







文章目录
使用virtual memory是为了实现三个目的(参见下面的vm as a tool for XXX)
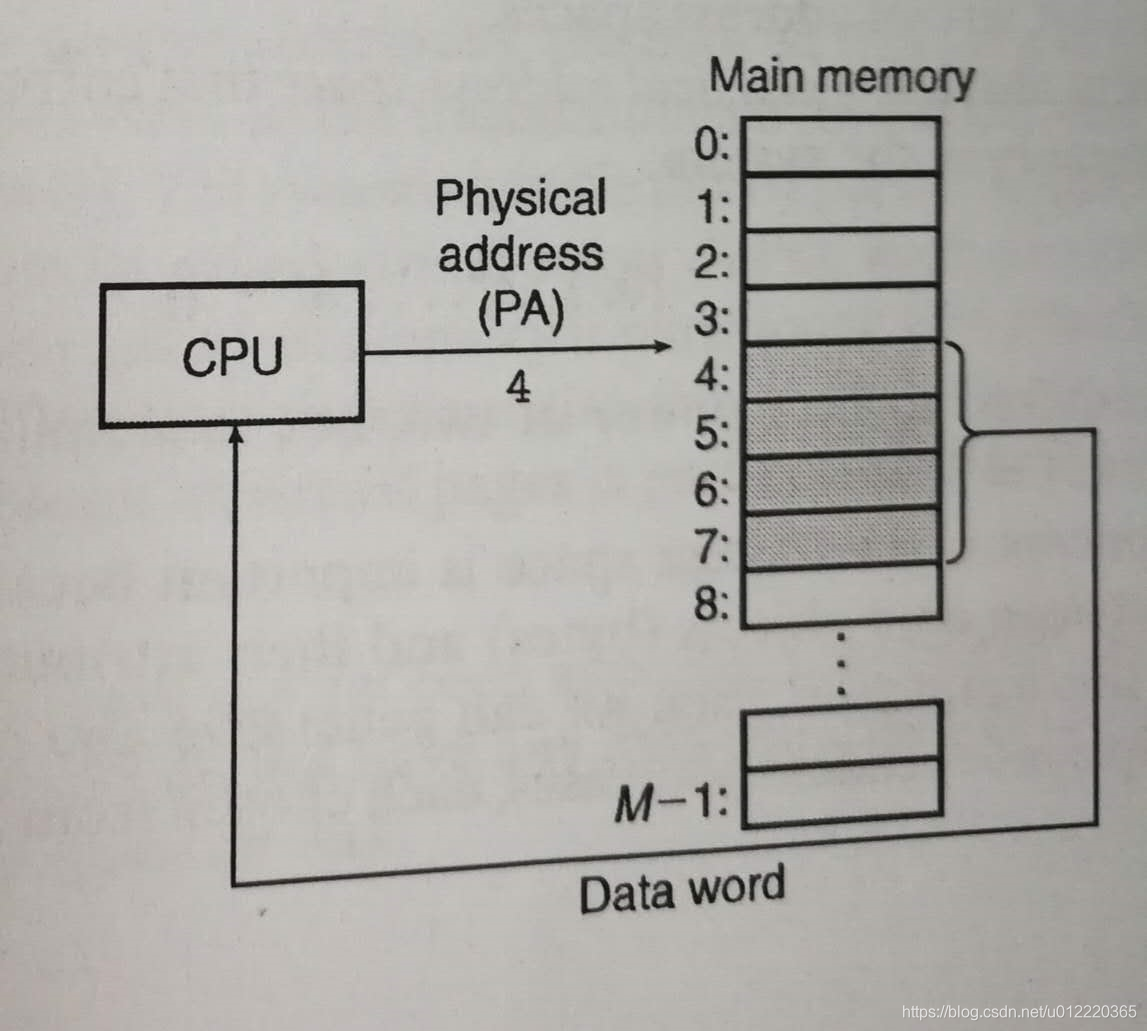
physical and virtual addressing
physical address对内存按byte编号,第一个是0,然后是1
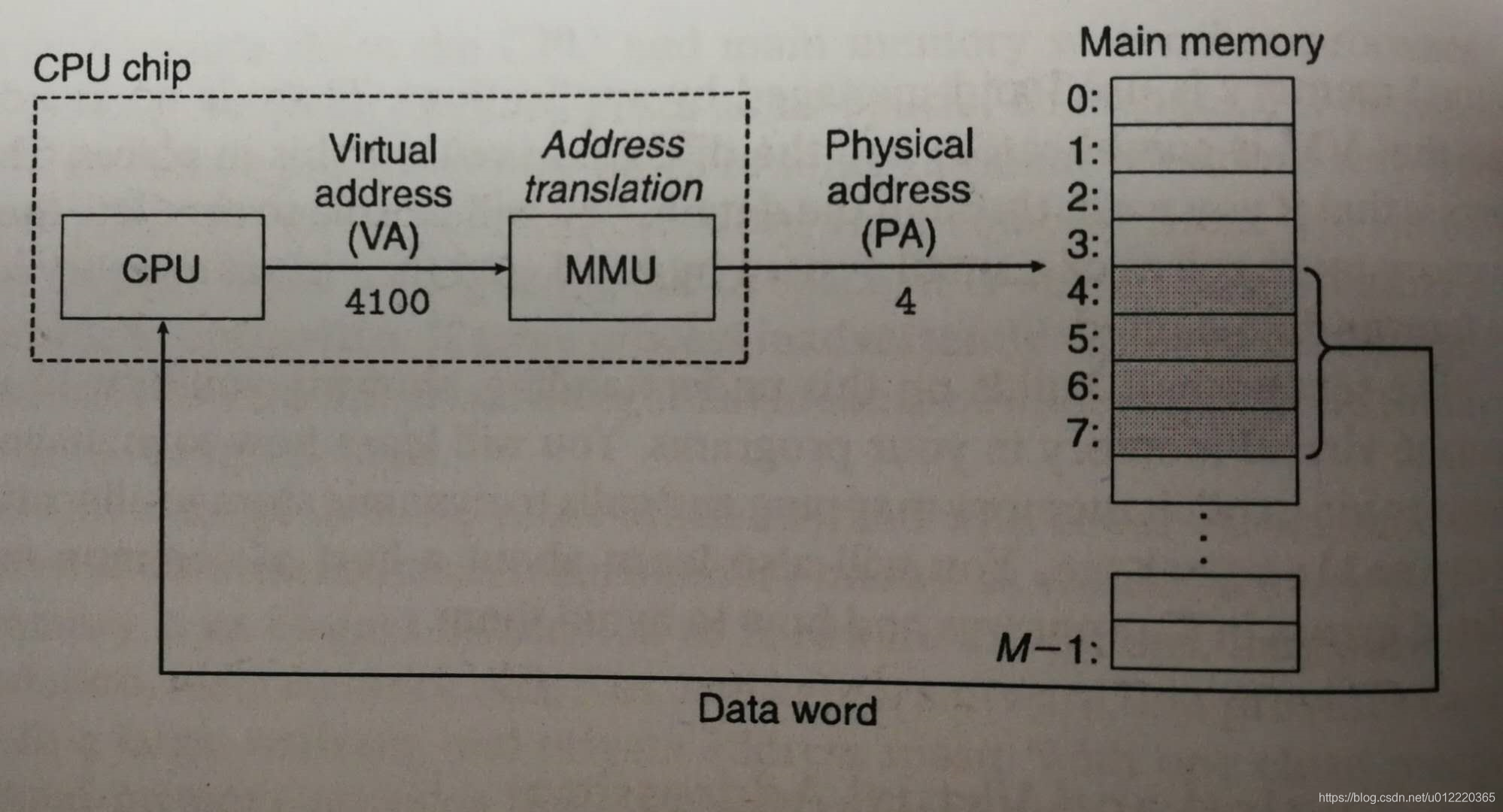
对物理内存的访问有两种方式,一种是直接访问,另一种是memory management unit配合OS维护的page table一起做address translation从而将CPU发送的virtual address转换为physical address
address space
一个
n
n
n-bit的CPU能访问
{
0
,
1
,
2...
2
n
−
1
}
\{0,1,2...2^n-1\}
{0,1,2...2n−1}这些地址,被称为virtual address space,而实际物理内存的地址被称为physical address space.他们关系如下

vm as a tool for caching
从概念上来看,可以把vm看作是硬盘上存储的大小为N的数组,而main memory是作为硬盘的缓存存放了部分数据.一般会把vm切分成大小为
2
p
2^p
2pbytes的virtual page,所以也会把物理内存也切分成相同的大小,一般称为physical page,也称为page frame.
