







最近对爬虫很有兴趣,又没项目来让我练手,直到上周五有个想做医疗行业内容创业的老板联系我,给了我一堆网站,说是要做数据挖掘,当时博主就来劲了,说开练就开练。
----------分割线--------------
项目背景介绍完毕,接下来博主将不定期更新该爬虫的学习,分析和码代码的过程~~
准备工具:
语言:python
库:requests,beautifulsoup
相关工具:firefox ,HttpRequester
调试:ipython
爬虫目标:http://www.dxy.cn/bbs/index.html
First step
——
看看目标网页都有啥

论坛长这样。。。。。。。略丑,医生嘛,突出实用,反正本博主只识字,不知道上面写的啥。。。。。
接下来看看代码:
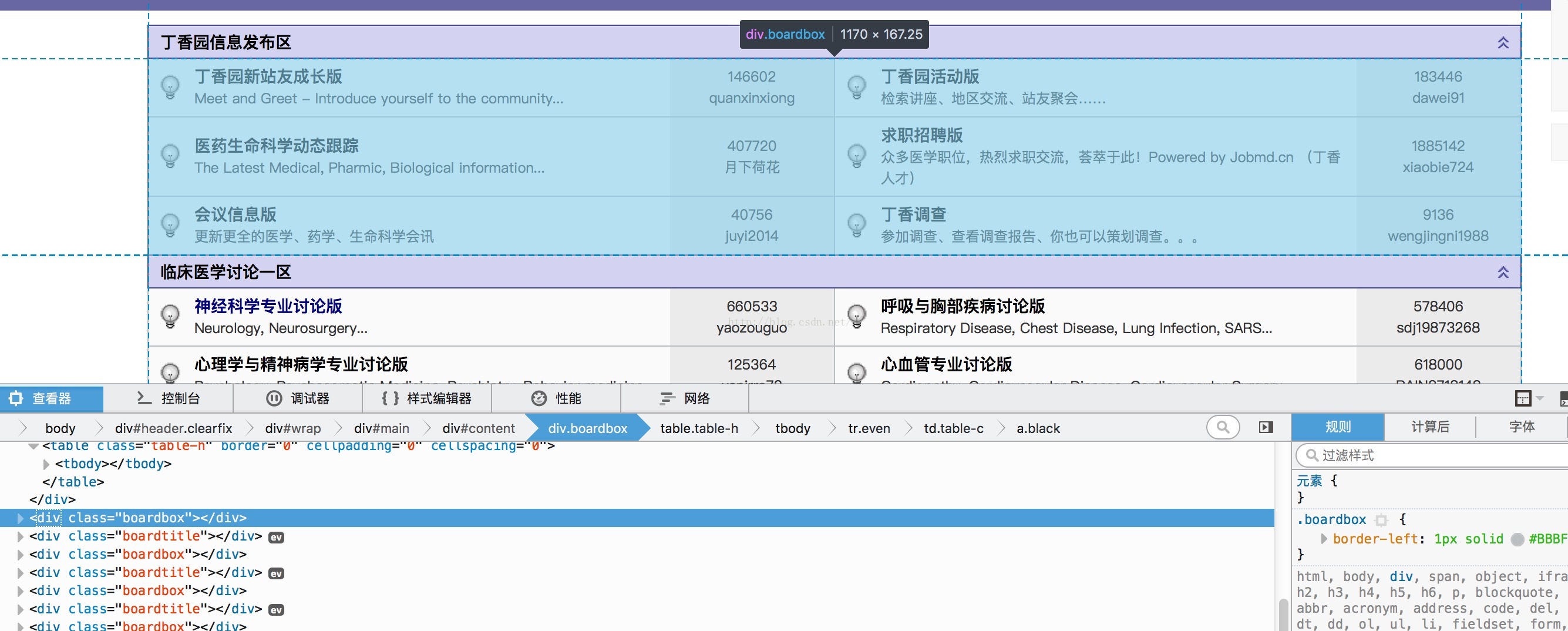
看来主要内容在这个叫 boardbox 的class 里面,mark 一下 boardbox,
接下来看看这里面都有些啥呢:
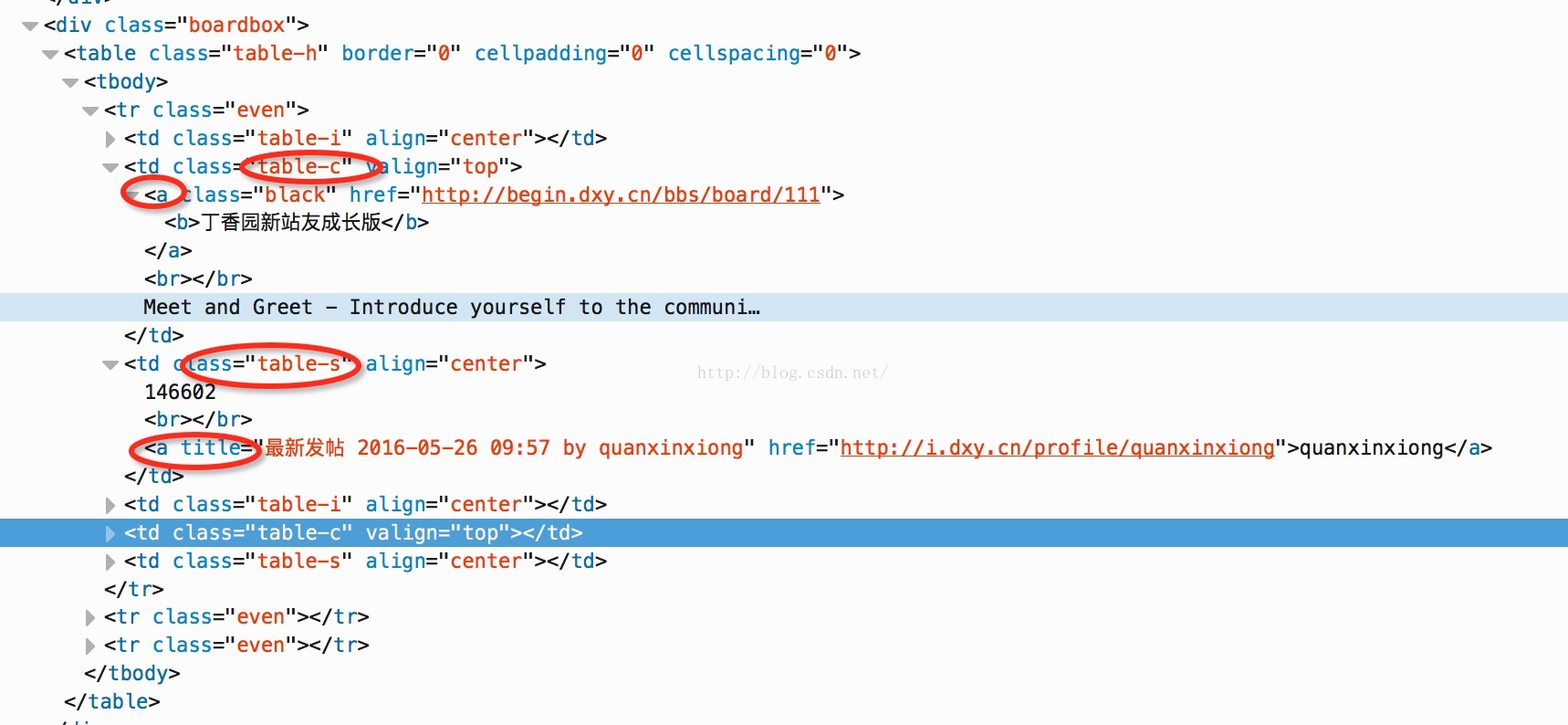
主要的标签都在这里了。。。。
