





Object Removal by Exemplar-Based Inpainting
通过基于样本块的图像修复来实现遮挡物移除
Abstract:
A new algorithm is proposed for removing large objects from digital images. The challenge is to fill in the hole that is left behind in a visually plausible way.
In the past, this problem has been addressed by two classes of algorithms: (i) “texture synthesis” algorithms for generating large image regions from sample textures, and (ii) “inpainting” techniques for filling in small image gaps. The former work well for “textures” – repeating twodimensional patterns with some stochasticity; the latter focus on linear “structures” which can be thought of as onedimensional patterns, such as lines and object contours.
This paper presents a novel and efficient algorithm that combines the advantages of these two approaches. We first note that exemplar-based texture synthesis contains the essential process required to replicate both texture and structure; the success of structure propagation, however, is highly dependent on the order in which the filling proceeds. We propose a best-first algorithm in which the confidence in the synthesized pixel values is propagated in a manner similar to the propagation of information in inpainting. The actual colour values are computed using exemplar-based synthesis. Computational efficiency is achieved by a blockbased sampling process.
A number of examples on real and synthetic images demonstrate the effectiveness of our algorithm in removing large occluding objects as well as thin scratches. Robustness with respect to the shape of the manually selected target region is also demonstrated. Our results compare favorably to those obtained by existing techniques.
摘要:
针对移除数字图像中大的物体,本文提出一个新的算法,它的挑战在于用合适的方法填补图像缺失的部分。
在过去的方法中,过去,这一问题通过两类算法来解决:(i)“纹理合成”算法:通过样本纹理生成图像丢失的大区域,(i i)“修复”技术:填充图像的小间隙。前者在“纹理”上具有很好的效果——它通过一些随机性的重复二维部分,后者着眼于线性结构,它可以被看做是一维模式,例如线条或者物体的轮廓。
这篇文章结合上述两种算法,提出了一种新的高效的方法。我们首先注意到基于样例的纹理合成过程中需要包含必要的纹理和结构两个方面的复制。然而,结构修复的成功很大程度上取决于填充的顺序。我们提出了一种最佳优先算法,该算法合成像素值中的置信度(好像是一个评判指标,论文的后面应该会介绍到)的传播类似于在修复图像过程中信息传播的方式传播。实际颜色值的计算则是基于样例的合成。计算效率是通过基于块的采样过程来实现的。
在真实和合成图像上的大量例子表明了我们的算法在去除大的物体遮挡和小的划痕方面上都是有效的。并且对人工选择的目标区域形状的鲁棒性也进行了论证。我们的结果优于现有技术的结果。
1. Introduction
This paper presents a novel algorithm for removing objects from digital photographs and replacing them with visually plausible backgrounds. Figure 1 shows an example of this task, where the foreground person (manually selected as the target region) is replaced by textures sampled from the remainder of the image. The algorithm effectively hallucinates new colour values for the target region in a way that looks “reasonable” to the human eye.
1.介绍
本文提出了一种新的算法,用于去除数字图像中不需要的物体,并将其替换为视觉上可信的背景。图1显示了这个任务的一个示例,其中前景人物(手动选择作为目标区域)被从图像其余部分采样的纹理替换。该算法有效地为目标区域产生新的颜色值,使人眼看起来“合理”。

In previous work, several researchers have considered texture synthesis as a way to fill large image regions with “pure” textures – repetitive two-dimensional textural patterns with moderate stochasticity. This is based on a large body of texture-synthesis research, which seeks to replicate texture ad infinitum, given a small source sample of pure texture [1, 8, 9, 10, 11, 12, 14, 15, 16, 19, 22]. Of particular interest are exemplar-based techniques which cheaply and effectively generate new texture by sampling and copying colour values from the source [1, 9, 10, 11, 15].
As effective as these techniques are in replicating consistent texture, they have difficulty filling holes in photographs of real-world scenes, which often consist of linear structures and composite textures – multiple textures interacting spatially [23]. The main problem is that boundaries between image regions are a complex product of mutual influences between different textures. In constrast to the twodimensional nature of pure textures, these boundaries form what might be considered more one-dimensional, or linear, image structures.
A number of algorithms specifically address this issue for the task of image restoration, where speckles, scratches, and overlaid text are removed [2, 3, 4, 7, 20]. These image inpainting techniques fill holes in images by propagating linear structures (called isophotes in the inpainting literature) into the target region via diffusion. They are inspired by the partial differential equations of physical heat flow,and work convincingly as restoration algorithms. Their drawback is that the diffusion process introduces some blur, which is noticeable when the algorithm is applied to fill larger regions.
The algorithm presented here combines the strengths of both approaches. As with inpainting, we pay special attention to linear structures. But, linear structures abutting the target region only influence the fill order of what is at core an exemplar-based texture synthesis algorithm. The result is an algorithm that has the efficiency and qualitative performance of exemplar-based texture synthesis, but which also respects the image constraints imposed by surrounding linear structures.
之前的图像修复工作中,一些研究人员认为纹理合成是用“纯”纹理去填充图像中丢失的大区域的方法——用适度的随机性重复二维纹理部分。这类方法基于大量的纹理合成研究去寻求复制纹理,并给出一个小的纯纹理源样本[1,8,9,10,11,12,14,15,16,19,22]。特别值得关注的是基于示例的技术,通过从源图像中采样和复制颜色值,可以通过较低的代价有效地生成新的纹理[1、9、10、11、15]。
尽管这些技术在复制一致的纹理方面很有效,但它们很难填补真实场景照片中的漏洞。真实场景通常包括了线性结构和复合纹理结构,复合纹理结构是指多个纹理在空间上相互作用[23]。主要问题是图像区域之间的边界是不同纹理之间相互影响的复杂产物。在构造二维自然图像的纯纹理时,这些边界形成了可能被认为是一维或线性的图像结构。
许多的算法专门去除斑点、划痕和重叠文本[2、3、4、7、20]。这些图像修复技术通过扩散将线性结构(在图像修复文献中称为等压线)传播到目标区域来填补图像中的漏洞。它们受到物理热流(?)偏微分方程的启发,并且在恢复算法上取得了令人信服的成就。它们的缺点是扩散过程会引入一些模糊,当应用该算法填充较大的区域时,这种模糊很明显。
本文提出的算法结合了这两种方法的优点。与图像修复方法一样,我们特别注意线性结构。但是,与目标区域相邻区域的线性结构只影响核心区域的填充顺序,这是一种基于示例的纹理合成算法。该算法不仅具有基于实例的纹理合成的效率和定性性能,而且还考虑了周围线性结构对图像的约束。
Our algorithm builds on very recent research along similar lines. The work in [5] decomposes the original image into two components; one of which is processed by inpainting and the other by texture synthesis. The output image is the sum of the two processed components. This approach still remains limited to the removal of small image gaps, however, as the diffusion process continues to blur the filled region (cf., [5], fig.5 top right). The automatic switching between “pure texture-” and “pure structure-mode” described in [21] is also avoided.
