







新特性
- 动态分区剪裁(Dynamic Partition Pruning)
- ⾃适应查询执⾏(Adaptive Query Execution)
- 加速器感知调度(Accelerator-aware Scheduling)
- ⽀持 Catalog 的数据源API(Data Source API with Catalog Supports)
- SparkR 中的向量化(Vectorization in SparkR)
- ⽀持Hadoop 3/JDK 11/Scala 2.12 等等。
AQE(Adaptive Query Execution,⾃适应查询执⾏)
AQE是Spark SQL的⼀种动态优化机制,是对查询执⾏计划的优化。
我们可以设置参数 spark.sql.adaptive.enabled 为true来开启AQE,在Spark 3.0中默认是
false。
在运⾏时,AQE会结合Shuffle Map阶段执⾏完毕后的统计信息,基于既定的规则动态地调
整、修正尚未执⾏的逻辑计划和物理计划,来完成对原始查询语句的运⾏时优化。
在介绍AQE之前我们先讲解两个优化策略:
- RBO(Rule Based Optimization,基于规则的优化)。它往往基于⼀些规则和策略实现,如
谓词下推、列剪枝,这些规则和策略来源于数据库领域已有的应⽤经验。也就是说,启
发式的优化实际上算是⼀种「经验主义」。 - CBO(Cost Based Optimization,基于成本的优化)。CBO是⼀种基于数据统计信息例如数
据量、数据分布来选择代价最⼩的优化策略的⽅式。
RBO相对于CBO⽽⾔要成熟得多,常⽤的规则都基于经验制定,可以覆盖⼤部分查询场景,
并且⽅便扩展。其缺点则是不够灵活,对待相似的问题和场景都使⽤同⼀类解决⽅案,忽略
了数据本身的信息。
Spark在2.2版本中推出了CBO,主要就是为了解决RBO 「经验主义」 的弊端。
AQE的三⼤特性包括: Join策略调整 、 分区⾃动合并 、 ⾃动倾斜处理 。
Join策略调整

