







 本文深入探讨序列模式挖掘算法PrefixSpan,介绍了算法的基本概念、核心思想和详细过程,并提供了配套代码链接。通过实例解析了PrefixSpan如何挖掘频繁序列模式,包括支持度计算、投影数据库的构建等。
本文深入探讨序列模式挖掘算法PrefixSpan,介绍了算法的基本概念、核心思想和详细过程,并提供了配套代码链接。通过实例解析了PrefixSpan如何挖掘频繁序列模式,包括支持度计算、投影数据库的构建等。
序列模式挖掘算法之PrefixSpan
PrefixSpan 配套代码地址http://download.csdn.net/download/u012202808/9961002
本文从基本的概念和例子入手,最后通过讲解代码来解释PrefixSpan算法:
- 序列模式挖掘简介
- 序列模式挖掘的基本概念
- PrefixSpan的基本概念
- PrefixSpan算法过程讲解
- 主要代码块展示和讲解
序列模式挖掘简介
序列模式挖掘最早的提出是为了找出用户几次购买行为之间的关系。我们也可以理解成找出那些经常出现的序列组合构成的模式。它与关联规则的挖掘是不一样的,序列模式挖掘的对象以及结果都是有序的,即数据集中的项在时间和空间上是有序排列的,这个有序的排列正好可以理解成大多数人的行为序列(例如:购买行为),输出的结果也是有序的,而关联规则的挖掘是不一样的。
关联规则的挖掘容易让我们想到那个"尿布与啤酒"的故事,它主要是为了挖掘出两个事物间的联系,首先这两个事物之间是没有时间可空间的联系的,可以理解成它们之间是无序的。例如:泡面——火腿 在我们的生活中大多数人在买泡面后会选择买火腿,但是每个人购买的顺序是不一样的,就是说这两个在时空上是没有联系的,找到的是搭配规律。这就是关联规则挖掘。(这是我个人的理解,有不同理解的请讨论)
序列模式挖掘的挖掘出来的是有序的。我们考虑一个用户多次在超市购物的情况,那么这些不同时间点的交易记录就构成了一个购买序列,例如:1用户在第一次购买了商品A,第二次购买了商品B和C;那么我们就生成了一个1用户的购物序列A-B,C.当N个用户的购买序列就形成了一个规模为N的数据集。这样我们就可以找到像"尿不湿--婴儿车"这样的存在因果关系的规律。因此序列模式挖掘相对于关联规则挖掘可以挖掘出更加深刻的知识。
序列模式挖掘的基本概念
序列模式挖掘的定义为:给定一个序列数据库和最小支持度,找出所有支持度大于最小支持度的序列模式
我们通过下面的例子来加深我们的理解
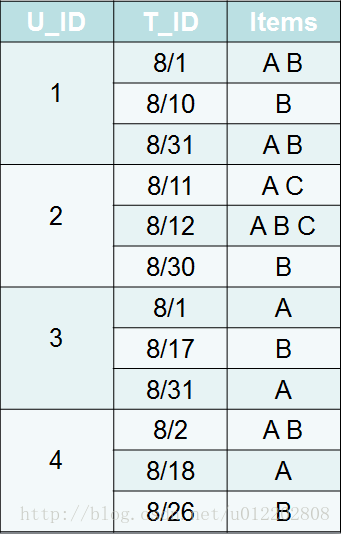
序列(Sequence):一个序列就是一个完整的信息流。
例如上面图中的U_ID 1 在8月1号购买了商品A和B&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









