






一、背景
2019,CIKM 闲鱼垃圾评论。
我们先看看广告评论怎样越来越隐秘:
- 换个说法:使用不同的方式表达相同的意思,例如「拨打电话获得更多兼职信息」和「闲余时间挣点钱?联系我」,这两者都引导我们关注相同的兼职广告。
- 关键字替换:使用少见的中文字符、笔误,甚至表情符号替换关键字,例如「加我的 VX/V/WX」都表示加我的微信。
这些小技巧很容易绕过机器,同时黑产又不断对抗,所以总是防不胜防,线上系统的过滤效果逐步降低。
二、整体框架
如何解决?—— 核心思想在于 上下文。把文本信息的上下文综合考虑进行,才能准备判断它到底是不是垃圾评论。
本文定义了两种上下文:局部上下文 和 全局上下文
- 局部上下文:这条评论的 user 特征、item 特征
- 全局上下文:当前评论在全局中的特征
整体框架如下:
- 左侧异构图(局部上下文),基于异构图GCN,得到 item (商品)、user (用户)、e (评论) 的 embedding (信息)
- 右侧同构图(全局上下文),基于 GCN,得到类似评论表达的意义
- 结合所有信息,进行分类(将传统的文本分类问题,抽象成异构图上的边分类问题)
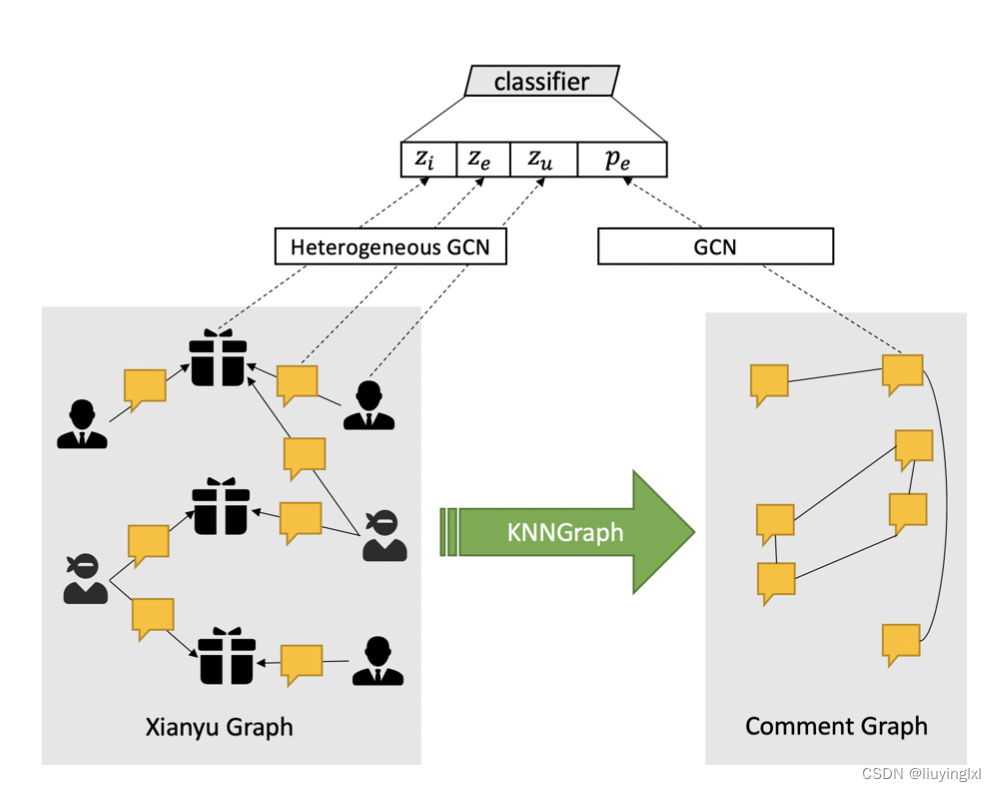
2.1 Xianyu Graph(局部信息)
异构图:节点为 用户(U) 与 商品(I),边(E) 表示用户对商品进行了评论

一般图卷积的层级可以分为聚合(aggregation)与结合(combination)两大操作。其中 AGG 会聚合邻近节点的嵌入向量,例如最大池化或基于注意力权重的加权和等。COMBINE 操作会结合自身的嵌入向量与前面聚合的嵌入向量。