在任何时间,一个virtual page处于下面三个集合之一
- unallocated
未分配,也不占用硬盘空间 - cached
缓存在物理内存 - uncached
未缓存在物理内存
DRAM作为DISK的缓存,但不同于SRAM作为DRAM缓存的算法,由于DRAM发生miss时代价更大(100000vs10),所以处理miss的问题是算法优先考虑的问题.所以采用了fully assiciative方案和write-back方案(在前面的The Memory Hierarchy有介绍这些方案)
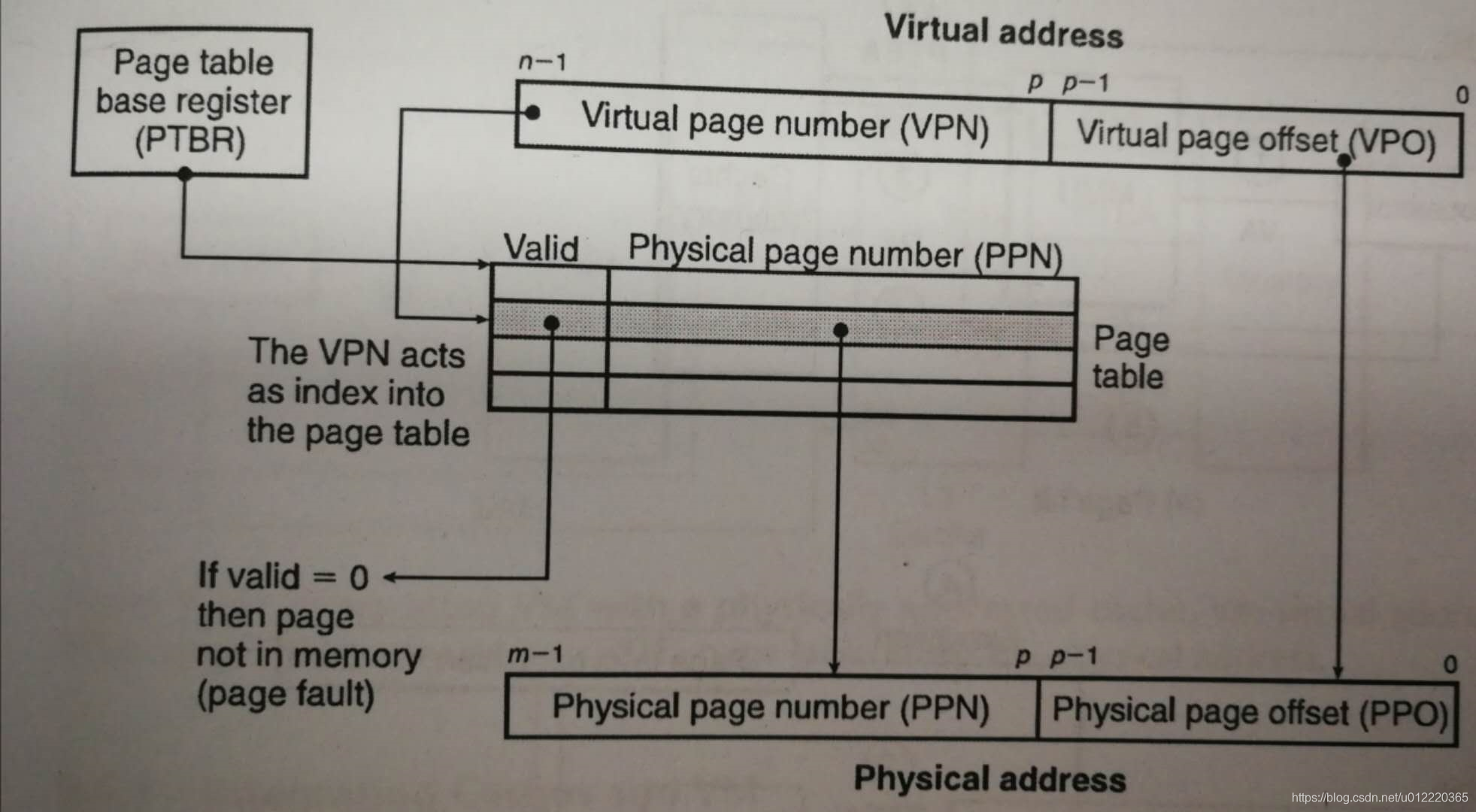
page table
一般采用page table来管理Virtual Page和Physical Page的关系,而page table是由一个PTEs(Page Table Entries组成,每个PTE是由一个标记为和一个physical address组成.具体参见下图
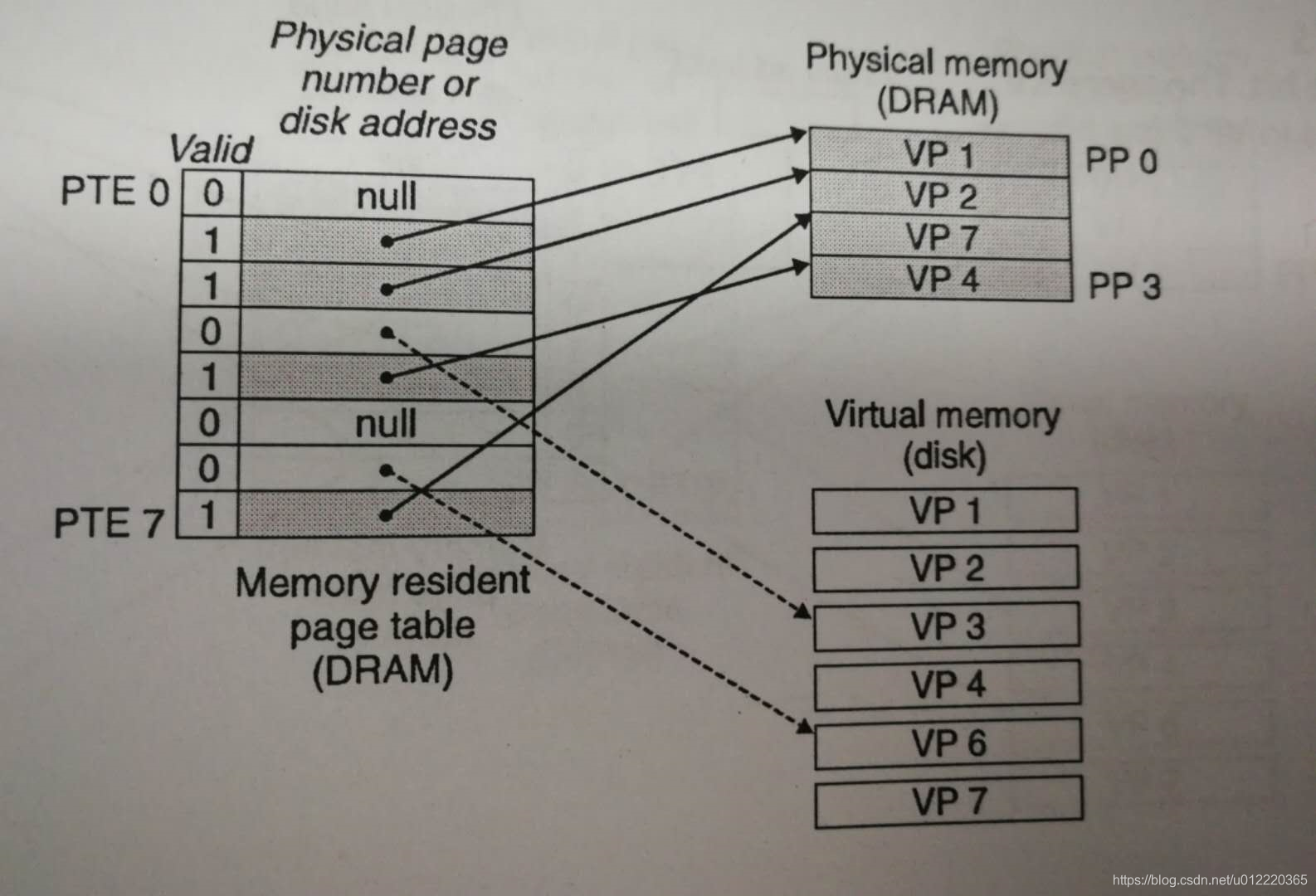
page fault
对于page hit而言比较简单.对于page fault的情况需要发出page fault exception来唤起kernel来处理这个问题.此时kernel会先选择一个victim page做出swapped out,如果这个victim page修改过则需要先保存到硬盘.然后做swappped in.
