






一、缓存的来源
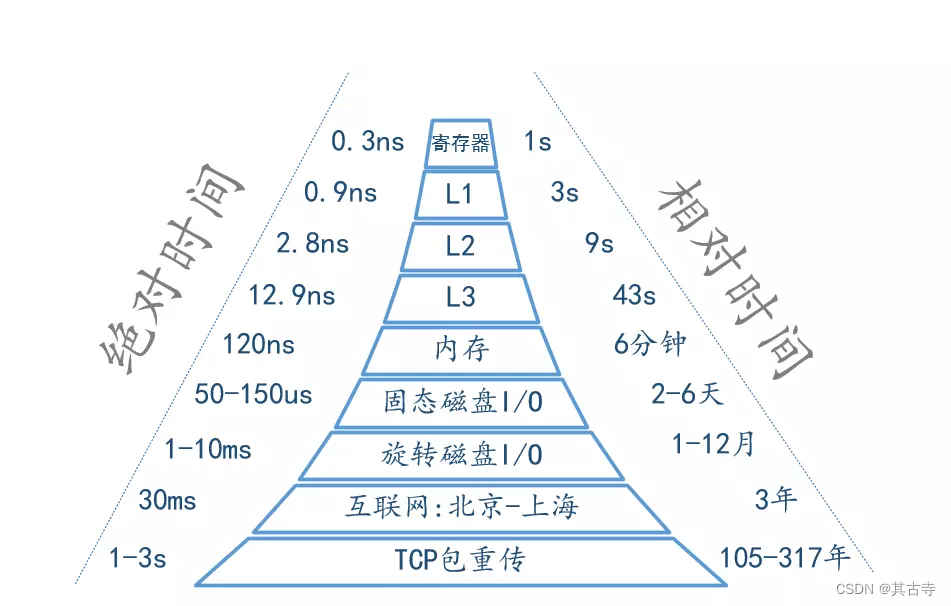
首先我们要知道缓存的来源,计算机相关专业毕业的同学,应该都学习过一门课程。那就是,我就是从那时候开始接触到缓存这个概念的。 从右图中我们可以看到不同的介质在传输数据上速度是有非常大区别。既然有更高速度的方案,为什么不能全部都是用速度最快的存储介质呢?我理解主要还是两个方面的原因1、是因为成本2、是CPU的运算速度。因为CPU是不可能同时处理所有数据的。所以对于暂时不要用的数据,我们没必要都直接放到离CPU最近的地方。我们在业务上面处理冷、热数据和计算机自身的设计其实是相通的。
常用场景和缓存在中间件的使用: 在实际应用中,缓存可以应用于多个场景。
例如,在使用Mybatis时,可以使用一级缓存和二级缓存。
消息队列可以用于异步写入磁盘。
Mysql的InnoDb Buffer pool也是一种常见的缓存机制。