Spark ⽀持的许多 Join 策略中,Broadcast Hash Join通常是性能最好的,前提是参加 join 的
⼀张表的数据能够装⼊内存。由于这个原因,当 Spark 估计参加 join 的表数据量⼩于⼴播⼤
⼩的阈值时,其会将 Join 策略调整为 Broadcast Hash Join。但是,很多情况都可能导致这种
⼤⼩估计出错——例如存在⼀个⾮常有选择性的过滤器。
由于AQE可以精确的统计上游数据,因此可以解决该问题。⽐如下⾯这个例⼦,右表的实际
⼤⼩为15M,⽽在该场景下,经过filter过滤后,实际参与join的数据⼤⼩为8M,⼩于了默认
broadcast阈值10M,应该被⼴播。
在我们执⾏过程中转化为Broadcast Hash Join的同时,我们甚⾄可以将传统shuffle优化为本地shuffle(例如shuffle读在mapper⽽不是基于reducer)来减⼩⽹络开销。
分区⾃动合并
在我们处理的数据量级⾮常⼤时,shuffle通常来说是最影响性能的。因为shuffle是⼀个⾮常
耗时的算⼦,它需要通过⽹络移动数据,分发给下游算⼦。
在shuffle中,partition的数量⼗分关键。partition的最佳数量取决于数据,⽽数据⼤⼩在不同
的query不同stage都会有很⼤的差异,所以很难去确定⼀个具体的数⽬。
在这部分,有两个⾮常重要的参数⽤来控制⽬标分区的⼤⼩:
- spark.sql.adaptive.advisoryPartitionSizeInBytes ,分区合并后的推荐尺⼨
- spark.sql.adaptive.coalescePartitions.minPartitionNum ,分区合并后最⼩分区
数
为了解决该问题,我们在最开始设置相对较⼤的shuffle partition个数,通过执⾏过程中
shuffle⽂件的数据来合并相邻的⼩partitions。 例如,假设我们执⾏ SELECT max(i) FROM t
able GROUP BY j ,表table只有2个partition并且数据量⾮常⼩。我们将初始shuffle partition
设为5,因此在分组后会出现5个partitions。若不进⾏AQE优化,会产⽣5个tasks来做聚合结
果,事实上有3个partitions数据量是⾮常⼩的
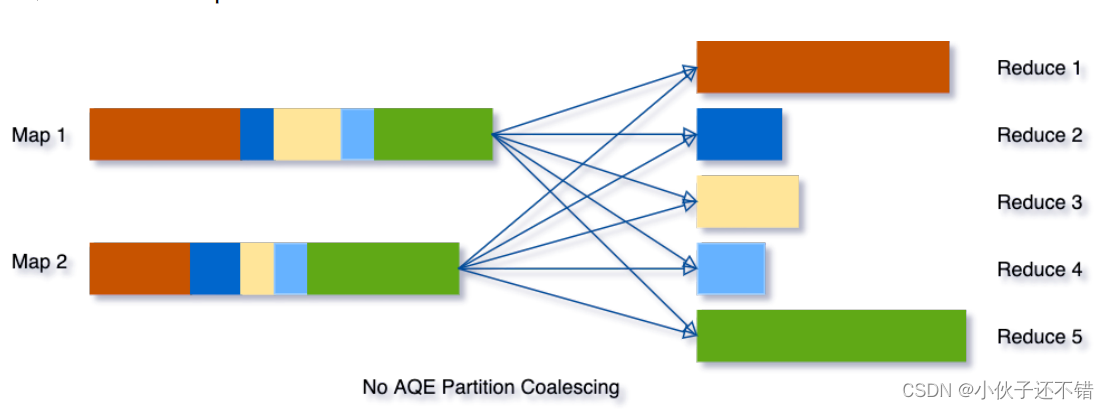
这种情况下,AQE⽣效后只会⽣成3个reduce task。