One of the first attempts to use exemplar-based synthesis specifically for object removal was by Harrison [13]. There, the order in which a pixel in the target region is filled was dictated by the level of “texturedness” of the pixel’s neighborhood. Although the intuition is sound, strong linear structures were often overruled by nearby noise, minimizing the value of the extra computation. A related technique drove the fill order by the local shape of the target region, but did not seek to explicitly propagate linear structure [6].
我们的算法建立在最近类似研究的基础上。[5]中的工作将原始图像分解为两个部分,一个部分通过着色处理,另一个部分通过纹理合成处理。输出图像是两个处理的总和。但是,这种方法仍然局限于去除较小的图像间隙,因为扩散过程会持续模糊填充区域(参见[5],图5右上角)。它也避免了[21]中描述的“纯纹理”和“纯结构模式”之间的自动切换。
Harrison[13]首次尝试使用基于实例的合成来去除物体。在这里,目标区域中的像素填充顺序由像素邻域的“纹理”级别决定。虽然想法是合理的,但强线性结构常常被附近的噪声所干扰,从而使额外计算的值最小化。相关技术通过目标区域的局部形状来确定填充顺序,但并未寻求明确扩散的线性结构[6]。
Finally, Zalesny et al. [23] describe an interesting algorithm for the parallel synthesis of composite textures. They devise a special-purpose solution for the interface between two textures. In this paper we show that, in fact, only one mechanism is sufficient for the synthesis of both pure and composite textures.
Section 2 presents the key observation on which our algorithm depends. Section 3 describes the details of the algorithm.
Results on both synthetic and real imagery are presented in section 4.
最后,Zalesny等人[23]描述了一种有趣的复合纹理并行合成算法。他们为两种纹理之间的界面设计了一种特殊目的的解决方案。在本文中,我们证明,事实上,只有一种机制就足以合成纯纹理和复合纹理。
第2节介绍了我们的算法所依赖的关键实验观察。第3节描述了算法的细节,第4节给出了合成图像和真实图像的结果。
2. Exemplar-based synthesis suffices
The core of our algorithm is an isophote-driven imagesampling process. It is well-understood that exemplarbased approaches perform well for two-dimensional textures [1, 9, 15]. But, we note in addition that exemplarbased texture synthesis is sufficient for propagating extended linear image structures, as well. A separate synthesis mechanism is not required for handling isophotes.
2.基于样例的合成
我们算法的核心是一个等压线驱动的图像采样过程。众所周知,基于示例的方法在二维纹理方面表现良好[1,9,15]。但是,我们还注意到,基于示例的纹理合成对于扩展线性图像结构的传播也是足够的。因此,处理等压线并不需要单独的合成机制。
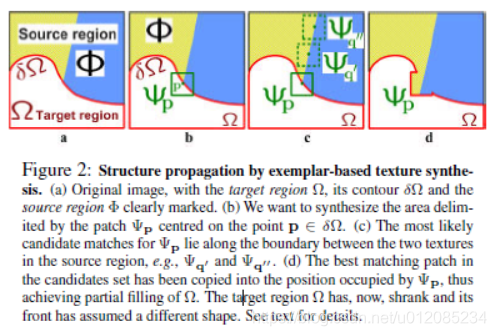
Figure 2 illustrates this point. For ease of comparison, we adopt notation similar to that used in the inpainting literature. The region to be filled, i.e., the target region is indicated by Ω, and its contour is denoted δΩ. The contour evolves inward as the algorithm progresses, and so we also refer to it as the “fill front”. The source region, Φ, which remains fixed throughout the algorithm, provides samples used in the filling process.
We now focus on a single iteration of the algorithm to show how structure and texture are adequately handled by exemplar-based synthesis. Suppose that the square template Ψp ∈ Ω centred at the point p (fig. 2b), is to be filled. The best-match sample from the source region comes from the patch Ψq ∈ Φ, which is most similar to those parts that are already filled in Ψp. In the example in fig. 2b, we see that if Ψp lies on the continuation of an image edge, the most likely best matches will lie along the same (or a similarly coloured) edge (e.g., Ψq and Ψq in fig. 2c).
All that is required to propagate the isophote inwards is a simple transfer of the pattern from the best-match source patch (fig. 2d). Notice that isophote orientation is automatically preserved. In the figure, despite the fact that the original edge is not orthogonal to the target contour δΩ, the propagated structure has maintained the same orientation as in the source region.
图2说明了这一点。为了便于比较,我们采用了类似图像修复文献中使用的符号。要填充的区域,即目标区域用Ω表示,其轮廓用δΩ表示。轮廓随着算法的发展而向内填充,因此我们也将其称为“填充线”。源区域Φ在整个算法中保持不变,它提供填充过程中使用的样本。
现在我们将重点放在算法的某一次迭代上,以展示如何通过基于示例的合成充分处理结构和纹理。假设要填充以点P为中心的方形模板θp∈Ω(如图2b),源区的最佳匹配样本来自于Ψq∈Φ,Ψq是与Ψp已填补部分最相似的部分。在图2b中的示例中,我们发现,如果Ψp位于图像边缘的延续上,则最可能的最佳匹配将位于相同(或颜色相似)的边缘上(如图2c中的Ψq和Ψq)。
所有需要填充的等压线向内传播是通过一个简单的模式,从最佳匹配的源图像块转移到待修复的块中(图2d)。请注意,等压线方向是自动保留的。在图中,尽管原始边缘不与目标轮廓δΩ正交,但填充部分与源区域保持相同的方向。
3. Region-filling algorithm
We now proceed with the details of our algorithm.