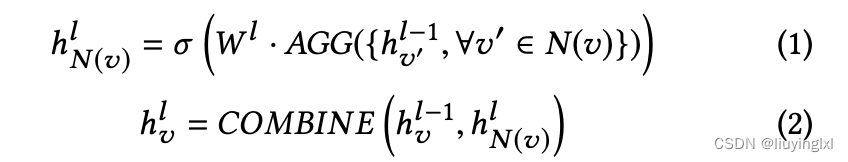
而本文提出的 GAS 模型对异构图的学习,也是主要在这两个方面做改动:
GAS 中,聚合操作为:
- 相比GCN,除了将信息聚合到节点上,还将信息聚合到边上,包括对应边的信息、user节点信息和item节点信息,聚合方式为 concat
边的聚合:
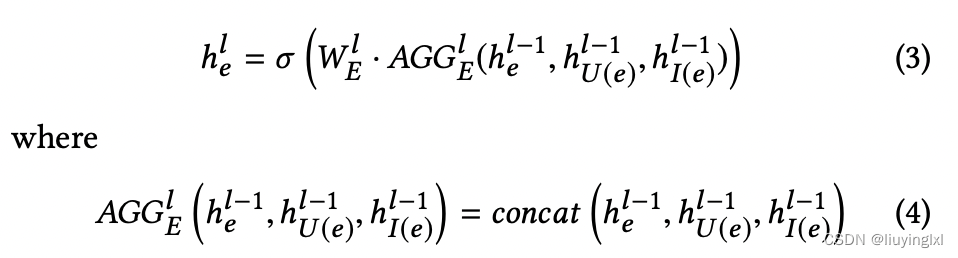
user节点、item节点聚合:
- 理解:对于单个用户节点,输入就是邻近商品节点以及邻近评价边的特征。例如一个用户评论了 10 件商品,那么每一个商品向量拼接上对应评论向量,这 10 个特征向量就可以作为输入,后续图卷积就会对它们进行基于注意力机制的聚合等一系列操作。
聚合了邻居信息的 user/item 节点信息:
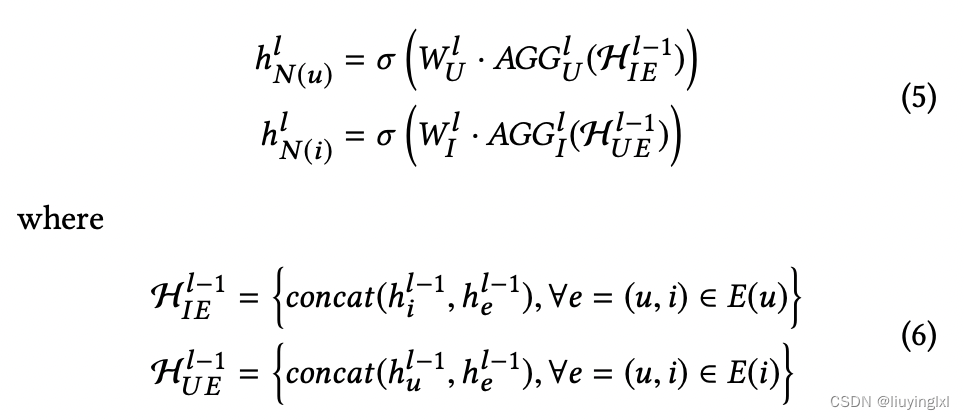
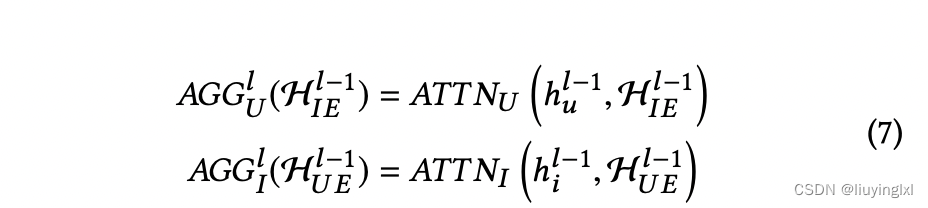
公式(7)是对于所有的邻居,进行简单的 attention 操作(向量内积):
- 比如 与用户 u 相邻的共 5 个商品 5 条评论,则对于每个 商品-评论 embdding,与对应用户的 embedding 计算内积作为 attention 权重
GAS 中,combination 操作为:
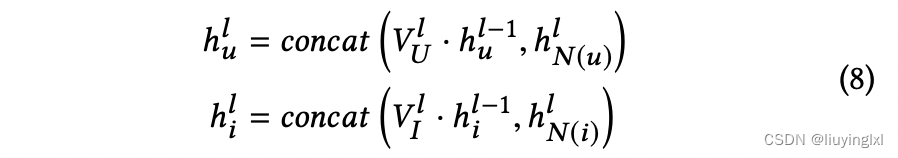
- V 为训练参数
伪代码如下:
通过对异构图 Xianyu Graph 的学习,可以得到 评论边、用户节点、商品节点的 向量表示。