虽然预先知道miss的情况是可能的,但是大家还是选择了demand paging的方案,也就是等到最后一刻再处理
对于UNIX而言可以使用getrusage来查看page falut的情况
一般来说由于locality的存在,当前物理内存里的page(也称为working set或resident set)能满足需要,如果悲剧的频繁超出了大小,发生thrashing
vm as a tool for memory management
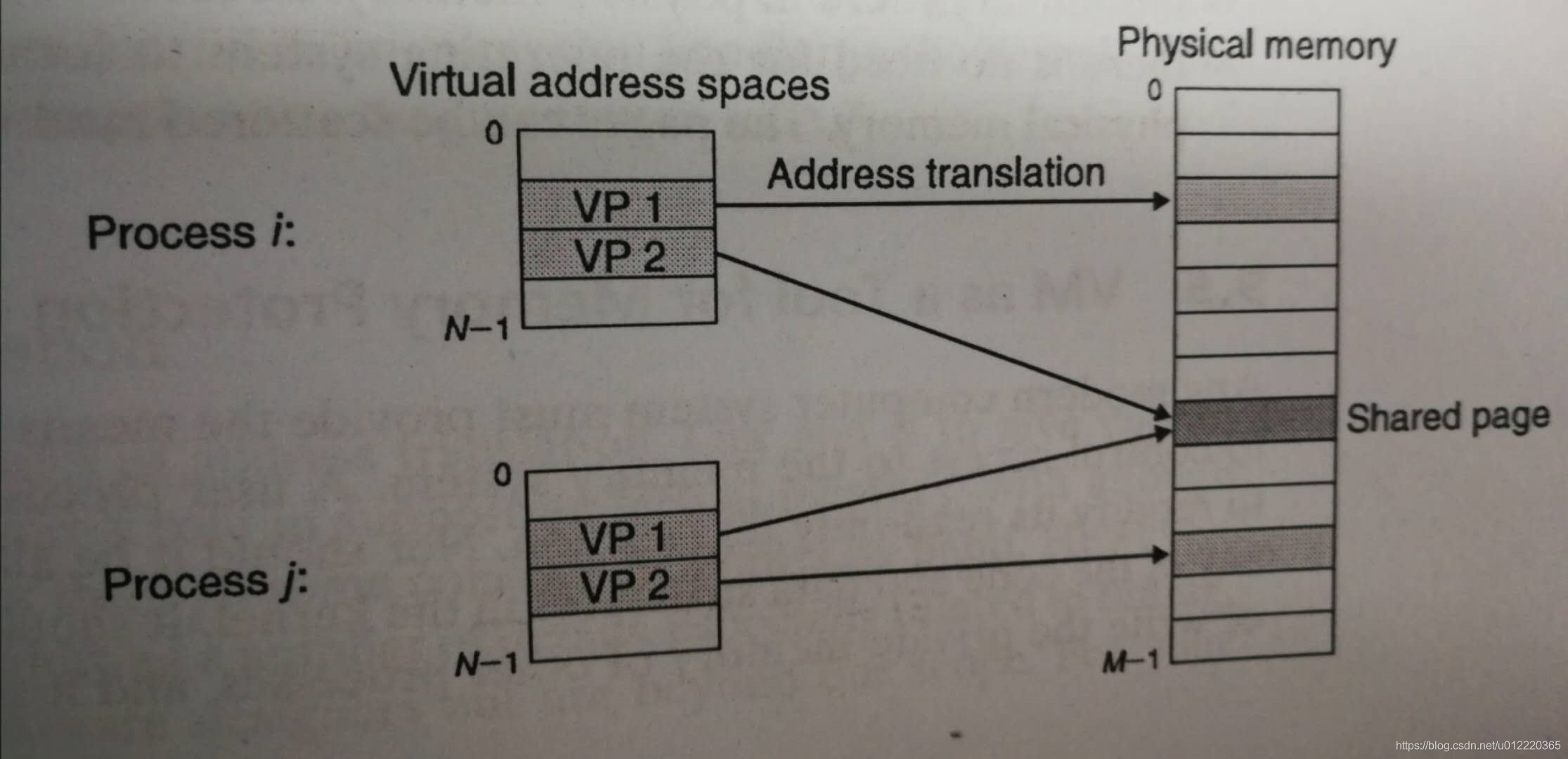
实时上OS会为每个process创建单独的page table,但是不同的process的VP可以映射到相同的PP,参见下图
使用vm来管理有以下诸多好处
simplifying linking
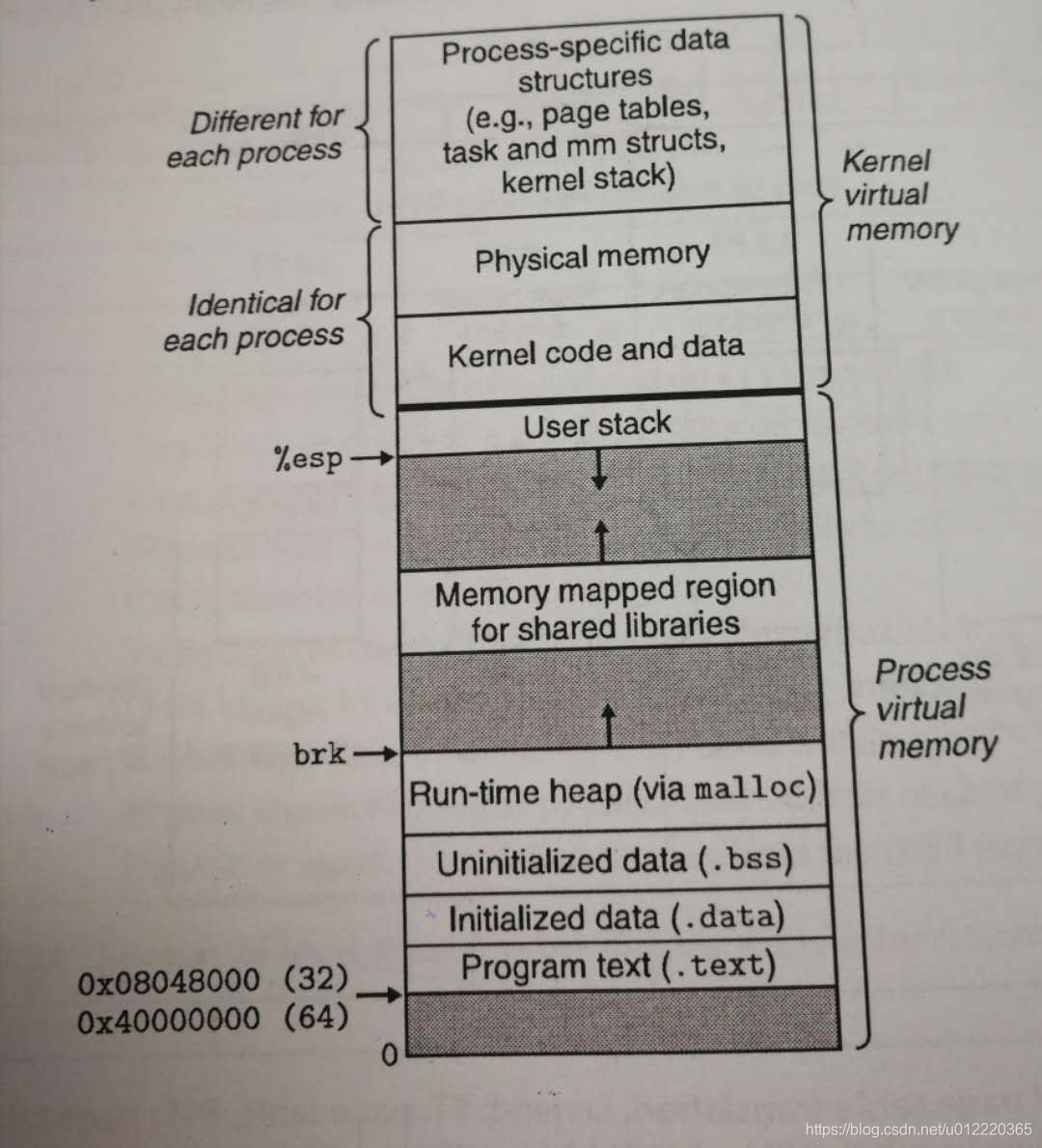
这样linker就可以知道text section总是从0x08048000或0x400000开始,并且清楚内部结构以及栈向下走的方向
simplifying loading
这样执行程序的时候也比较简单,不用把程序实际上加载到主存,只需要在PTE里标记invalid即可,这样就可以等到实际需要时再加载.Unix提供了**memory mapping(mmap)**来为程序提供了类似的做法.