First, a user selects a target region, Ω, to be removed and filled. The source region, Φ, may be defined as the entire image minus the target region (Φ = I−Ω), as a dilated band around the target region, or it may be manually specified by the user.
Next, as with all exemplar-based texture synthesis [10], the size of the template window Ψ must be specified. We provide a default window size of 9×9 pixels, but in practice require the user to set it to be slightly larger than the largest distinguishable texture element, or “texel”, in the source region.
3. 区域填充算法
我们现在开始详细介绍我们的算法。
首先,标记要填充的目标区域Ω。源区域Φ可以定义为整个图像减去目标区域(Φ=I−Ω),作为目标区域周围的扩展带,也可以通过手动指定。
接下来,与基于示例的纹理合成方法[10]一样,必须指定模板窗口的大小ψ。我们提供了9×9像素的默认窗口大小,但实际上需要用户将其设置为略大于源区域中最大的可分辨纹理元素(texel)。
Once these parameters are determined, the remainder of the region-filling process is completely automatic.
In our algorithm, each pixel maintains a colour value (or “empty”, if the pixel is unfilled) and a confidence value, which reflects our confidence in the pixel value, and which is frozen once a pixel has been filled. During the course of the algorithm, patches along the fill front are also given a temporary priority value, which determines the order in which they are filled. Then, our algorithm iterates the following three steps until all pixels have been filled:
3.1. Computing patch priorities.
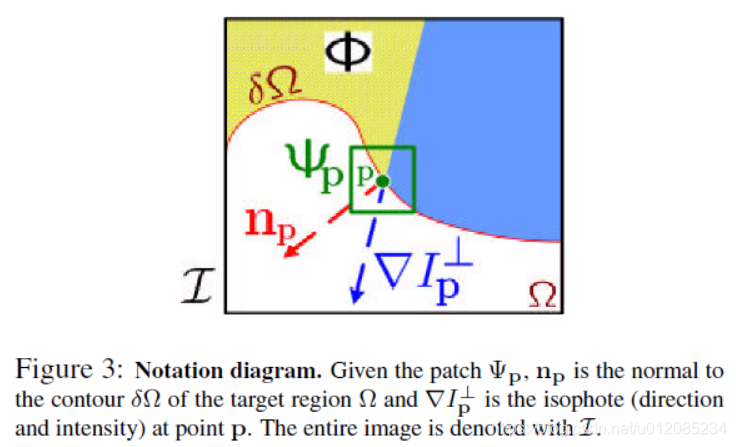
Filling order is crucial to non-parametric texture synthesis [1, 6, 10, 13]. Thus far, the default favourite has been the “onion peel” method, where the target region is synthesized from the outside inward, in concentric layers. To our knowledge, however, designing a fill order which explicitly encourages propagation of linear structure (together with texture) has never been explored. Our algorithm performs this task through a best-first filling algorithm that depends entirely on the priority values that are assigned to each patch on the fill front. The priority computation is biased toward those patches which are on the continuation of strong edges and which are surrounded by high-confidence pixels. Given a patch Ψp centred at the point p for some p ∈ δΩ (see fig. 3), its priority P(p) is defined as the product of two terms:
一旦确定了这些参数,区域填充过程的其余部分将完全自动进行。
在我们的算法中,每个像素都保持一个颜色值(如果像素未填充,则为“空”)和一个置信值,这反映了我们对像素值的信心,并且一旦像素被填充,就会被冻结。在算法的执行过程中,填充图像块的前面的块也会被赋予一个临时的优先级值,该值决定了补丁的填充顺序。然后,我们的算法重复以下三个步骤,直到所有像素都被填满:
3.1.计算修补程序优先级。
填充顺序对非参数纹理合成至关重要[1,6,10,13]。到目前为止,默认的最受欢迎的方法是“洋葱皮”法,即目标区域是从外部向内,在同心层中合成的。然而,据我们所知,一个明确的鼓励线性结构(结合纹理因素)传播的填充顺序从未被探索过。我们的算法通过最佳优先的填充算法来执行这项任务,该算法完全依赖于分配给填充前面的每个补丁的优先级值。优先级的计算偏向于那些在明显边界的延续上和被高置信像素包围的补丁。给定一个以点p为中心的图像块,对于一些p∈δΩ(见图3),其优先级P(p)定义为两个术语的乘积:
![]()
We call C(p) the confidence term and D(p) the data term, and they are defined as follows:
我们称C(p)为置信项,D(p)为数据项,定义如下:

where |Ψp| is the area of Ψp, α is a normalization factor (e.g., α = 255 for a typical grey-level image), and np is a unit vector orthogonal to the front δΩ in the point p. The priority is computed for every border patch, with distinct patches for each pixel on the boundary of the target region.
式中,|Ψp|是Ψp的面积,α是归一化因子(例如,对于典型的灰度图像而言,α=255),np是在点p上与前面的δΩ正交的单位向量。为每个边界图像块计算优先级,目标区域边界上的每个像素都有不同的图像块。
During initialization, the function C(p) is set to C(p) = 0 ∀p ∈ Ω, and C(p) = 1 ∀p ∈ I −Ω. The confidence term C(p) may be thought of as a measure of the amount of reliable information surrounding the pixel p.
对于C(p)的初始化,函数C(p)设为0时, ∀p∈Ω,C(p)设为1时,∀p∈I−Ω。置信项C(p)可以被认为是围绕像素p的可靠信息量的度量。
The intention is to fill first those patches which have more of their pixels already filled, with additional preference given to pixels that were filled early on (or that were never part of the target region).
其目的是首先填充那些已经填充了更多像素的补丁,并对早期填充的像素(或不属于目标区域的像素)进行了额外的偏好设置。
This automatically incorporates preference towards certain shapes along the fill front. For example, patches that include corners and thin tendrils of the target region will tend to be filled first, as they are surrounded by more pixels from the original image. These patches provide more reliable information against which to match. Conversely, patches at the tip of “peninsulas” of filled pixels jutting into the target region will tend to be set aside until more of the surrounding pixels are filled in.