另外,该模型还结合了 textCNN,因为要获取评论的 embedding。首先将每个词利用 word2vec 得到每个词的表示,再将每个词的表示输入到 textCNN 中学习评论的 embedding。textCNN 与 GCN 进行联合的 end2end 训练。
2.2 comment graph(全局图)
上述异构图 Xianyu Graph 主要处理邻近节点的局部信息,但与此同时还应该能处理全局信息,这样才能有效地减轻用户的对抗行为。为此,模型应该站在所有评论的角度,看看与当前相似的评论都是什么样,它们是不是垃圾评论,即利用 GCN 的特性,“thefeatures of nodes can be smoothed by its neighbors”。
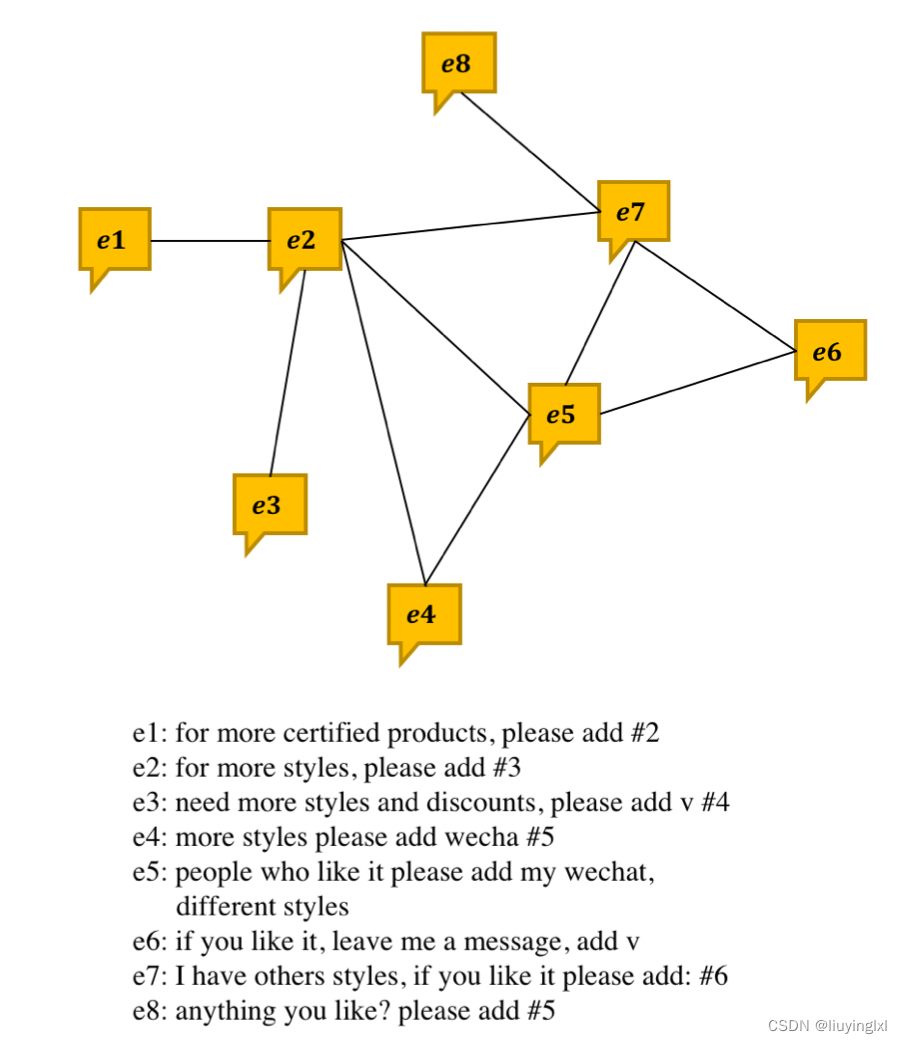
本文基于 Xianyu Graph 构建了一种新的 Comment Graph(相似评论图),它是一种同构图,每一个节点为评论内容,节点之间的边为两条评论之间的相似性。因为相似的评论距离非常近,因此模型可以考虑与当前评论相近的评论,从而更好地判断当前评论是不是垃圾评论。
由于是想利用邻居进行对当前节点特征进行平滑,故重点在于图的构造!图的构造中,最重要的在于,如何计算相似性,为了降低复杂度,使用 KNN Graph algorithm 进行相似度的计算,即找到最相似的 k 个邻居。(对 KNN Graph 算法感兴趣的可阅读论文:Efficient k-nearest neighbor graphconstruction for generic similarity measures.)