simplifying sharing
如上图所示
simplifying memory allocation
一般内存申请时需要连续内存,由于vm的存在,可以将不连续的内存视为连续内存
vm as a tool for memory protection
通过在PTE上加一些控制标识来限定process对相应地址的操作,如下图所示

address translation
M
A
P
:
V
A
S
→
P
A
S
∪
∅
MAP:VAS\rightarrow PAS \cup \emptyset
MAP:VAS→PAS∪∅
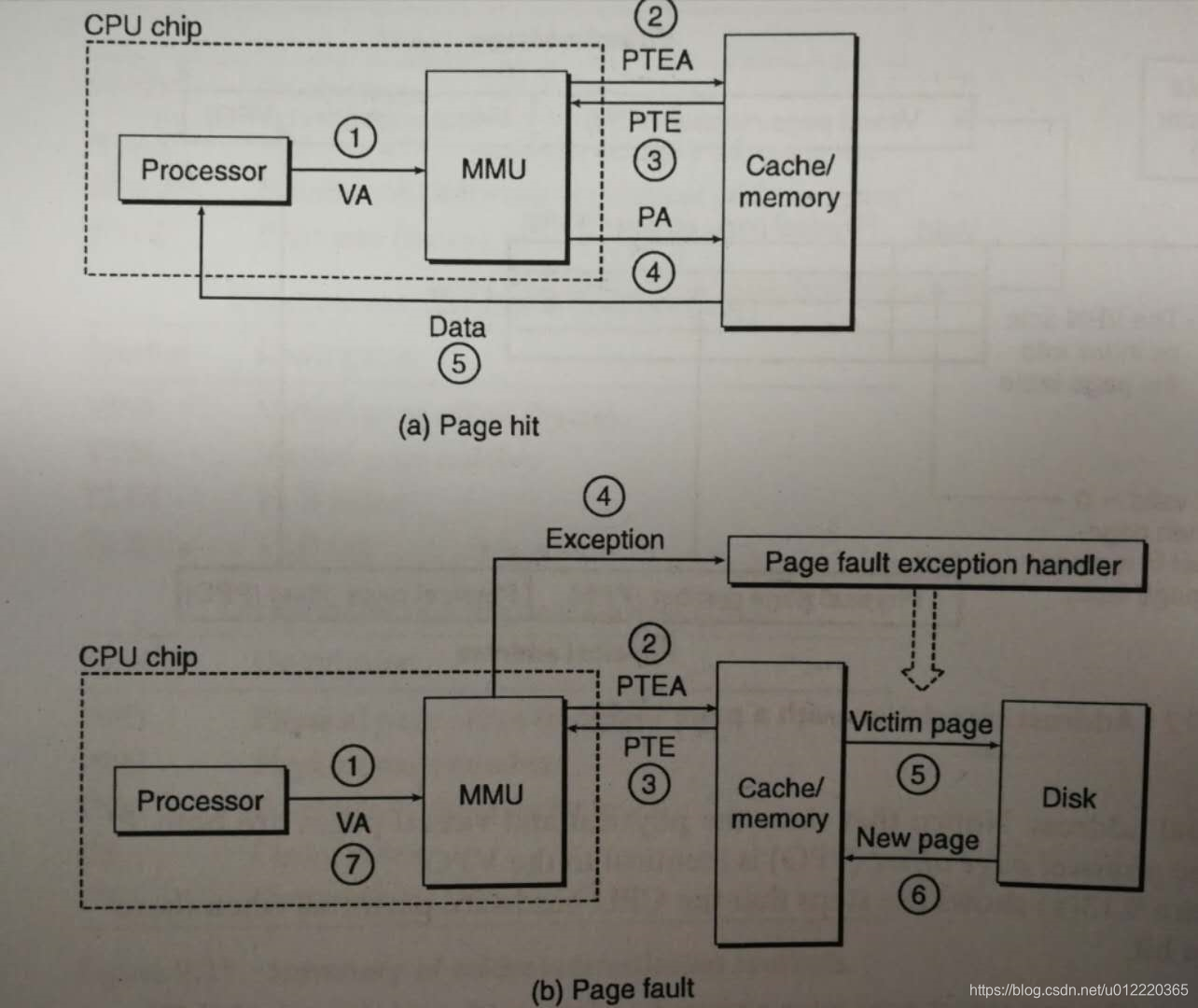
整个过程执行如下:
- processor 向 MMU 发送 VA
- MMU通过VA得到PTE address,访问Cache/memory
- 返回PTE
- 这个地方会根据PTE里valid的状态有不同处理
4.1 有效时将PA发给cache/memeory
4.2 无效时会触发exception,从而把空置权交给page fault exception handler - 对于page fault而言,此时执行换页
translation lookaside buffer
为了加快查找,会在MMU中对PTEs进行缓存.注意TLB是比L1还要快的地方
Multi-Level Page Tables
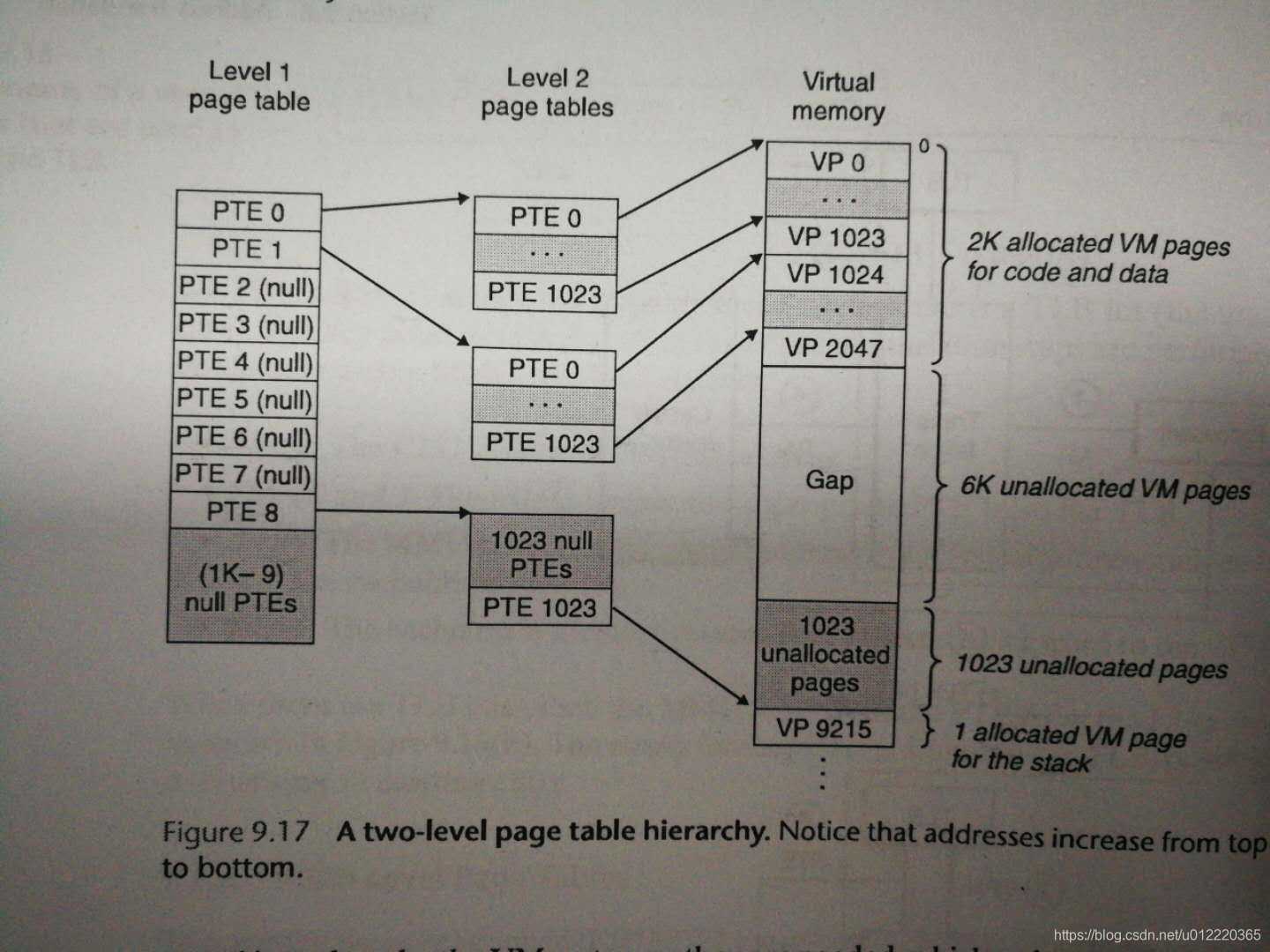
如下图所示,无论一个程序需要多少内存,而运行时声明的是整个VM空间,对于32位而言就是4G,如果Page大小是4K,而PTE大小是4byte,那么整个PT大小为4M,这样的话将会占用大量内存.其实里面大部分PTE是invalid的,于是可以进行压缩,就是采用多级方式(如下图),对于Level 1而言每个entry管理者4M的VM,那么只需要4K即可,Level1的每个entry又指向Level的PT.由于大多数VM其实未被使用,所以它们对应的Level1的entry是invalid的,那么也就不需要对应的Level2的PT了,这样就减少了空间占用.所以下图只需要4K(level1)+3*4K(level)就可以满足对整个VMS的查找.对于Level2的PT甚至可以放到Disk上(频繁使用的cache到主存)从而减少对主存的占用