常用的缓存类型:
| 优点 | 缺点 | 示例 | |
| 本地缓存 | 速度快,无额外io | 集群模式下一致性难以保证、容量有限、数据丢失 | guava、caffeine |
| 分布式缓存 | 容量大、可集中管理、缓存维度数据一致性 | 网络IO、QPS受限 | redis |
| 多级缓存 | 解决了本地缓存和缓存中间件的问题 | 复杂度较高,维护成本高 | 阿里jetcache、有赞TMC、 |
我们平时常见的缓存大致有以下三种,他们各有优缺点。在实际使用时,我们可以根据实际的业务特点进行选择。例如对于变化很少的数据,数据量体积较小的数据,例如数据字典、交易日历等可以采用本地缓存,其他的大家可以以此类推,在这里就不赘述了
缓存架构和读写策略/更新方式:
常见的缓存读写策略包括Cache Aside(旁路)、Read/Write Through(读写穿透)和Write Behind Through(异步缓存写入)。
Cache Aside:
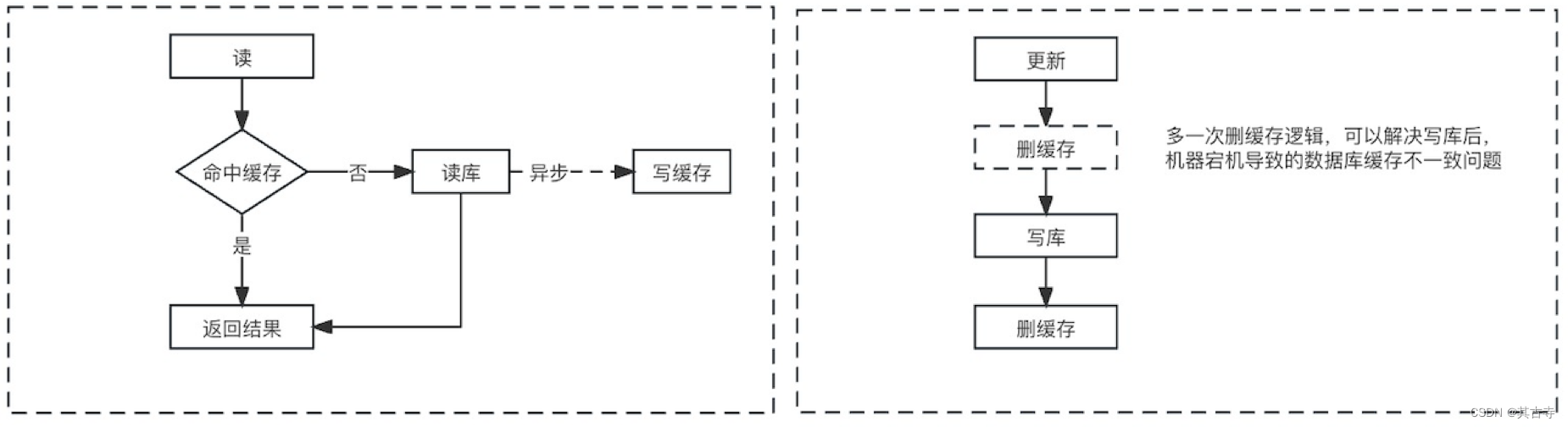
- 读取数据时,先从缓存读取,如果缓存中不存在,则从数据库中读取,并将数据存入缓存。 - 写入数据时,先更新数据库,然后删除缓存中的数据。 - 缺点/问题:首次请求数据不存在时需要特殊处理;频繁更新可能导致缓存频繁被删除;可能出现缓存穿透的问题。 - 优点:实现简单,仅保存实际请求数据。
Write Behind Through(异步缓存写入):
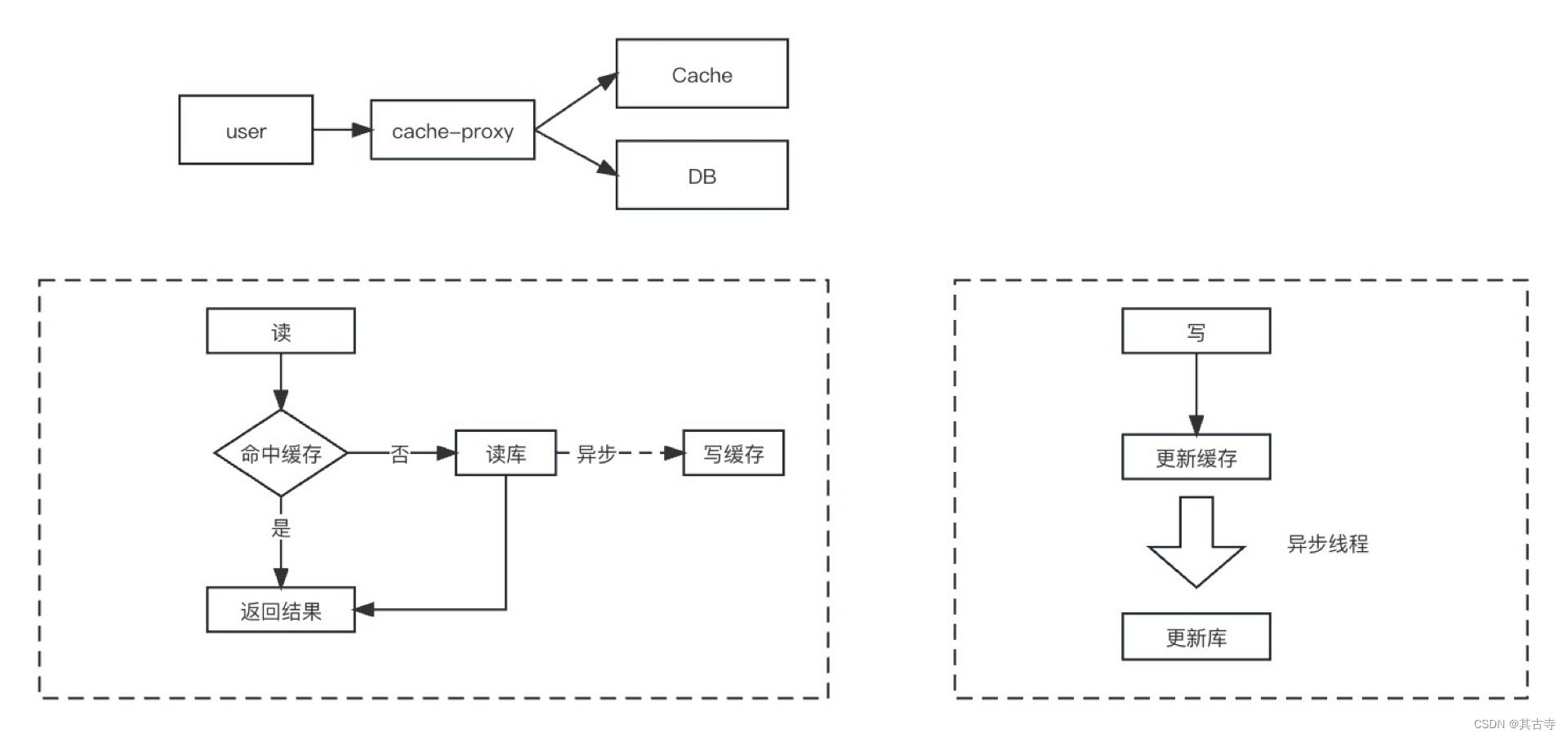
- 写入数据时,先更新缓存,然后异步批量更新数据库。 - 不直接更新数据库,通过异步方式提高写入性能。
这里我们抽象出了一个缓存代理,读写请求都只会和代理交互,读取逻辑和旁路模式相同。只是写入逻辑调整为了更新缓存,后批量写的模式。