这些自动合并倾向于先合并某些形状或者是填充边缘。例如,那些包含角或者细小纹理的目标区域块往往首先被填充,因为它们被原始图像中的更多像素包围(?)。这些块提供了更可靠的匹配信息。相反,突出到目标区域的待填充“半岛”尖端的块将倾向于被留出,直到填充完更多的周围像素后再填充。
At a coarse level, the term C(p) of (1) approximately enforces the desirable concentric fill order. As filling proceeds, pixels in the outer layers of the target region will tend to be characterized by greater confidence values, and therefore be filled earlier; pixels in the centre of the target region will have lesser confidence values.
在粗略的水平上,第一次迭代的C(p)近似地执行所需的同心填充顺序。随着填充的进行,目标区域外层的像素将趋向于更大的置信值,因此会更早填充;目标区域中心的像素将具有更小的置信值。
The data term D(p) is a function of the strength of isophotes hitting the front δΩ at each iteration. This term boosts the priority of a patch that an isophote “flows” into. This factor is of fundamental importance in our algorithm because it encourages linear structures to be synthesized first, and, therefore propagated securely into the target region. Broken lines tend to connect, thus realizing the “Connectivity Principle” of vision psychology [7, 17] (cf., fig. 4, fig. 7d, fig. 8b and fig. 13d).
数据项D(p)是在每次迭代时计算δΩ等压线的强度的函数。这个过程提高了包括等压线块的优先级。这一因素在我们的算法中至关重要,因为它鼓励首先合成线性结构,从而安全地传播到目标区域。断线倾向于连接,从而实现视觉心理学的“连接原理”[7,17](参见图4,图7d,图8b和图13d)。
There is a delicate balance between the confidence and data terms. The data term tends to push isophotes rapidly inward, while the confidence term tends to suppress precisely this sort of incursion into the target region. As presented in the results section, this balance is handled gracefully via the mechanism of a single priority computation for all patches on the fill front.
置信值和数据项之间存在微妙的平衡。数据项倾向于迅速地向内推送等压线,而置信项倾向于精确地抑制这种侵入目标区域的行为。如结果部分所示,通过对填充区域上所有图像块的单个优先级计算机制,可以很好地处理此平衡。
Since the fill order of the target region is dictated solely by the priority function P(p), we avoid having to predefine an arbitrary fill order as done in existing patch-based approaches [9, 19]. Our fill order is function of image properties, resulting in an organic synthesis process that eliminates the risk of “broken-structure” artefacts (fig. 7c) and also reduces blocky artefacts without an expensive patch-cutting step [9] or a blur-inducing blending step [19].
由于目标区域的填充顺序完全由优先级函数P(p)决定,因此我们避免了现有基于补丁的方法中预先定义任意填充顺序的缺陷[9,19]。我们的填充顺序是通过图像优先级的函数得到的,从而产生一个有组织的合成过程,消除了“结构破坏”的风险(图7c),并且还在没有块切割步骤[9]或模糊步骤[19]的情况下,减少了块效应。

3.2. Propagating texture and structure information.
Once all priorities on the fill front have been computed, the patch Ψp^ with highest priority is found. We then fill it with data extracted from the source region Φ.
In traditional inpainting techniques, pixel-value information is propagated via diffusion. As noted previously, diffusion necessarily leads to image smoothing, which results in blurry fill-in, especially of large regions (see fig. 10f).
On the contrary, we propagate image texture by direct sampling of the source region. Similar to [10], we search in the source region for that patch which is most similar to Ψp^. Formally,
3.2.传播纹理和结构信息。
计算完填充面上的所有优先级后,即可找到优先级最高的补丁Ψp^。然后我们用从源区域Φ提取的数据填充它。
在传统的着色技术中,像素值信息是通过扩散传播的。如前所述,扩散必然导致图像平滑,从而导致填充模糊,尤其是大区域(见图10f)。
相反,我们通过直接采样源区域来传播图像纹理。与[10]类似,我们在源区域中搜索最类似于Ψp^.的补丁,
![]()
where the distance d(Ψa,Ψb) between two generic patches Ψa and Ψb is simply defined as the sum of squared differences (SSD) of the already filled pixels in the two patches. We use the CIE Lab colour space because of its property of perceptual uniformity [18].
Having found the source exemplar Ψˆq, the value of each pixel-to-be-filled, p |p ∈ Ψˆp∩Ω, is copied from its corresponding position inside Ψˆq.
This suffices to achieve the propagation of both structure and texture information from the source Φ to the target region Ω, one patch at a time (cf., fig. 2d). In fact, we note that any further manipulation of the pixel values (e.g., adding noise, smoothing and so forth) that does not explicitly depend upon statistics of the source region, is far more likely to degrade visual similarity between the filled region and the source region, than to improve it.
其中,两个普通面片之间的距离d(ψa,ψb)定义为两个面片中已填充像素的平方差(ssd)之和。我们使用CIE实验室颜色空间是因为它具有感知均匀性[18]。
找到源示例_q后,将从其在_q内的相应位置复制要填充的每个像素的值p p∈_pΩ。
这足以实现结构和纹理信息从源Φ到目标区域Ω的传播,一次一个图像块(参见图2d)。事实上,我们注意到,对像素值的任何进一步不显式依赖源区域的统计信息的操作(例如,添加噪声、平滑等),更可能的操作是降低填充区域和源区域之间的视觉相似性,而不是改善它。
3.3. Updating confidence values.
After the patch Ψˆp has been filled with new pixel values, the confidence C(p) is updated in the area delimited by Ψˆp as follows:
3.3.更新置信值。
补丁Ψˆp被新的像素值填充后,置信度C(p)在Ψˆp界定的区域更新如下:
![]()
This simple update rule allows us to measure the relative confidence of patches on the fill front, without imagespecific parameters. As filling proceeds, confidence values decay, indicating that we are less sure of the colour values of pixels near the centre of the target region.
这个简单的更新规则允许我们在没有图像特定参数的情况下测量填充面上补丁的相对置信度。随着填充过程的进行,置信值会衰减,这表明我们对目标区域中心附近像素的颜色值不太确定。

A pseudo-code description of the algorithmic steps is shown in table 1. The superscript t indicates the current iteration.