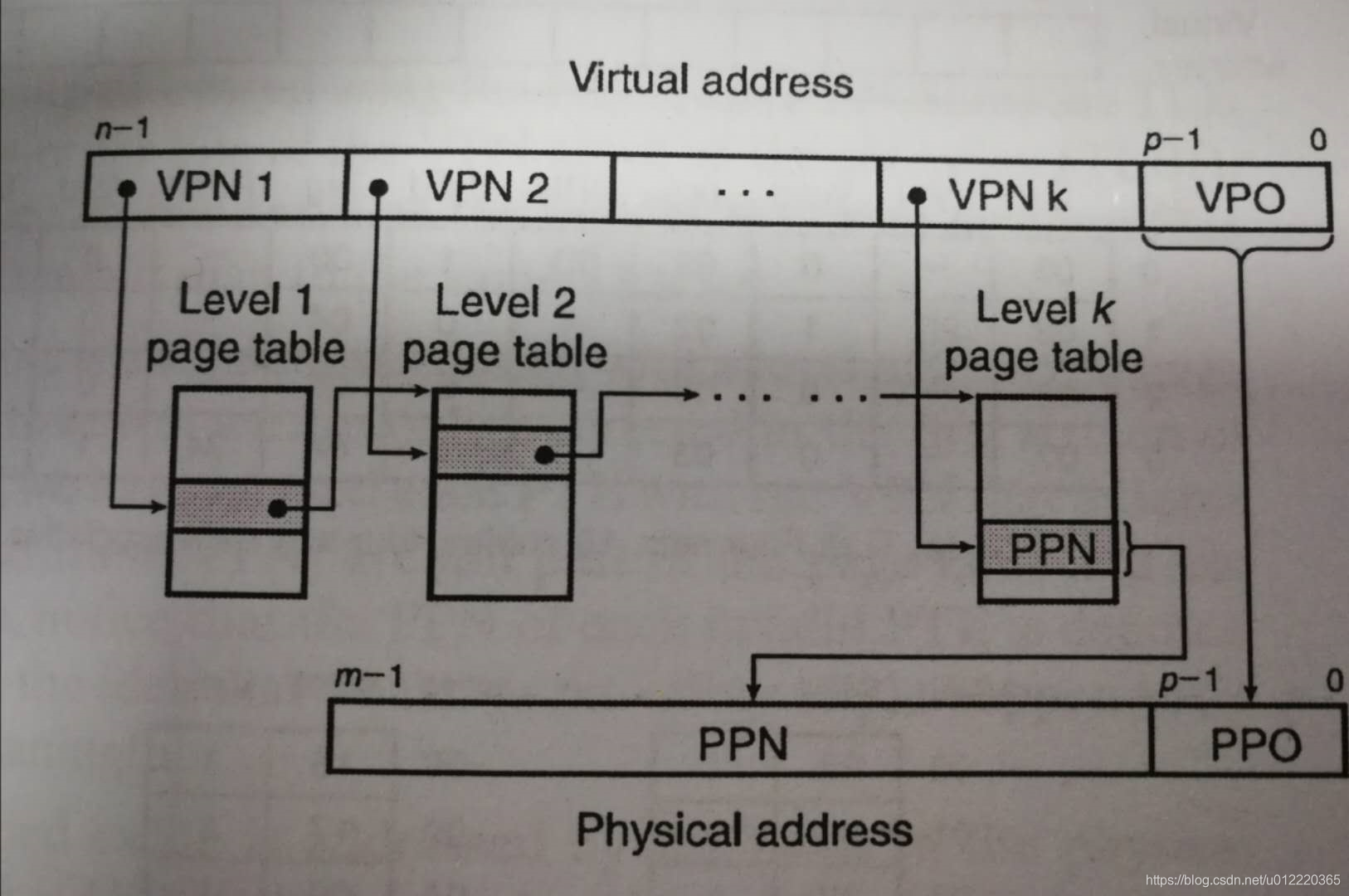
将上面的思想更推进一部采用
k
k
k级PT,那么整个Virtual address则是由其在k个Virtual Page Number和一个Virtual Page Offset组成.此时整个address resolving的过程如下
the intel/linux memory system
intel
因为兼容问题,intel采用了48位的VA,4级PT,当CPU需要获取一条数据时按照下图方式
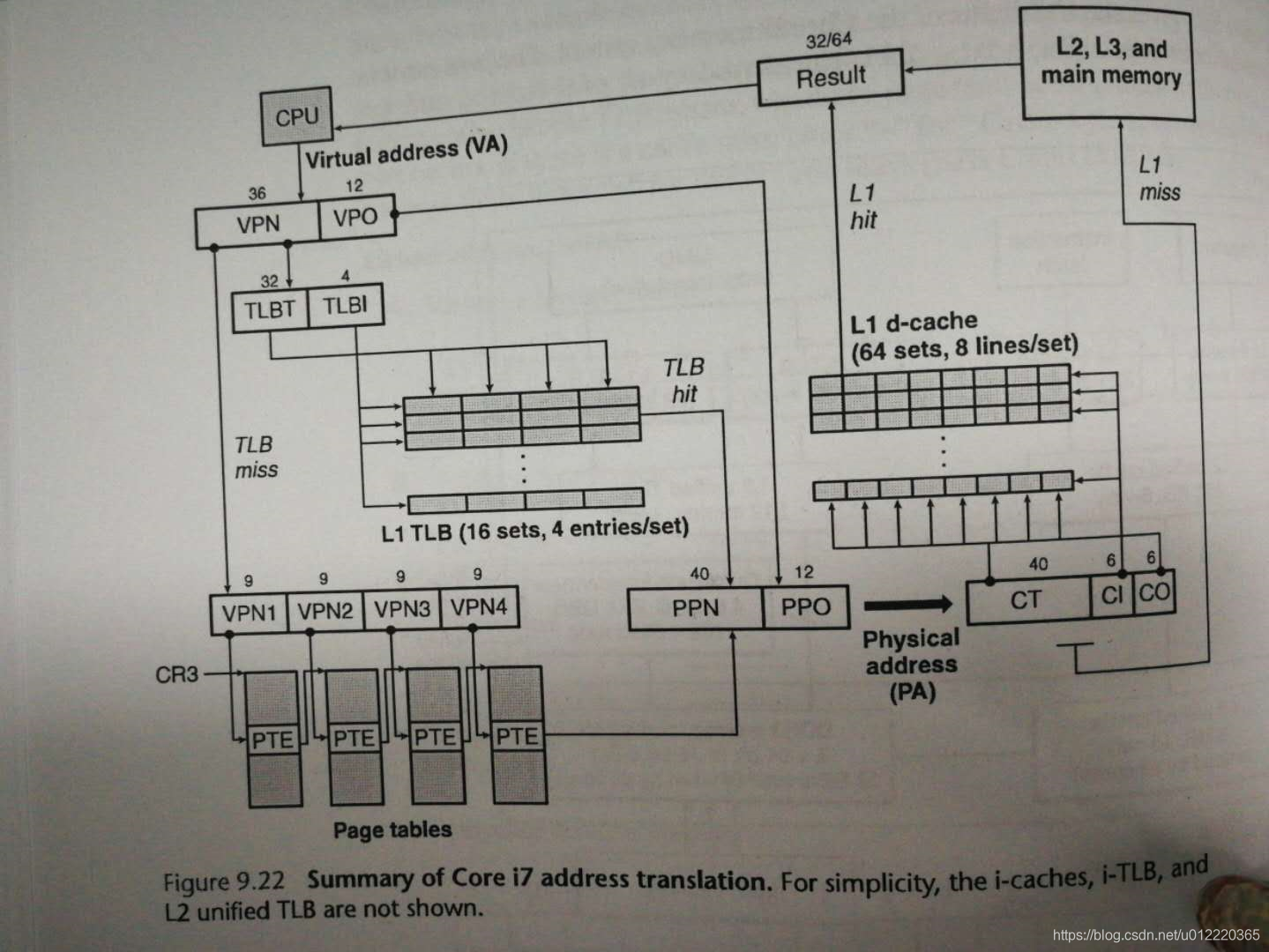
上面的CR3指向PT的地址,由每个process自带,在contrxt switch时设置.对于每个PTE格式如下
| XD | Unused | Page table physical base addr | Unused | G | PS | D | A | CD | WT | U/S | R/W | P |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 63 | 62…52 | 51…12 | 11…9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
各字段含义如下
P:下一级PT是否在主存
R/W:对于所有page是否只读
U/S:是否需要Supervisior mode
WT:对于子PT采用write-through还是write-back
CD:对于子PT是否允许cache
D:dirty,MMU设置,由software清除(只有末级有)
A:reference bit
PS:page size大小(4K/4M),只有Level1的PTE设置有效
XD:是否允许获取指令
为了加快指令处理,intel做了一个设定,把VPO设置为12位,而L1 cache由64个box和64byte的block,所以offset也是12,CPU会同时把VPO发给L1 cache和把VPN发给MMU,当MMU获取地址后就可以和L1 cache的比较,从而达到二者并行的地步
linux
area
