







下图即为该hashtable的结构:
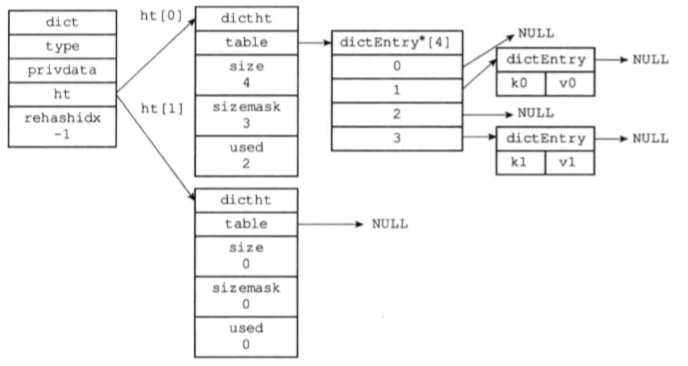
主要提炼几点:
hashtable的size必须是2的n次方:
为了快速的将每个键的hash value转化为array index
type以及privdata:
因为字典在redis中有多处应用,所以基于字典的不同应用需要不同的函数,type结构体中保存一组操作函数,privdata主要提供不同应用的私有数据;
关于rehash:
随着操作的不断执行,hashtable中的键值对会逐渐增加或减少,为了让整个hashtable的负载因子维持在一个合理区间内,程序会对hashtable进行相应的扩展或是收缩。这时候就是为ht[1]申请一段内存,将ht[0]中的所有键值对都迁移至ht[1]中。
扩展与收缩的大致流程:
- 确定ht[1]所需内存大小。若是扩展hashtable,那么大小为第一个大于等于ht[0].used * 2的值,该值必须为2的n次方;若是收缩hashtable,那么大小为第一个大于等于ht[0].used的值,该值必须为2的n次方
- 将所有ht[0]中的键值对重新进行hash,index至ht[1]中
- 当所有的ht[0]中的键值对都迁移到ht[1]中后,释放ht[0],将ht[1]设置为ht[0],为ht[1]创建一个空的hashtable
程序什么时候自动扩展或收缩:
- 当服务器没有在执行BGSAVE命令或是BGREWRITEAOF命令时,hashtable的负载因子大于等于1时,自动扩展;
- 当服务器正在执行BGSAVE命令或是BGREWRITEAOF命令时,hashtable的负载因子大于等于5时,自动扩展;
执行BGSAVE命令或是BGREWRITEAOF命令时,redis需要创建子进程,而多数系统采用copy-on-write技术,所以在此期间,尽量避免不必要的内存写入操作,最大限度的节约内存。
- 当hashtable的负载因子小于0.1时,自动收缩;
如何rehash:
数据量小的话,自然可以直接rehash,一旦数据达到千万级,亿级,可极大影响性能。
为了避免上述影响,redis不是一次将所有键值对迁移至ht[1],而是分多次,渐进式的迁移。
rehash步骤:
- 为ht[1]分配空间。让字典同时持有ht[0],ht[1]
- 令变量rehashidx值为0,表示rehash工作开始。
- 在rehash期间,每次对字典执行的添加,删除,查找或是更新操作时,程序会额外的进行rehash操作,将rehashidx位置上的键值对迁移到ht[1]中,完成后rehashidx的值加一,等待下一次操作从而继续rehash。
- 在ht[0]中的所有键值对都迁移到ht[1]中后,rehashidx的值被设置为-1,表示rehash操作完成
rehash期间操作:
- 在rehash操作过程中,字典同时持有两个hashtable。所以在执行删除查找更新操作时候会在两个表上进行操作。比如查找一个键没有出现在ht[0]上,就要去ht[1]中继续查找,诸如此类。
- 如果是添加新元素,那么直接添加到ht[1]中,保证ht[0]中的元素是不断减少的。

















 4727
4727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