内容都在这里面了
Second step
——-
直接上代码:
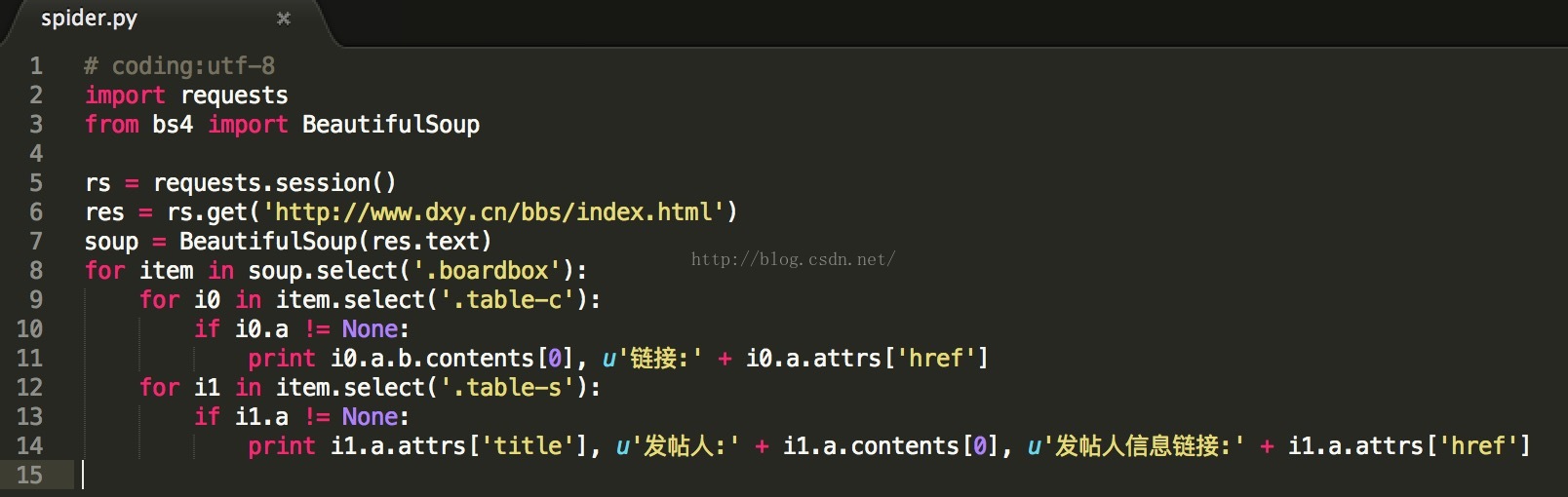
来吧,骚年,run起来~~~
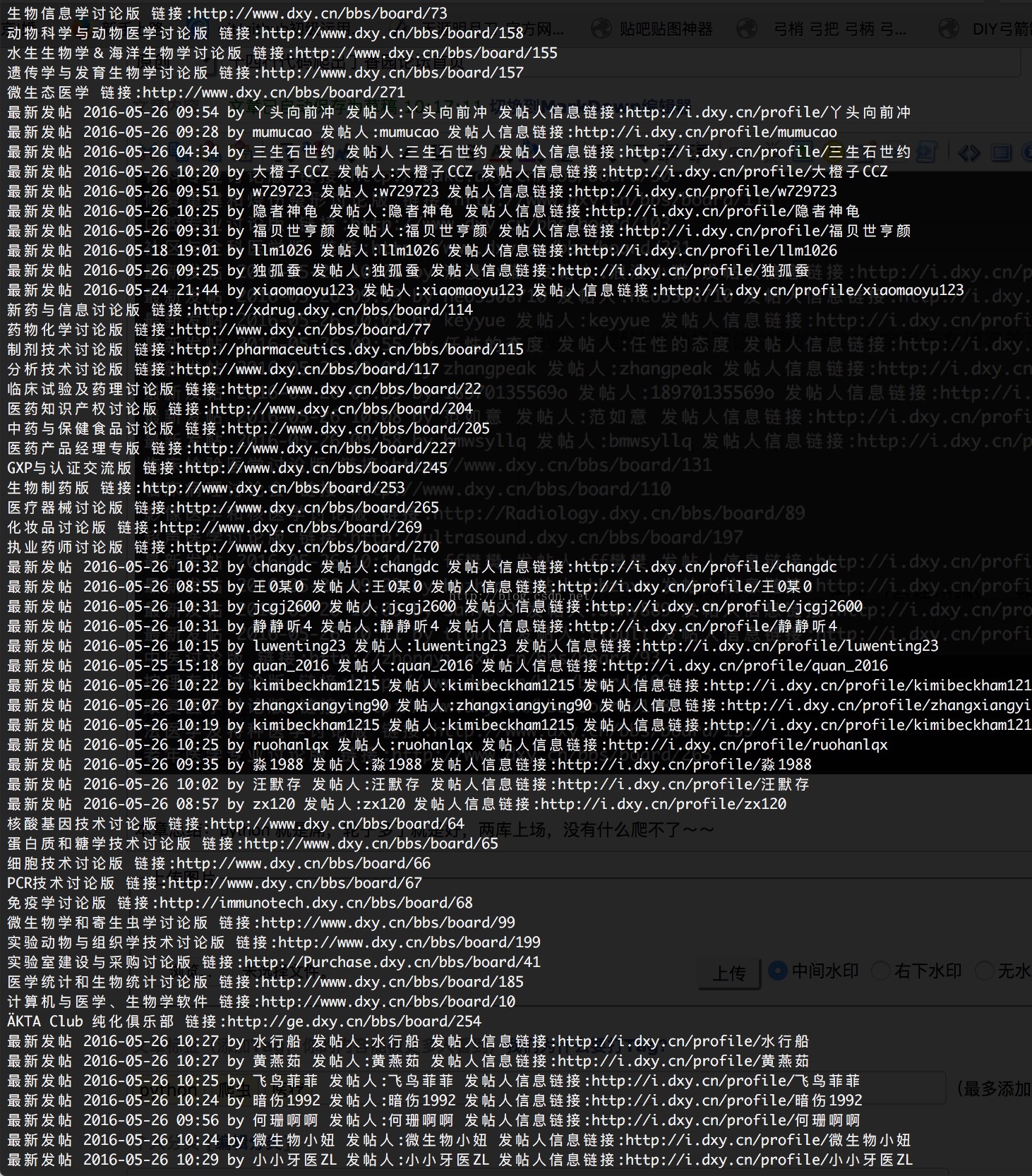
本章总结:python 就是屌,轮子多了就是好,两库上场,没有什么爬不了~~















 562
562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