linux使用area(也称为segment)来对VM进行分区,不同分区存放不同类型数据.对于每个process都有一个task_struct来帮助kernel来管理该process,这里有指向mm_struct的mm字段来管理vm,mm_struct中有pgd指向level 1 PT,也就是CPU的CR3,另外有个指向vm_area_struct的mmap字段来描述area信息.图中是以链表的形式画出,实际上linux采用了类似于树的结构来方便查找
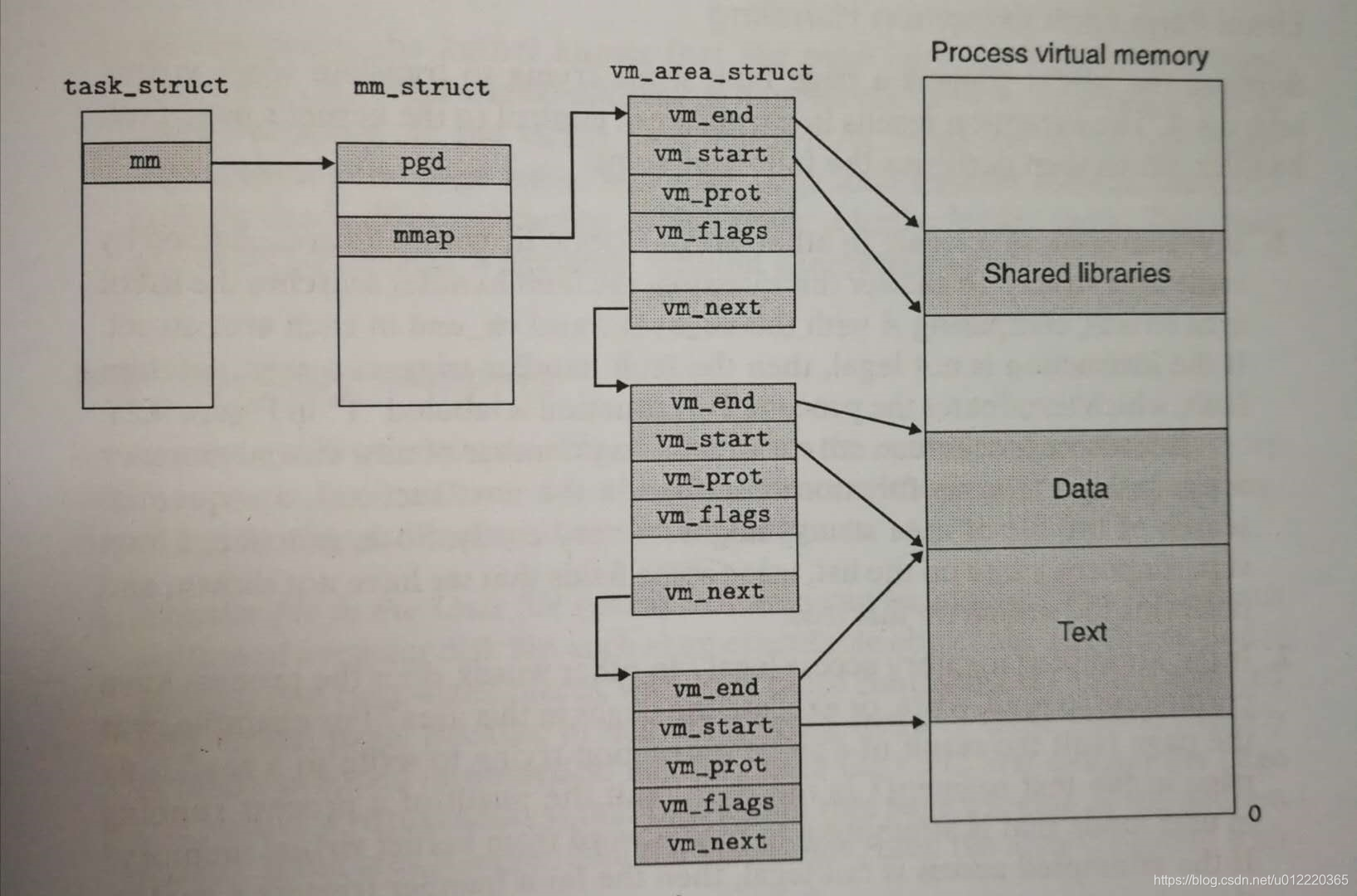
结合上图其中vm_area_struct中字段含义如下
- vm_start
area的开始 - vm_end
area结束 - vm_prot
决定读写权限 - vm_flags
是否多process共享 - vm_next
指向下一个vm_area_struct
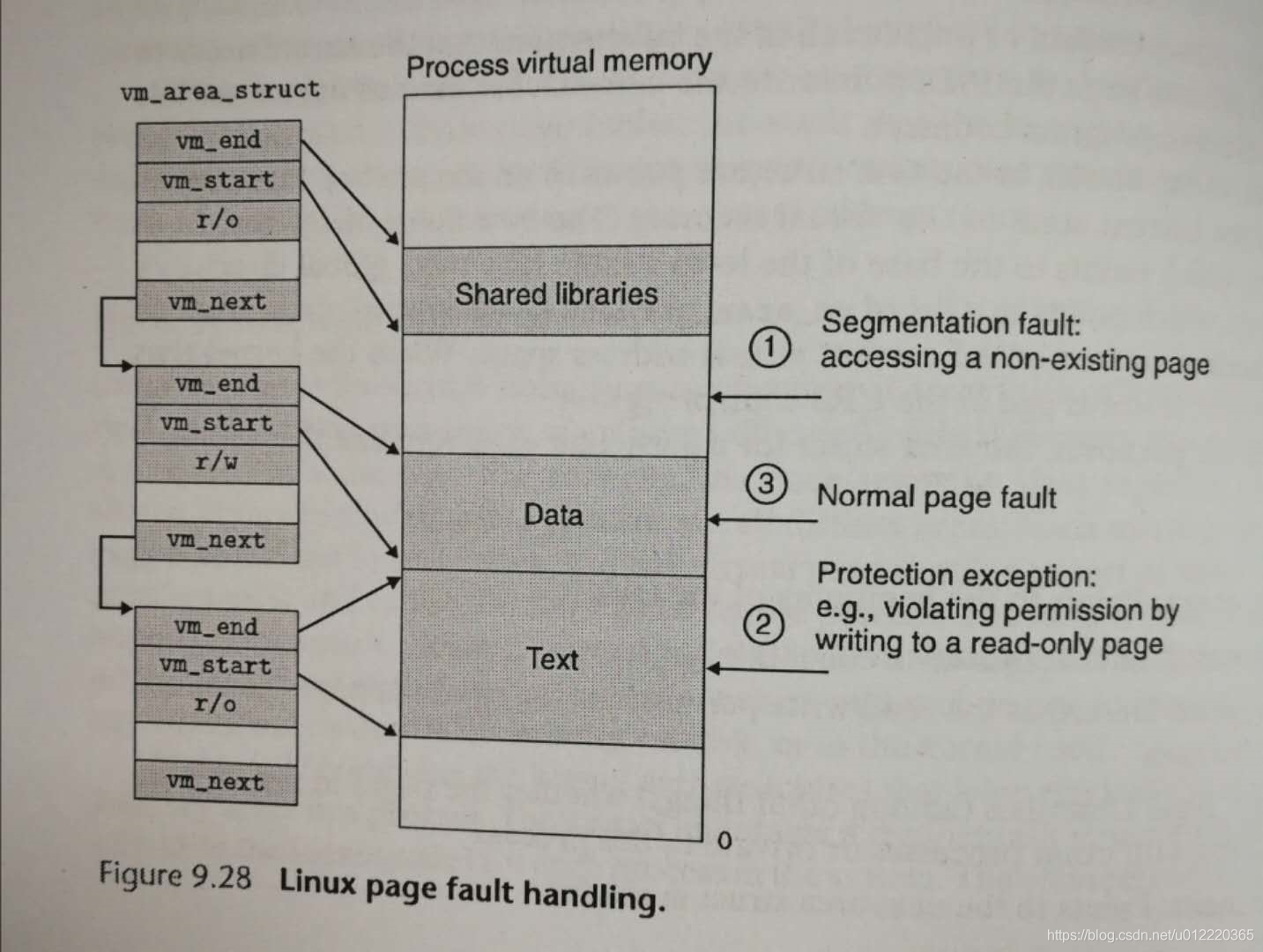
借助于此,当MMU触发page fault时候会做如下检查
- 是否超出范围
- 是否操作合法(user mode下操作kernel信息)
- 检查都通过了才做page swap
memory mapping
一般来说memory mapping是建立了disk和main memory之间的映射关系,但是根据disk是否有文件可以分为以下两种
- 有文件
当CPU需要读的时候从disk加载到main memory - 无文件
当由kernel创建,此时还未写入disk,所以disk无对应page,那么这个page也称为demand-zero page
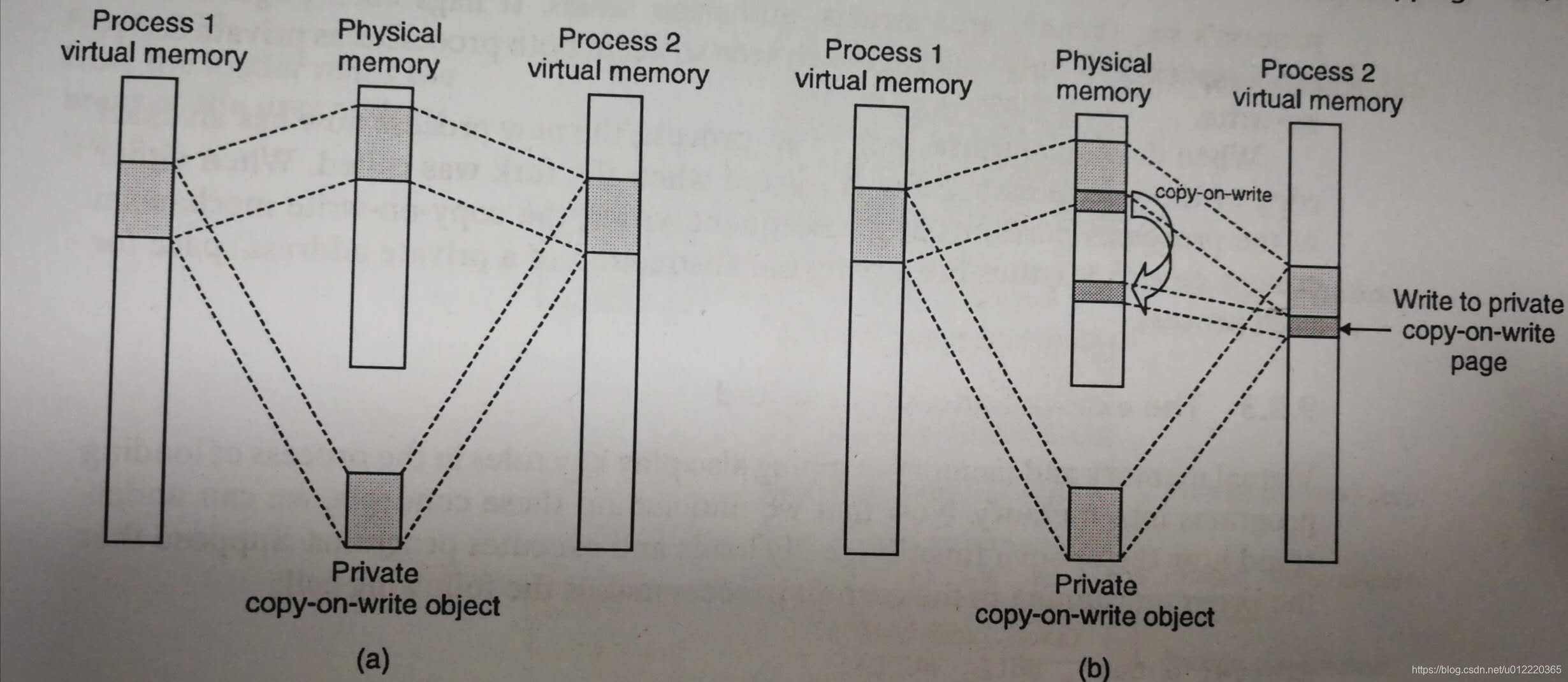
多个process如果需要读取disk上同一个object的时候,kernel只需要在内存中建立一个shared area给这两个process读取,并且该page是read only的,但是area struct是private copy-on-write的,当process写入时会触发protection fault,这个时候handler会拷贝并修改指向再重新执行写入指令
execve
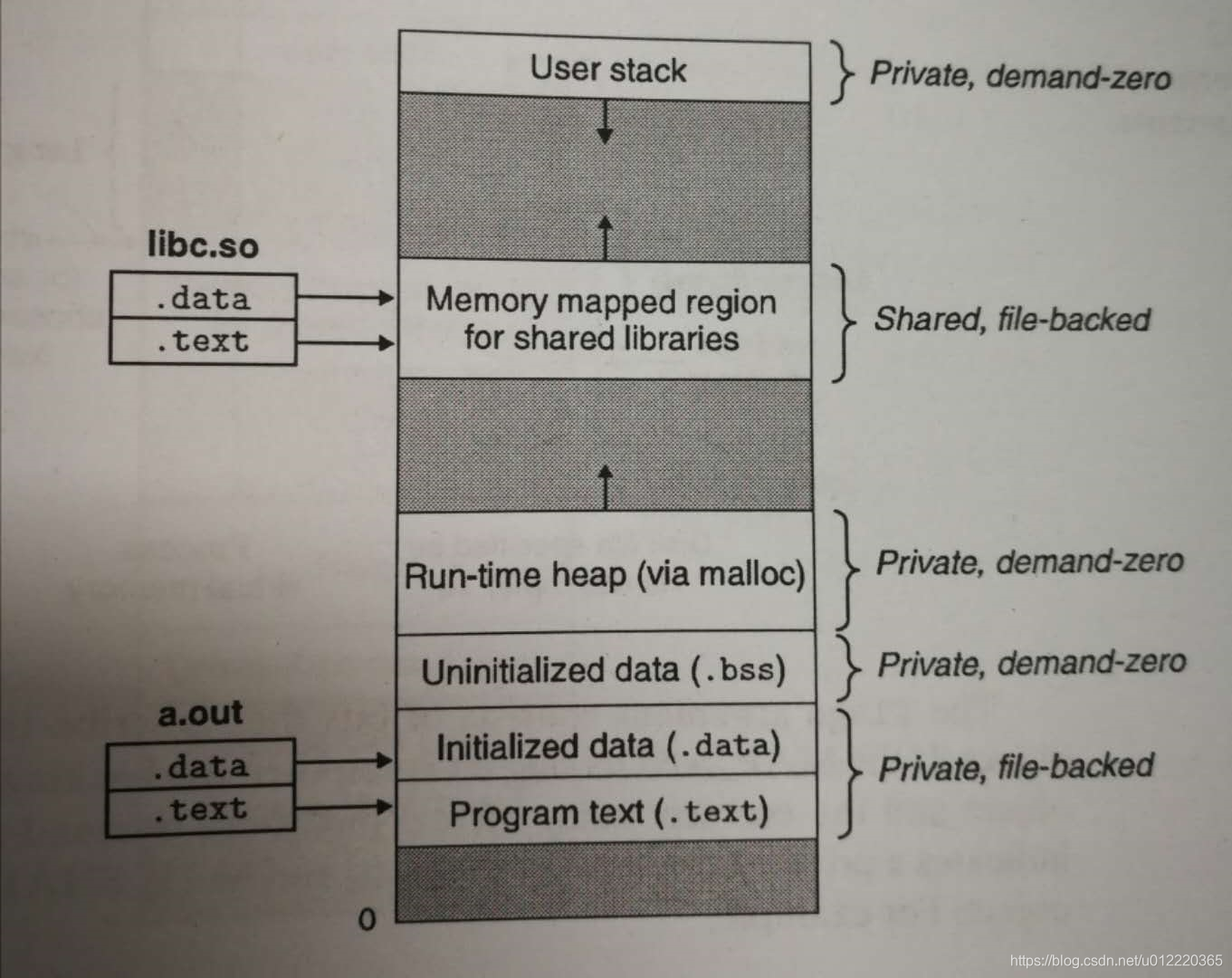
其中每个process有个brk指针指向堆顶
mmap
#include <unistd.h>