算法步骤的伪代码描述如表1所示。上标t表示当前迭代。
4. Results and comparisons
Here we apply our algorithm to a variety of images, ranging from purely synthetic images to full-colour photographs that include complex textures. Where possible, we make side-by-side comparisons to previously proposed methods. In other cases, we hope the reader will refer to the original source of our test images (many are taken from previous literature on inpainting and texture synthesis) and compare these results with the results of earlier work.
In all of the experiments, the patch size was set to be greater than the largest texel or the thickest structure (e.g., edges) in the source region. Furthermore, unless otherwise stated the source region has been set to be Φ = I −Ω. All experiments were run on a 2.5GHz Pentium IV with 1GB of RAM.
The Kanizsa triangle. We perform our first experiment on the well-known Kanizsa triangle [17] to show how the algorithm works on a structure-rich synthetic image.
As shown in fig. 4, our algorithm deforms the fill front δΩ under the action of two forces: isophote continuation (the data term, D(p)) and the “pressure” from surrounding filled pixels (the confidence term, C(p)).
4.结果和比较
在这里,我们将我们的算法应用于各种图像,从纯合成图像到包含复杂纹理的全彩照片。在可能的情况下,我们将与先前提出的方法进行比较。在其他情况下,我们希望读者参考我们测试图像的原始来源(许多是从以前的关于图像修复和纹理合成的文献中获取的),并将这些结果与早期工作的结果进行比较。
在所有的实验中,图像块大小被设置为大于源区域中最大的纹理元素或最厚的结构(例如边缘)。此外,除非另有说明,否则源区设置为Φ=I−Ω。所有的实验都是在一个2.5GHz的Pentium IV上运行的,内存为1GB。
Kanizza三角。我们对著名的Kanizza三角形[17]进行了第一次实验,以展示该算法如何在结构丰富的合成图像上工作。
如图4所示,我们的算法在两种函数的作用下使填充前δΩ变形:等压线连续(数据项D(p))和周围填充像素的“压力”(置信项C(p))。

The sharp linear structures of the incomplete green triangle are grown into the target region. But also, no single structural element dominates all of the others; this balance among competing isophotes is achieved through the naturally decaying confidence values (in an earlier version of our algorithm which lacked this balance, “runaway” structures led to large-scale artefacts.)
Figures 4e,f also show the effect of the confidence term in smoothing sharp appendices such as the vertices of the target region (in red).
As described above, the confidence is propagated in a manner similar to the front-propagation algorithms used in inpainting. We stress, however, that unlike inpainting, it is the confidence values that are propagated along the front (and which determine fill order), not colour values themselves, which are sampled from the source region.
Finally, we note that despite the large size of the removed region, edges and lines in the filled region are as sharp as any found in the source region. There is no blurring from diffusion processes. This is a property of exemplar-based texture synthesis.
将不完全绿色三角形的尖锐线性结构扩展到目标区域。但是,没有一个单一的结构元素支配所有其他元素;这种在竞争的等压线之间的平衡是通过自然衰减的置信值实现的(在缺乏这种平衡的早期版本中,“失控”结构导致了大规模的人工制品)。
图4e,f还显示了置信值对平滑尖锐部分(如目标区域顶点)的影响(红色)。
如上所述,置信度的传播方式类似于修复中使用的前传播算法。然而,我们强调,与图像修复方法不同的是,置信值是沿着前面传播的(并决定填充顺序),而不是颜色值本身,它们是从源区域取样的。
最后,我们注意到,尽管移除区域的大小很大,填充区域中的边和线与源区域中的任何边和线一样锋利。扩散过程没有模糊。这是基于范例的纹理合成的一个特性。
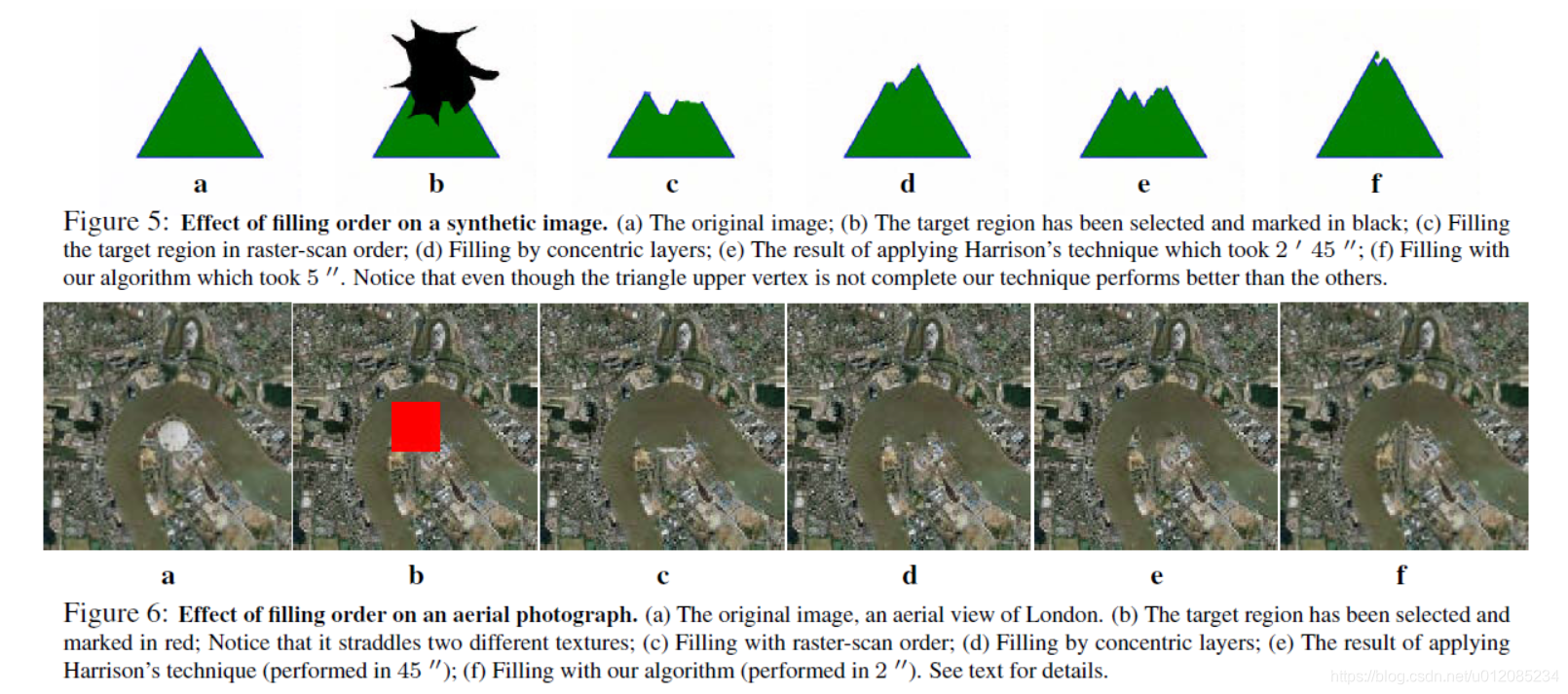
The effect of different filling strategies. Figures 5, 6 and 7 demonstrate the effect of different filling strategies.