下图所示为一小部分 Comment Graph,如果说局部模型无法根据「add v」判断出意思是加微信,那么放在 Comment Graph 中就非常明确了,它与类似的说法都应该被判断为垃圾评论。
简单而言,Comment Graph 的构建主要分为四个步骤:
- 去重:移除所有重复的评论;
- 通过词嵌入模型为评论生成嵌入向量;
- 利用 KNN Graph 算法获得相似的评论对;
- 移除同一用户提出的评论对,或者发布在统一商品下的评论,因为之前的闲鱼 Graph 已经考虑了这些信息。
利用 GCN 对 graph 进行学习,得到平滑后的 comment embedding。
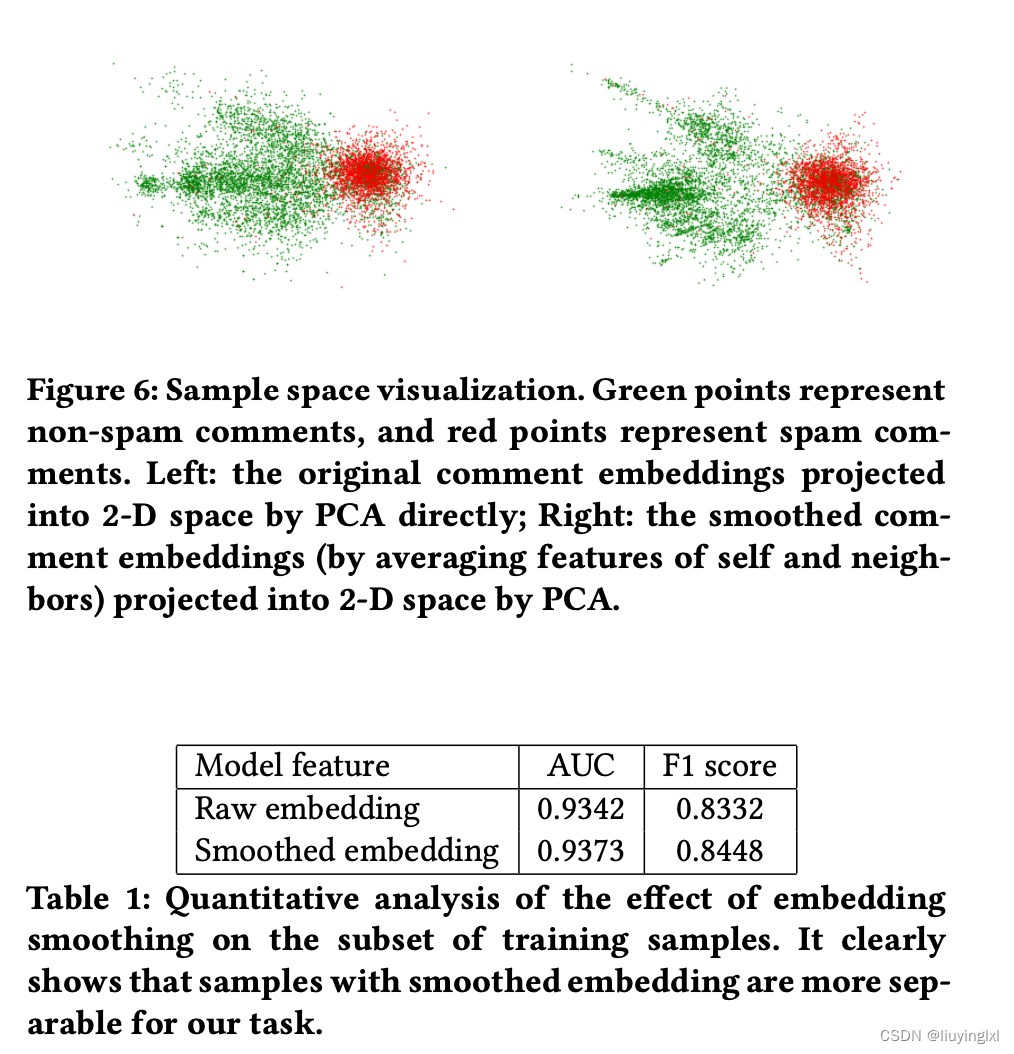
通过这种方式,各种垃圾评论可以通过整合其邻居的特征而被平滑化。通过可视化以及实验结果可以看出,经过该处理后的特征更具有分离性(异常的评论更加异常,正常的评论更加正常),如图:
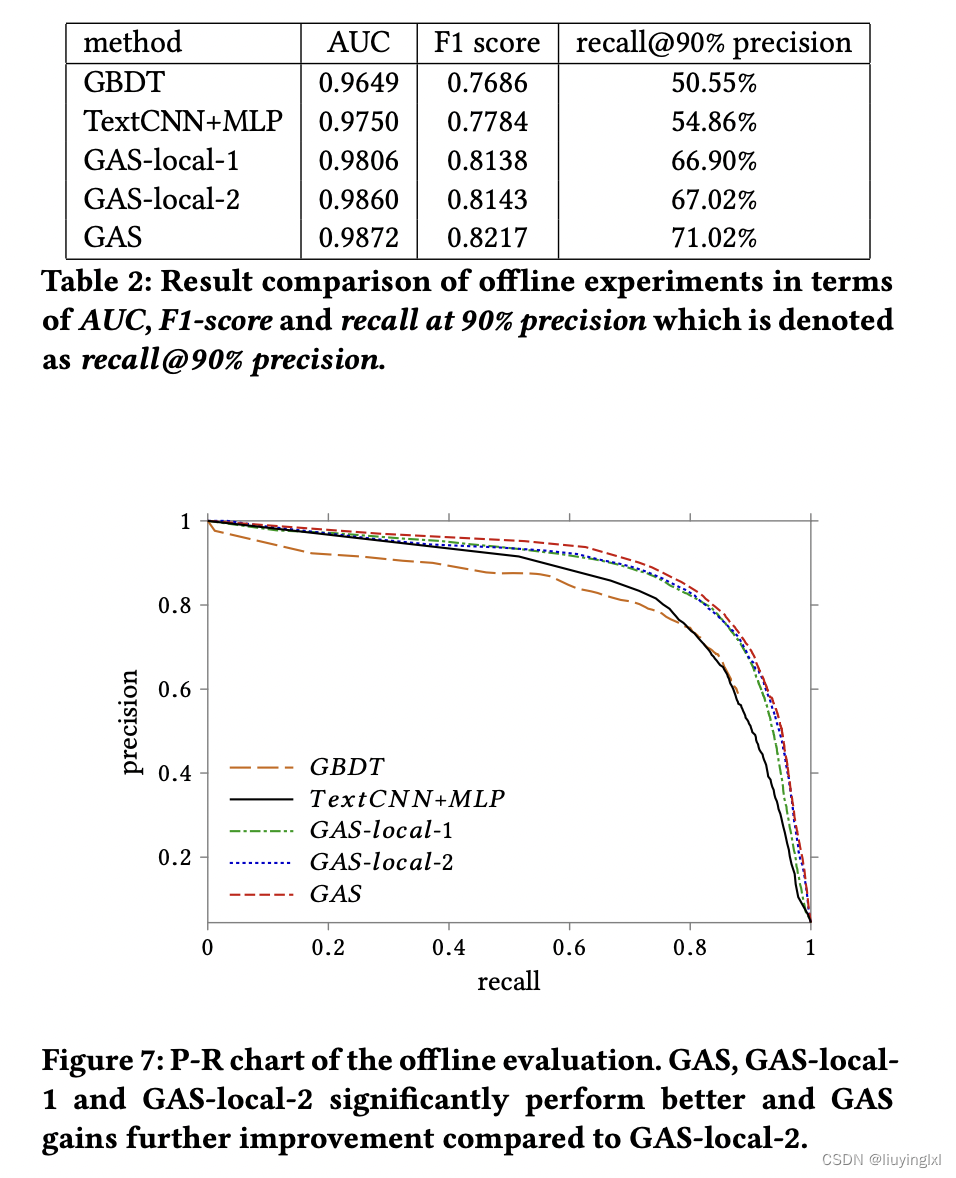
2.3 实验结果
对比实验:
- GBDT:为评论、用户、商品构造了大量人工特征
- 评论长度、是否是该物品的第一个评论、是否是该物品的唯一评论、评论和物品特征的余弦相似度、物品价格、用户的评论数量等等。
- 对于评论信息:通过 互信息(mutual information)筛选出词库中 top 200 重要的词汇,然后用 200 维的 ont-hot 向量表示一条评论
- TextCNN+MLP:
- 评论信息:利用 TextCNN 学习评论表示
- 然后与人工构造的商品特征和用户特征拼接,利用 2 层 MLP 进行分类
- GAS-local-1:
- 仅使用异构图(Xianyu Graph),仅对一度邻居进行聚合
- GAS-local-2:
- 仅使用异构图(Xianyu Graph),对二度邻居进行聚合
- GAS:
- 本文提出的模型,Xianyu Graph + Comment Graph,对二度邻居进行聚合
- 本文提出的模型,Xianyu Graph + Comment Graph,对二度邻居进行聚合


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