看到这里,大家想起来我们常用的中间件有哪些地方使用了这个策略么?消息队列异步写磁盘、Mysql InnoDb Buffer pool
Read/Write Through(读写穿透)

和异步缓存一样业务层都是通过代理和缓存交互,读逻辑没有变化,只是写逻辑做了调整,写入数据时先检查缓存,如果不存在,则直接更新数据库,如果存在则更新缓存并将数据库也更新。 这个策略只适用与写流量特别高的场景,例如秒杀库存限制。
Cache Coherency(缓存一致性)
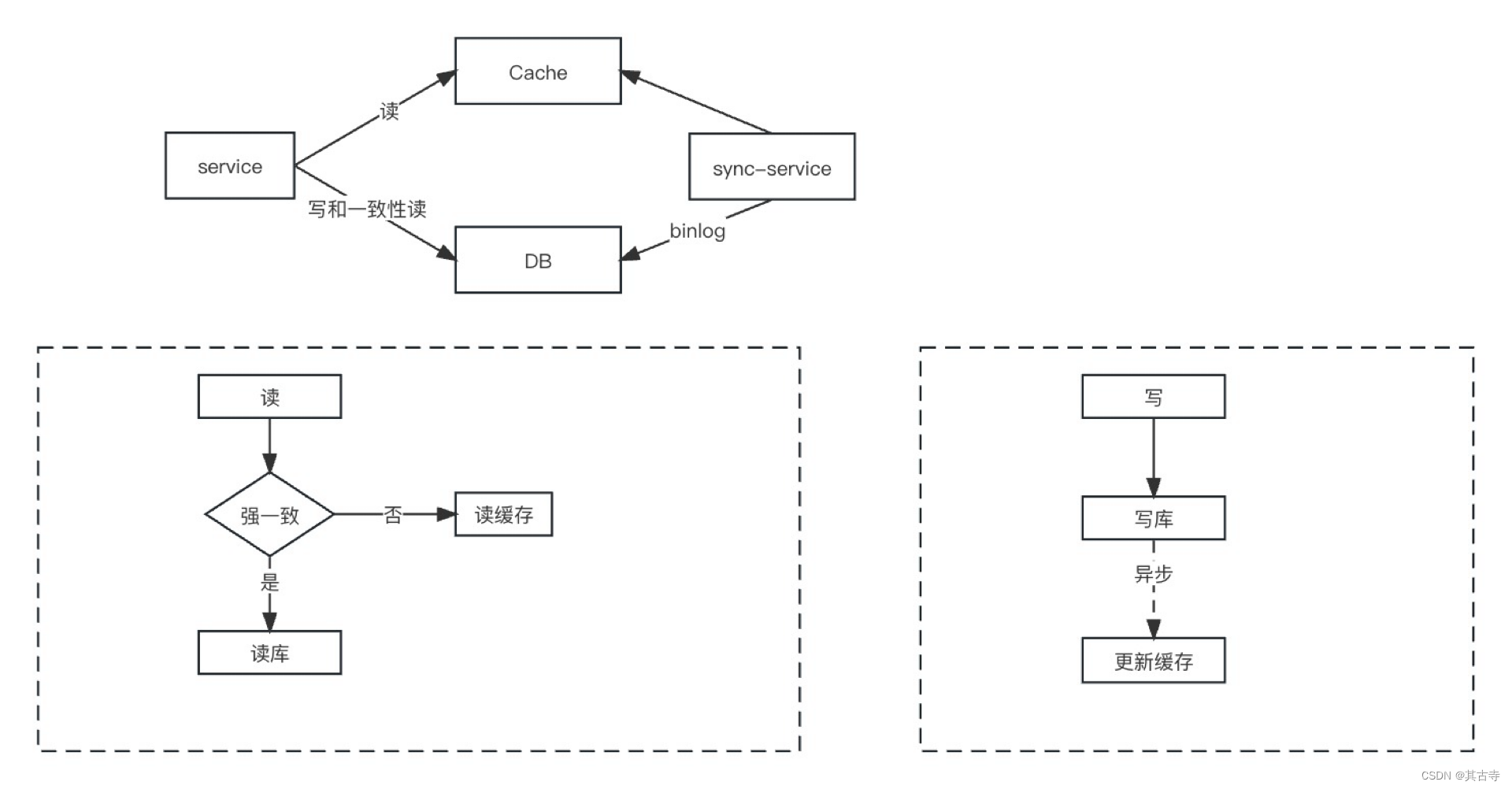
主要是通过使用一致性协议(如MESI协议)来保持缓存和数据库或多个缓存之间的数据一致性,当一个缓存修改数据时,会通知其他缓存进行更新。本质上就是数据异构
总结:
| 策略名称 | 读取速度 | 写入速度 | 内存占用 | 一致性保证 | 适用场景 |