Figure 5f shows how our filling algorithm achieves the best structural continuation in a simple, synthetic image.
Figure 6 further demonstrates the validity of our algorithm on an aerial photograph. The 40 × 40-pixel target region has been selected to straddle two different textures (fig. 6b). The remainder of the 200 × 200 image in fig. 6a was used as source for all the experiments in fig. 6.
With raster-scan synthesis (fig. 6c) not only does the top region (the river) grow into the bottom one (the city area), but visible seams also appear at the bottom of the target region. This problem is only partially addressed by a concentric filling (fig 6d). Similarly, in fig. 6e the sophisticated ordering proposed by Harrison [13] only moderately succeeds in preventing this phenomenon.
In all of these cases, the primary difficulty is that since the (eventual) texture boundary is the most constrained part of the target region, it should be filled first. But, unless this is explicitly addressed in determining the fill order, the texture boundary is often the last part to be filled. The algorithm proposed in this paper is designed to address this problem, and thus more naturally extends the contour between the two textures as well as the vertical grey road.
不同填充策略的效果。图5、6和7展示了不同填充策略的效果。
图5f显示了我们的填充算法如何在简单的合成图像中实现最佳的结构延续。
图6进一步证明了我们的算法在航空照片上的有效性。选择40×40像素的目标区域跨越两种不同的纹理(图6b)。图6a中200×200图像的其余部分用作图6中所有实验的源区域。
通过光栅扫描合成(图6c),不仅顶部区域(河流)生长到底部区域(城市区域),而且目标区域底部也会出现可见接缝。这一问题只能通过同心填补来部分解决(图6d)。同样,在图6e中,Harrison[13]提出的复杂排序仅在一定程度上成功地防止了这种现象。
在所有这些情况下,主要的困难是,由于(最终)纹理边界是目标区域中最受约束的部分,所以应该首先填充它。但是,除非在确定填充顺序时明确说明这一点,否则纹理边界通常是要填充的最后一部分。本文提出的算法是针对这一问题而设计的,从而更自然地扩展了两种纹理之间的轮廓以及垂直的灰色道路。
In the example in fig. 6, our algorithm fills the target region in only 2 seconds, on a Pentium IV, 2.52GHz, 1GB RAM. Harrison’s resynthesizer [13], which is the nearest in quality, requires approximately 45 seconds.
Figure 7 shows yet another comparison between the concentric filling strategy and the proposed algorithm. In the presence of concave target regions, the “onion peel” filling may lead to visible artefacts such as unrealistically broken structures (see the pole in fig. 7c). Conversely, the presence of the data term of (1) encourages the edges of the pole to grow “first” inside the target region and thus correctly reconstruct the complete pole (fig. 7d). This example demonstrates the robustness of the proposed algorithm with respect to the shape of the selected target region.
Comparisons with inpainting. We now turn to some examples from the inpainting literature. The first two examples show that our approach works at least as well as inpainting.
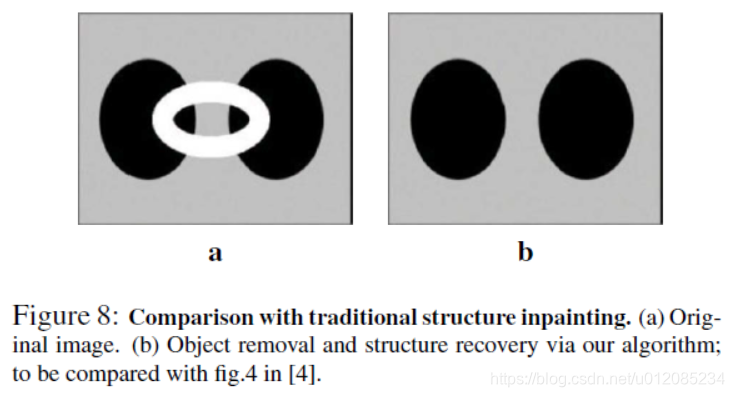
The first (fig. 8) is a synthesized image of two ellipses [4]. The occluding white torus is removed from the input image and two dark background ellipses reconstructed via our algorithm (fig. 8b). This example was chosen by authors of the original work on inpainting to illustrate the structure propagation capabilities of their algorithm. Our results are visually identical to those obtained by inpainting ([4], fig.4).
We now compare results of the restoration of an handdrawn image. In fig. 9 the aim is to remove the foreground text. Our results (fig. 9b) are mostly indistinguishable with those obtained by traditional inpainting 3. This example demonstrates the effectiveness of both techniques in image restoration applications.
It is in real photographs with large objects to remove, however, that the real advantages of our approach become apparent. Figure 10 shows an example on a real photograph, of a bungee jumper in mid-jump (from [4], fig.8). In the original work, the thin bungee cord is removed from the image via inpainting. In order to prove the capabilities of our algorithm we removed the entire bungee jumper (fig. 10e). Structures such as the shore line and the edge of the house have been automatically propagated into the target region along with plausible textures of shrubbery, water and roof tiles; and all this with no a priori model of anything specific to this image.
