to-word-embedding-and-word2vec-652d0c2060fa

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!![]()














 1735
1735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









