







BeautifulSoup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,BeautifulSoup就不能自动识别编码方式。这时,你只需要说明一下原始编码方式就ok。参数用lxml就可以,需要另行安装并载入。BeautifulSoup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
爬取一网站多个网页数据:
from bs4 import BeautifulSoup
import requests
import lxml
import time
url='https://www.tripadvisor.cn/Attractions-g60763-Activities-New_York_City_New_York.html'
urls = ['https://www.tripadvisor.cn/Attractions-g60763-Activities-oa{}-New_York_City_New_York.html#ATTRACTION_LIST'.format(str(i)) for i in range(30,1110,30)]
def get_attractions(url):
web_data = requests.get(url)
time.sleep(2)
soup = BeautifulSoup(web_data.text,'lxml')
imgs = soup.select('img[width="180"]')
titles = soup.select('#ATTR_ENTRY_ > div.attraction_clarity_cell > div > div > div.listing_info > div.listing_title > a')
scores = soup.select('#ATTR_ENTRY_ > div.attraction_clarity_cell > div > div > div.listing_info > div.listing_rating > div > div > span[alt]')
comments = soup.select('#ATTR_ENTRY_ > div.attraction_clarity_cell > div > div > div.listing_info > div.listing_rating > div > div > span.more > a')
cates = soup.select('div.p13n_reasoning_v2')
for img,title,score,comment,cate in zip(imgs,titles,scores,comments,cates):
data = {
'img':img.get('src'),
'title':title.get_text(),
'score':score.get('alt'),
'comment':comment.get_text(),
'cate':list(cate.stripped_strings)
}
print(data)
for single_url in urls:
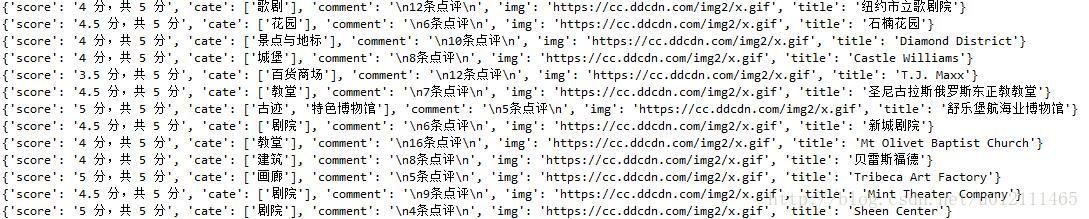
get_attractions(single_url)爬取数据如下














 3425
3425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