在图6中的示例中,我们的算法在Pentium IV,2.52GHz、1GB RAM上,只需2秒钟就可以填充目标区域。哈里森的再合成器[13]的质量最接近,大约需要45秒。
图7显示了同心填充策略和对比算法之间的另一个比较。在存在凹面目标区域的情况下,“洋葱皮”填充物可能导致可见的假象,例如不真实的断裂结构(见图7c中的杆)。相反,第一次迭代(?)的数据项的存在鼓励极点的边缘向目标区域内生长,从而正确地重建整个极点(图7d)。这个例子说明了所提出的算法对所选目标区域形状的鲁棒性。
与图像修复比较。现在,我们来看一些来自于图像修复文献的例子。前两个例子表明,我们的方法至少能起到修复的作用。
第一个(图8)是两个椭圆的合成图像[4]。通过我们的算法(图8b),从输入图像中去除阻塞的白色圆环,重建两个暗背景椭圆。这个例子是由最初的图像修复工作的作者选择的,以说明他们的算法的结构传播能力。我们的结果在视觉上与通过图像修复获得的结果相同([4],图4)。
我们现在比较了手工绘制图像的恢复结果。图9的目的是删除前景文本。我们的结果(图9b)与传统的图像修复算法所得的结果几乎不可区分。这个例子演示了这两种技术在图像恢复应用中的有效性。
然而,在大量物体的真实照片中证实,我们的方法的真正优势变得显而易见。图10显示了一张真实照片上的例子,一个蹦极运动员在跳中(从[4],图8)。在最初的作品中,薄的橡皮筋绳通过内涂从图像中去除。为了证明我们的算法的能力,我们移除了整个蹦极跳线(图10e)。诸如海岸线和房屋边缘等结构已经自动传播到目标区域,以及灌木、水和屋顶瓷砖的合理纹理;所有这一切都没有针对这幅图像的先验模型。

For comparison, figure 10f shows the result of filling the same target region (fig. 10b) by image inpainting. Considerable blur is introduced into the target region because of inpainting’s use of diffusion to propagate colour values; and high-frequency textural information is entirely absent.
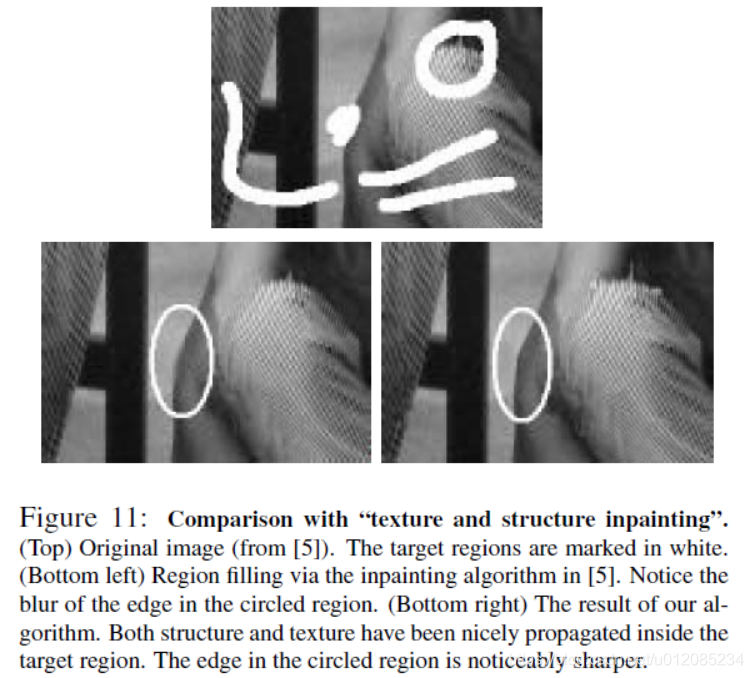
Figure 11 compares our algorithm to the recent “texture and structure inpainting” technique described in [5]. Figure 11(bottom right) shows that also our algorithm accomplishes the propagation of structure and texture inside the selected target region. Moreover, the lack of diffusion steps avoids blurring propagated structures (see the vertical edge in the encircled region) and makes the algorithm more computationally efficient.
Synthesizing composite textures. Fig. 12 demonstrates that our algorithm behaves well also at the boundary between two different textures, such as the ones analyzed in [23]. The target region selected in fig. 12c straddles two different textures. The quality of the “knitting” in the contour reconstructed via our approach (fig. 12d) is similar to the original image and to the results obtained in the original work (fig. 12b), but again, this has been accomplished without complicated texture models or a separate boundaryspecific texture synthesis algorithm.
Further examples on photographs. We show two more examples on photographs of real scenes.
Figure 13 demonstrates, again, the advantage of the proposed approach in preventing structural artefacts (cf., 7d). While the onion-peel approach produces a deformed horizon, our algorithm reconstructs the boundary between sky and sea as a convincing straight line.
Finally, in fig. 14, the foreground person has been manually selected and the corresponding region filled in automatically. The filled region in the output image convincingly mimics the complex background texture with no prominent artefacts (fig. 14f). During the filling process the topological changes of the target region are handled effortlessly.
为了进行比较,图10f显示了通过图像修复填充相同目标区域(图10b)的结果。由于图像修复使用扩散来传播颜色值,因此在目标区域引入了相当大的模糊;并且完全没有高频纹理信息。
图11将我们的算法与[5]中描述的最新“纹理和结构修复”技术进行了比较。图11(右下角)显示,我们的算法还可以在选定的目标区域内完成结构和纹理的传播。此外,由于缺乏扩散步骤,避免了传播结构的模糊(参见环绕区域的垂直边缘),使算法的计算效率更高。
合成复合纹理。图12表明,我们的算法在两种不同纹理之间的边界也表现良好,如[23]中分析的纹理。图12c中选择的目标区域跨越两种不同的纹理。通过我们的方法重建的轮廓中的“编织”质量(图12d)与原始图像和原始工作中(图12b)相似,但同样,这是在没有复杂的纹理模型或单独的边界特定纹理合成算法的情况下完成的。
关于照片的更多例子。我们在真实场景的照片上再展示两个例子。
图13再次证明了建议的方法在防止结构人工制品方面的优势(参见,7d)。当洋葱皮方法产生一个变形的地平线时,我们的算法将天空和海洋之间的边界重建为一条令人信服的直线。
最后,在图14中,手动选择了前景人物,并自动填写相应的区域。输出图像中的填充区域令人信服地模仿了复杂的背景纹理,没有突出的人工痕迹(图14f)。在填充过程中,对目标区域的拓扑变化进行了简单的处理。

5. Conclusion and future work
This paper has presented a novel algorithm for removing large objects from digital photographs. The result of object removal is an image in which the selected object has been replaced by a visually plausible background that mimics the appearance of the source region.