⾃动倾斜处理
Spark Join操作如果出现某个key的数据倾斜问题,那么基本上就是这个任务的性能杀⼿了。
在AQE之前,⽤户没法⾃动处理Join中遇到的这个棘⼿问题,需要借助外部⼿动收集数据统
计信息,并做额外的加盐,分批处理数据等相对繁琐的⽅法来应对数据倾斜问题。
AQE根据shuffle⽂件统计数据⾃动检测倾斜数据,将那些倾斜的分区打散成⼩的⼦分区,然
后各⾃进⾏join。
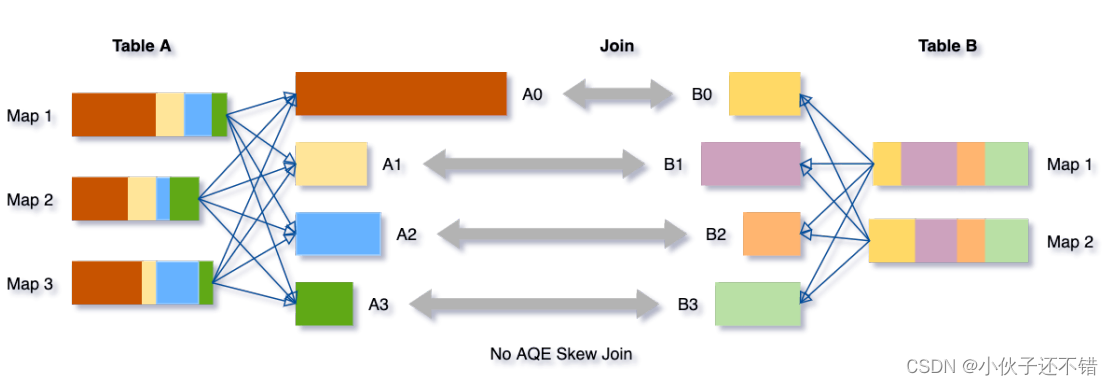
我们可以看下这个场景,Table A join Table B,其中Table A的partition A0数据远⼤于其他分
区。
AQE会将partition A0切分成2个⼦分区,并且让他们独⾃和Table B的partition B0进⾏join。
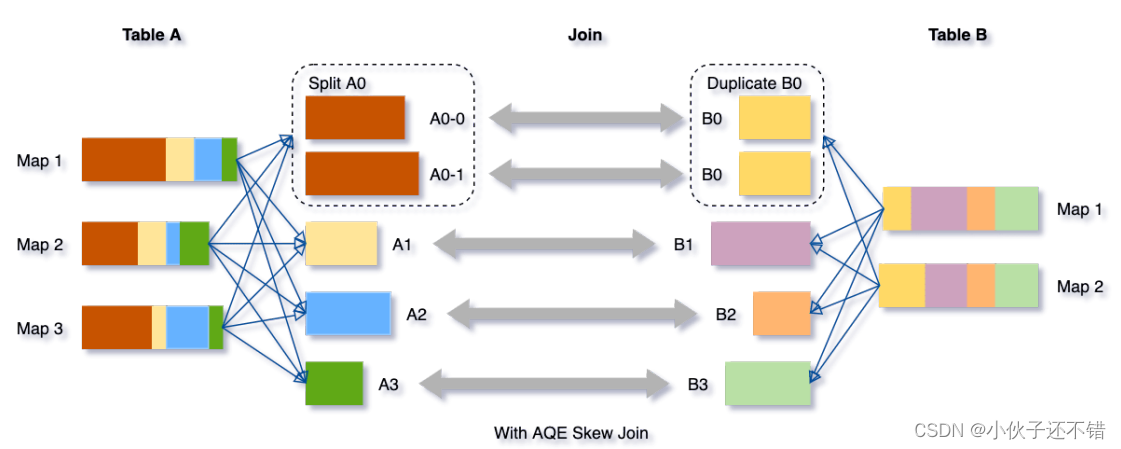
如果不做这个优化,SMJ将会产⽣4个tasks并且其中⼀个执⾏时间远⼤于其他。经优化,这个
join将会有5个tasks,但每个task执⾏耗时差不多相同,因此个整个查询带来了更好的性能。
关于如何定位这些倾斜的分区,主要靠下⾯三个参数:
- spark.sql.adaptive.skewJoin.skewedPartitionFactor ,判定倾斜的倾斜因⼦
- spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes ,判定倾斜的最
低阈值 - spark.sql.adaptive.advisoryPartitionSizeInBytes ,倾斜数据分区拆分,⼩数据分
区合并优化时,建议的分区⼤⼩(以字节为单位)
DPP(Dynamic Partition Pruning,动态分区剪裁)
所谓的动态分区裁剪就是基于运⾏时(run time)推断出来的信息来进⼀步进⾏分区裁剪,
从⽽减少事实表中数据的扫描量、降低 I/O 开销,提升执⾏性能。
我们在进⾏事实表和维度表的Join过程中,把事实表中的⽆效数据进⾏过滤,例如:
SELECT * FROM dim
JOIN fact
ON (dim.col = fact.col)
WHERE dim.col = ‘dummy’
当SQL满⾜DPP的要求后,会根据关联关系 dim.col = fact.col ,通过维度表的列传导到事
实表的col字段,只扫描事实表中满⾜条件的部分数据,就可以做到减少数据扫描量,提升
I/O效率。
但是使⽤DPP的前提条件⽐较苛刻,需要满⾜以下条件:
- 事实表必须是分区表
- 只⽀持等值Join
- 维度表过滤之后的数据必须⼩于⼴播阈值: spark.sql.autoBroadcastJoinThreshold
以上就是Spark3.0中最重要的两个特性 AQE 和 DPP 了。















 483
483











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