| Cache Aside | 快 | 快 | 高 | 不保证 | 读多写少的场景,数据较为静态,对一致性要求较低的应用 |
| Read/Write Through | 快 | 慢 | 低 | 保证一致性 | 高度一致性要求的应用,读写频率相对均衡,对数据准确性要求较高 |
| Write Behind Through | 快 | 快 | 高 | 不保证 | 写频率较高的应用,对读取一致性要求较低,可以接受一定程度的数据不一致性 |
| Cache Coherency | 快 | 快 | 高 | 保证一致性 | 多个缓存之间需要保持数据一致性的应用,如分布式系统等 |
常见问题和正确使用姿势:
在使用缓存时,可能会遇到以下问题:
缓存穿透:
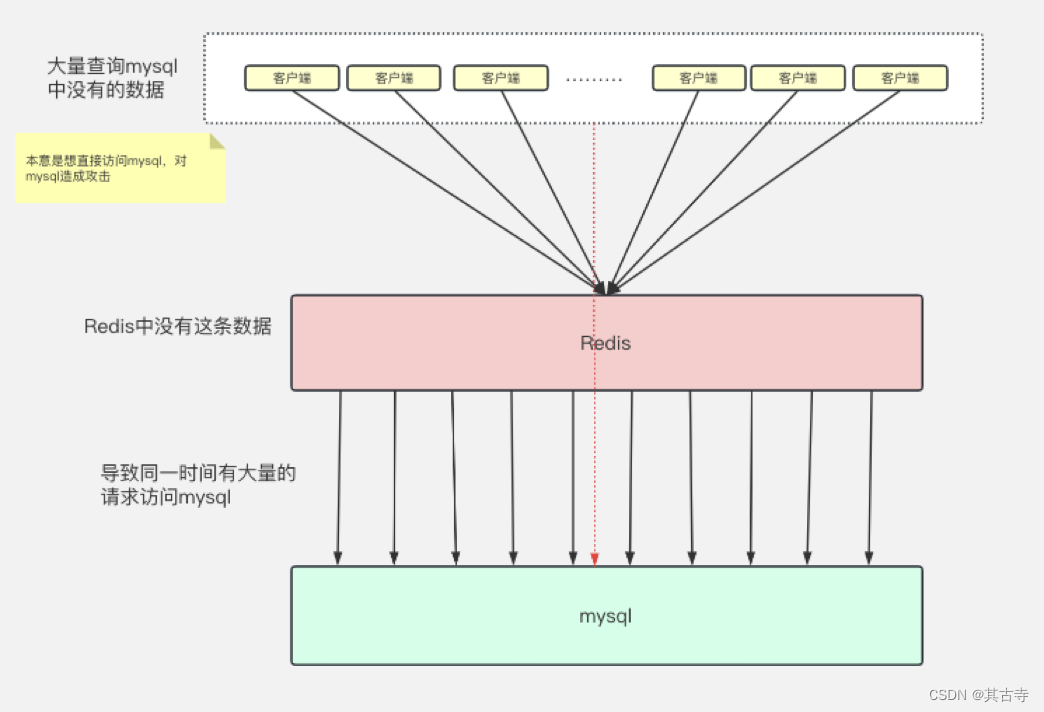
指请求的数据在缓存和数据库中都不存在,导致每次请求都需要访问数据库。 - 解决方案:可以使用布隆过滤器等技术来过滤无效的请求。