Our approach employs an exemplar-based texture synthesis technique modulated by a unified scheme for determining the fill order of the target region. Pixels maintain a confidence value, which together with image isophotes, influence their fill priority.
The technique is capable of propagating both linear structure and two-dimensional texture into the target region. Comparative experiments show that a careful selection of the fill order is necessary and sufficient to handle this task.
Our method performs at least as well as previous techniques designed for the restoration of small scratches, and in instances in which larger objects are removed, it dramatically outperforms earlier work in terms of both perceptual quality and computational efficiency.
Currently, we are investigating extensions for more accurate propagation of curved structures in still photographs and for object removal from video, which promise to impose an entirely new set of challenges.
5. 总结和后续工作
本文提出了一种从数字图像中去除大物体的新算法。去除遮挡物的结果是得到一个图像,该图像中所选物体已被一个视觉上可信的背景所替换。
我们的方法采用了一种基于范例的纹理合成技术,并通过统一的方案来确定目标区域的填充顺序。像素的置信值与图像等焦线一起影响其填充的优先级。
该技术能够将线性结构和二维纹理传播到目标区域。对比实验表明,对填充顺序进行仔细的选择是处理这一任务的必要和充分的。
我们的方法在修复小划痕上和以前设计的技术一样;在移除较大物体的情况下,在感知质量和计算效率方面,它明显优于早期的工作。
目前,我们正在研究在静止照片中更精确地传播曲线结构以及从视频中去除物体的扩展,这将带来一系列全新的挑战。



参考文献
[1] M. Ashikhmin. Synthesizing natural textures. In Proc. ACM Symp. on Interactive 3D Graphics, pp. 217–226, Research Triangle Park, NC, Mar 2001.
[2] C. Ballester, V. Caselles, J. Verdera, M. Bertalmio, and G. Sapiro. A variational model for filling-in gray level and color images. In Proc. ICCV, pp. I: 10–16, Vancouver, Canada, Jun 2001.
[3] M. Bertalmio, A.L. Bertozzi, and G. Sapiro. Navier-stokes, fluid dynamics, and image and video inpainting. In Proc. Conf. Comp. Vision Pattern Rec., pp. I:355–362, Hawai, Dec 2001.
[4] M. Bertalmio, G. Sapiro, V. Caselles, and C. Ballester. Image inpainting. In Proc. ACM Conf. Comp. Graphics
(SIGGRAPH), pp. 417–424, New Orleans, LU, Jul 2000. http://mountains.ece.umn.edu/∼guille/inpainting.htm.
[5] M. Bertalmio, L. Vese, G. Sapiro, and S. Osher. Simultaneous structure and texture image inpainting. to appear,
2002. http://mountains.ece.umn.edu/∼guille/inpainting.htm.
[6] R. Bornard, E. Lecan, L. Laborelli, and J-H. Chenot. Missing data correction in still images and image sequences. In ACMMultimedia, France, Dec 2002.
[7] T. F. Chan and J. Shen. Non-texture inpainting by curvature-driven diffusions (CDD). J. Visual Comm. Image Rep., 4(12), 2001.
[8] J.S. de Bonet. Multiresolution sampling procedure for analysis and synthesis of texture images. In Proc. ACM Conf. Comp. Graphics (SIGGRAPH), volume 31, pp. 361–368, 1997.
[9] A. Efros and W.T. Freeman. Image quilting for texture synthesis and transfer. In Proc. ACM Conf. Comp. Graphics (SIGGRAPH), pp. 341–346, Eugene Fiume, Aug 2001.
[10] A. Efros and T. Leung. Texture synthesis by non-parametric sampling. In Proc. ICCV, pp. 1033–1038, Kerkyra, Greece, Sep 1999.
[11] W.T. Freeman, E.C. Pasztor, and O.T. Carmichael. Learning lowlevel vision. Int. J. Computer Vision, 40(1):25–47, 2000.
[12] D. Garber. Computational Models for Texture Analysis and Texture Synthesis. PhD thesis, Univ. of Southern California, USA, 1981.
[13] P. Harrison. A non-hierarchical procedure for re-synthesis of complex texture. In Proc. Int. Conf. Central Europe Comp. Graphics, Visua. and Comp. Vision, Plzen, Czech Republic, Feb 2001.
[14] D.J. Heeger and J.R. Bergen. Pyramid-based texture analysis/synthesis. In Proc. ACM Conf. Comp. Graphics (SIGGRAPH), volume 29, pp. 229–233, Los Angeles, CA, 1995.
[15] A. Hertzmann, C. Jacobs, N. Oliver, B. Curless, and D. Salesin. Image analogies. In Proc. ACM Conf. Comp. Graphics (SIGGRAPH), Eugene Fiume, Aug 2001.
[16] H. Igehy and L. Pereira. Image replacement through texture synthesis. In Proc. Int. Conf. Image Processing, pp. III:186–190, 1997.
[17] G. Kanizsa. Organization in Vision. Praeger, New York, 1979.
[18] J. M. Kasson and W. Plouffe. An analysis of selected computer interchange color spaces. In ACM Transactions on Graphics, volume 11, pp. 373–405, Oct 1992.
[19] L. Liang, C. Liu, Y.-Q. Xu, B. Guo, and H.-Y. Shum. Real-time texture synthesis by patch-based sampling. In ACM Transactions on Graphics, 2001.
[20] S. Masnou and J.-M. Morel. Level lines based disocclusion. In Int. Conf. Image Processing, Chicago, 1998.
[21] S. Rane, G. Sapiro, and M. Bertalmio. Structure and texture fillingin of missing image blocks in wireless transmission and compression applications. In IEEE. Trans. Image Processing, 2002. to appear.
[22] L.-W. Wey and M. Levoy. Fast texture synthesis using treestructured vector quantization. In Proc. ACMConf. Comp. Graphics (SIGGRAPH), 2000.
[23] A. Zalesny, V. Ferrari, G. Caenen, and L. van Gool. Parallel composite texture synthesis. In Texture 2002 workshop - (in conjunction with ECCV02), Copenhagen, Denmark, Jun 2002.

















 7617
7617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