#include <sys/mman.h>
//return pointer to mapped area if ok,MAP_FAILED(-1)on error
void *mmap(void *start,size_t length,int prot,int flags,int fd,off_t offset);
//return o if ok,-1 on error
int munmap(void *start,size_t length);
上面的prot参数与vm_prot相对应,有以下几种选项
- PROT_EXEC
- PROT_READ
- PROT_WRITE
- PROT_NONE
当设置RPT_NONE时,page是不能被访问的
Explicit allocators
dynamic memory allocation有两种,一种是手动的,例如C中的malloc搭配free,C++中的new搭配delete
#include <stdlib.h>
//return ptr to allocated block if ok,NULL on error
void *malloc(size_t size);
void free(void *ptr);
通过malloc获得的内存没有初始化,可以调用calloc函数获取初始化了的内存.另外可以通过realloc来调整已经分配的block的大小
malloc可能嗲用mmap和munmap来分配内存,也可能直接通过sbrk函数来直接操作brk指针
#include <unistd.h>
//return old brk pointer on success,-1 on error
void *sbrk(intptr_t incr);
下面是一个具体例子,注意在b那张图内存分配时为了对齐,多分配了一小格

requirement
- handling arbitrary request sequence
- making immediate response to request
这一点要求allocator必须马上响应,不能重排序或使用缓存 - using only the heap
- aligning blocks
- not modifying allocated blocks
一旦分配后就不能移动,所以压缩也是不可能的.