缓存击穿:
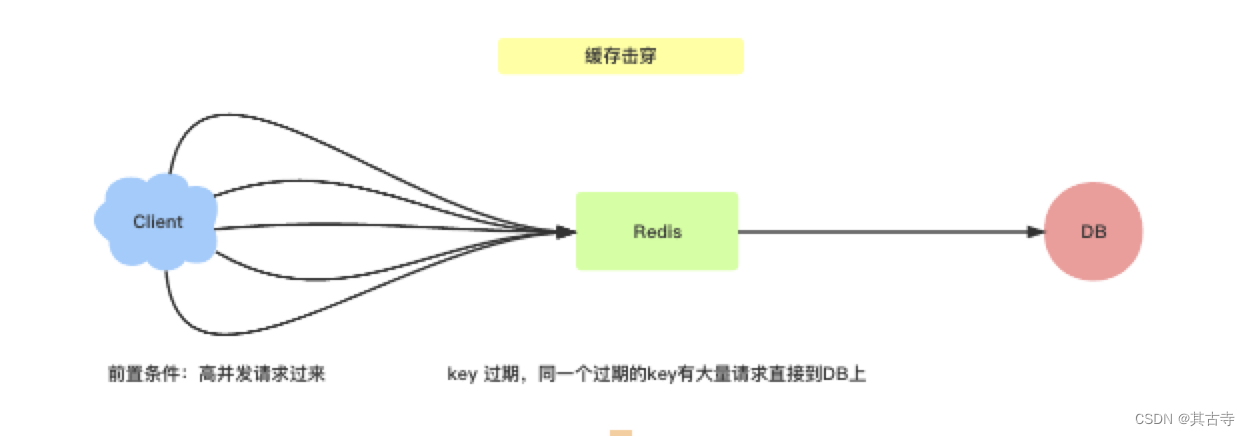
指某个热点数据失效,导致大量请求直接访问数据库,导致数据库压力过大。 - 解决方案:可以使用互斥锁或分布式锁来保护热点数据,避免并发访问数据库。
大key:

热key:
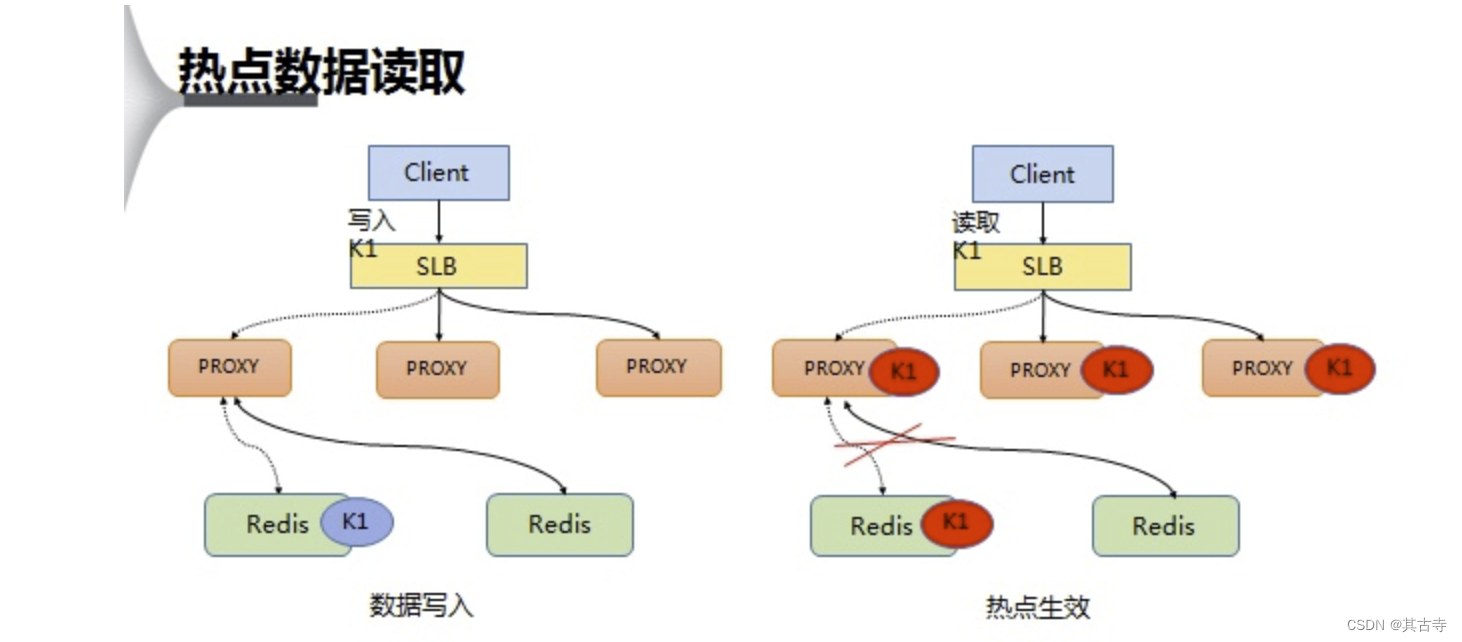
指某个key的访问频率非常高,导致该缓存项的性能瓶颈。
- 方案:
- 使用更高性能的中间件
- 缓存中间件读写分离,新增读副本(堆机器)
- 应用程序新增热Key本地缓存
雪崩:
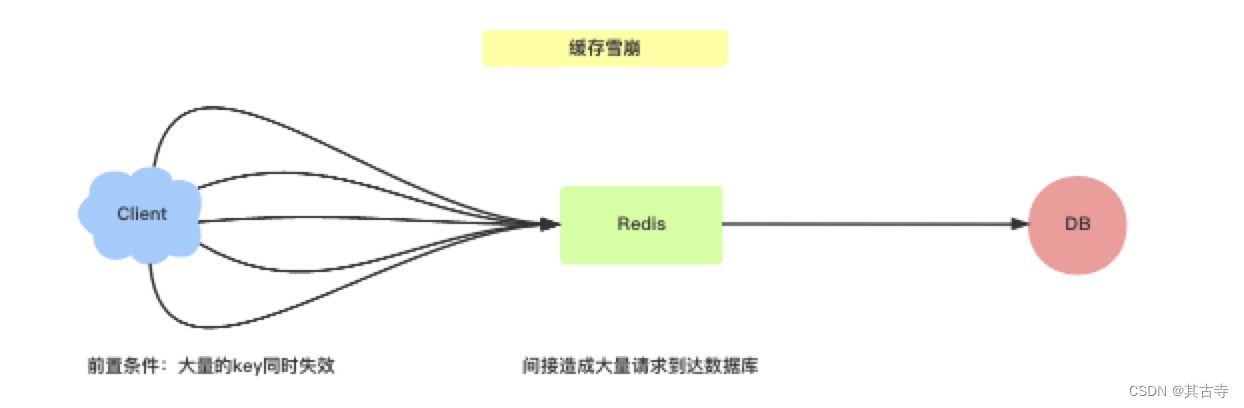
指缓存中大量数据同时失效,导致大量请求直接访问数据库,造成系统崩溃。
- 方案:
- 可以使用缓存过期时间随机化、限流等手段来避免大量缓存同时失效。
- 将读写策略改为Cache Coherency或Write Behind Through(避免缓存失效)
- 缓存和数据库调用都新增限流,降级机制(兜底)
数据一致性:
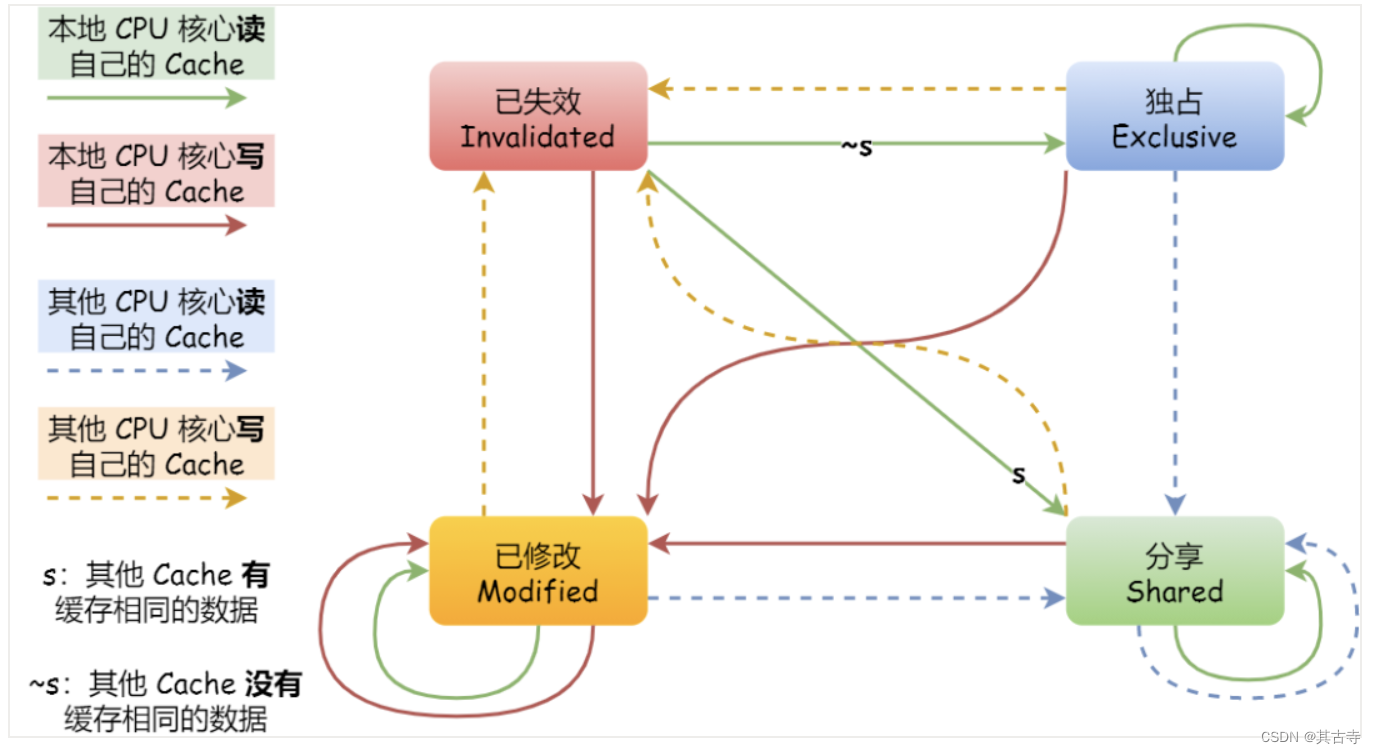
在分布式缓存中,需要考虑数据一致性的问题。 -
解决方案:
- 缓存设置失效时间作为兜底策略
- 通过合理的加载机制减少不一致的可能性和时间
总结
这是关于缓存的一些基本概念和正确使用姿势的介绍。如有更多详细问题,可以进一步讨论。
最后的啰嗦
1.各种高级的设计都来源于实际场景,很多场景在实际工作中是比较难遇到。所以我们有必要通过其他途径拓展自己视野。
2.实际开发时,不要过渡设计。越复杂的逻辑出问题的概率越高。















 169
169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