goal
- maximizing throughput
- maximizing memory utilization
fragmentation
碎片可以分为两种
- internal fragmentation
这种碎片是由于align引起的,在申请的内存和实际分配的内存大小不一样,有些浪费 - externeal fragmentation
implicit free list
inplicit free list是一种自描述的数据结构(如下图),每个block有一个头部存放一些信息,并指向下一个free block(如下下图),在最后,通过一个0/1的block表示结束

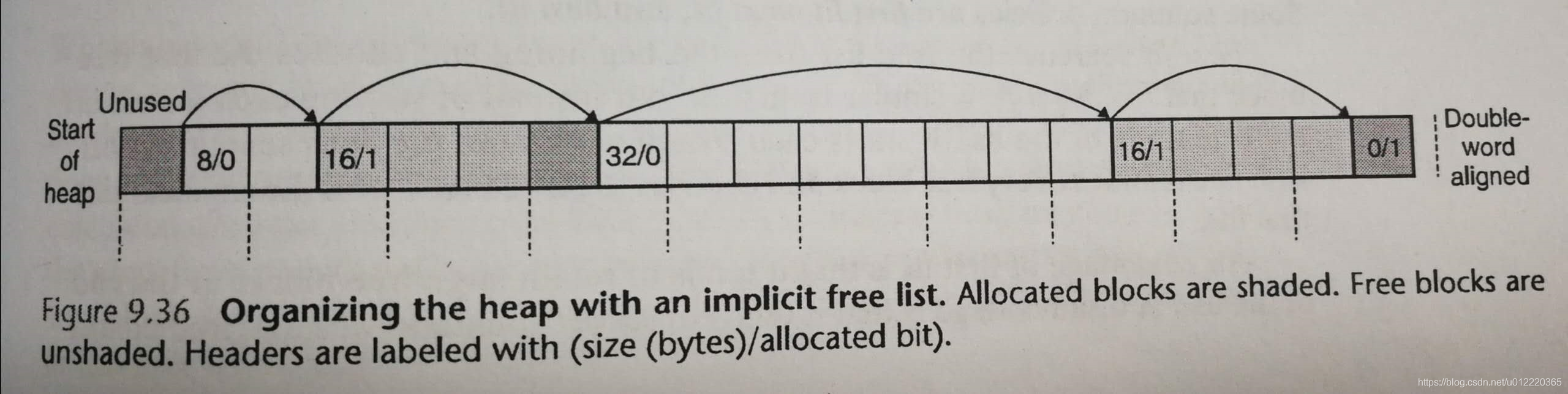
为了寻找合适的free block,有几种placement policy
- first fit
每次从头开始寻找,缺点是头部碎片,优点是尾部有大的free block - next fit
每次从上次找到的位置开始向后寻找,缺点是内存利用率不高,优点是减少了在头部碎片查询时间 - best fit
每次遍历找到最适合的block,缺点是耗时,优点是内存利用率高
当找到合适的free block,根据需要使用整个block或者将这个free block分为两部分而使用其中一部分.需要注意由于align的存在,一个block有最小大小(即对其的大小)
当找不到合适的free block的时候尝试合并,如果合并了仍然没有足够内存则向通过sbrk向kernel申请内存,则新的内存作为free block挂载上继续寻找.其中coalescing有两种方案:
- immediate coalescing
- deferred coalescing
综合应用
static char *mem_heap;/* point to first byte of head*/
static char *mem_brk;/* point to last byte of heap plus 1*/
static char *mem_max_addr;/* max legal heap addr plus 1*/
void mem_init(void){
mem_heap=(char *)Malloc(MAX_HEAP);
mem_brk=(char *)mem_heap;
mem_max_addr=(char *)(mem_heap+MAX_HEAP);
}
void *mem_sbrk(int incr){
char *old_brk=mem_brk;
if((incr<0)||((mem_brk+incr)>mem_max_addr)){
error-ENOMEM;
fprintf(stderr,"ERROR:mem_sbrk failed\n");
return (void *)-1;
}
mem_brk+=incr;
return (void *)old_brk;
}
#define WSIZE 4 /* Word and header/footer size(bytes)*/
#define DSIZE 8
#define CHUNKSIZE (1<<12) /*extend heap by this amount (bytes)*/
/*由于大多指针操作的语法不满足C里函数调用规范,改成宏的方式逃过检查*/
#define MAX(x,y) ((x)>(y)?(x):(y))
#define PACK(size,alloc) ((size)|(alloc)) //用于把alloc标志位放入
#define GET(p) (*(unsigned int *)(p))
#define PUT(p,val) (*(unsigned int *)(p)=(val))
#define GET_SIZE(p) (GET(p)& ~0x7)//与PACK相对
#define GET_ALLOC(p) (GET(p)&0x1)//与PACK相对
/*获取header和footer的地址,注意header和footer都存放有size*/
#define HDRP(bp) ((char *)(bp)-WSIZE)
#define FTRP(bp) ((char *)(bp)+GET_SIZE(HDRP(bp))-DSIZE)
#define NEXT_BLKP(bp) ((char *)(bp)+GET_SIZE(((char *)(bp)-WSIZE)))
#define PREV_BLKP(bp) ((char *)(bp)-GET_SIZE(((char *)(bp)-DSIZE)))
int mm_init(void){
if((heap_listp=mem_sbrk(4*WSIZE))==(void *)-1)
return -1;
PUT(heap_listp,0);
PUT(heap_listp+(1*WSIZE),PACK(DSIZE,1));//prologue header
PUT(heap_listp+(2*WSIZE),PACK(DSIZE,1));//prologue footer
PUT(heap_listp+(3*WSIZE),PACK(0,1));//epilogue header
heap_listp+=(2*WSIZE);
if(extend_heap(CHUNKSIZE/WSIZE)==NULL)
return -1;
return 0;
}
static void *extend_heap(size_t words){
char *bp;
size_t size;
size=(words%2)?(words+1)*WSIZE:words*WSIZE;//align
if((long)(bp=mem_sbrk(size)==-1)
return NULL;
PUT(HDRP(bp),PACK(size,0));//free block header
PUT(FTRP(bp),PACK(size,0));//free block footer
PUT(HDRP(NEXT_BLKP(bp)),PACK(0,1));//new epilogue header
return coalesce(bp);//也许需要合并block
}
void mm_free(void *bp){
size_t size=GET_SIZE(HDRP(bp));
PUT(HDRP(bp),PACK(size,0));
PUT(FTRP(bp),PACK(size,0));
coalesce(bp);
}
static void *coalesce(void *bp){
size_t prev_alloc=GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc=GET_ALLOC(HDRP(NEXT_BLKP(bp)));
size_t size=GET_SIZE(HDRP(bp));
if(prev_alloc && next_alloc){ //case 1
return bp;
}else if(prev_alloc && !next_alloc){ //case 2
size+=GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp),PACK(size,0));
PUT(FTRP(bp),PACK(size,0));
}else if(!prev_alloc && next_alloc){ //case 3
size+=GET_SIZE(HDRP(PREV_BLKP(bp)));
PUT(FTRP(bp),PACK(size,0));
PUT(HDRP(PREV_BLKP(bp)),PACK(size,0));
bp=PREV_BLKP(bp);
}else{
size+=GET_SIZE(HDRP(PREV_BLKP(bp)))+
GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)),PACK(size,0));
PUT(FTRP(NEXT_BLKP(bp)),PACK(size,0));
bp=PREV_BLKP(bp);
}
return bp;
}
void *mm_malloc(size_t size){
size_t asize;//经过对齐等调整后实际分配的大小
size_t extendsize;//如果空间不够则向Kernel请求分配的内存大小
if(size==0)
return NULL;
/*最小大小为2*DSIZE */
if(size<=DSIZE)
asize=2*DSIZE;
else
asize=DSIZE*((size+(DSIZE)+(DSIZE-1))/DSIZE);
if((bp=find_fit(asize))!=NULL){
place(bp,asize);
return bp;
}
extendsize=MAX(asize,CHUNKSIZE);
if((bp=extend_heap(extendsize/WSIZE))==NULL)
return NULL;
place(bp,asize);
return bp;
}
explicit free lists

相对于implicit free list而言explicit free list使用了一些额外的空间存放指针.至于block的顺序可以有以下几种
- LIFO
- address order
这样在和前面block合并的时候比较方便
segregated free lists
为了解决分配内存时需要遍历整个内存空间去寻找free block的问题,segregated storage的解决方案就是把free block进行分组(每组内的free block的大小大致一致).至于具体的分法又有很多种,书中举了以下两种
simple segregated storage
一般按照2的幂次方作为组内free block的大小,当需要内存时找到能满足要求的最小block大小的分组(例如需要内存为17时,找到block大小为32的分组),如果有则分配一整个block(不做切分),如果没有则向kernel请求一下内存,自己切割成多个free block放入分组.当收到free请求时把block放入对应分组即可
好处:不需要切分和合并,分配时间constant,由于地址很容易计算,所以少了一些指针,只需要succ即可
缺点:会造成大量内存碎片
segregated fits
把free block进行分组,组内block大小大致一样.当需要分配时去对应的分组中查找,如果找不到则去更高的分组里查找,找到后会做切分,把切分后得到的free block放入合适的分组.如果找不到则向kernel申请再拆分到合适分组.当收到free请求时会做合并操作,把合并得到的free block放入合适的分组.
buddy system
buddy system是segregated fit的一种,其特点是每个free block的大小均是 2 k 2^k 2k,当alloc时看下对应组里有没有,如果没有则去更高级的组里去寻找,其特点是在split的时候每次都是对半分,其中一个放入free list(buddy),另一个看是否需要继续split,当合并的时候都和自己的buddy合并,当合并后再看能否继续和buddy合并.所以两个buddy的内存地址刚好有一位的差别(例如一个是xxxx1000,另一个一定是xxxx0000).
归纳上面的几种方式,当block大小固定的时候拆分和合并会比较方便,缺点是碎片比较多
Implicit allocators
Implicit allocators需要allocator自动的探测需要回收的内存,也称为garbage collector,过程称为garbage collection

如图所示,dynamic storage allocator在收到分配内存的申请时,如果没有空闲内存则使用conservative garbage collector寻找垃圾,再调用free完成垃圾回收.如果还没有,则向kernel申请内存
mark & sweep
标记清除算法可以分为以下两个阶段
- mark
标记不需要被回收的block,注意这里是按照block而不是对象来标记
void mark(ptr p){
if((b=isPtr(p))==NULL)//isPtr获取p指向的block,
return;
if(blockMarked(b))//blockMarked获取b是否标记过
return;
markBlock(b);//标记b
len=length(b);
for(i=0;i<len;i++)
mark(b[i]);
return;
}
- sweep
void sweep(ptr b,ptr end){
while(b<end){
if(blockMarked(b))
unmarkBlock(b);
else if(blockAllocated(b)) //未标记,已分配则回收
free(b);
b=nextBlock(b);
}
return;
}
conservative
保守的回收算法不对指针进行专门标记,这样就不知道内存中的数字是int还是指针,只能全部当做指针(或者通过某种方式判断这个指针是否合法),这样就会有一些垃圾无法回收
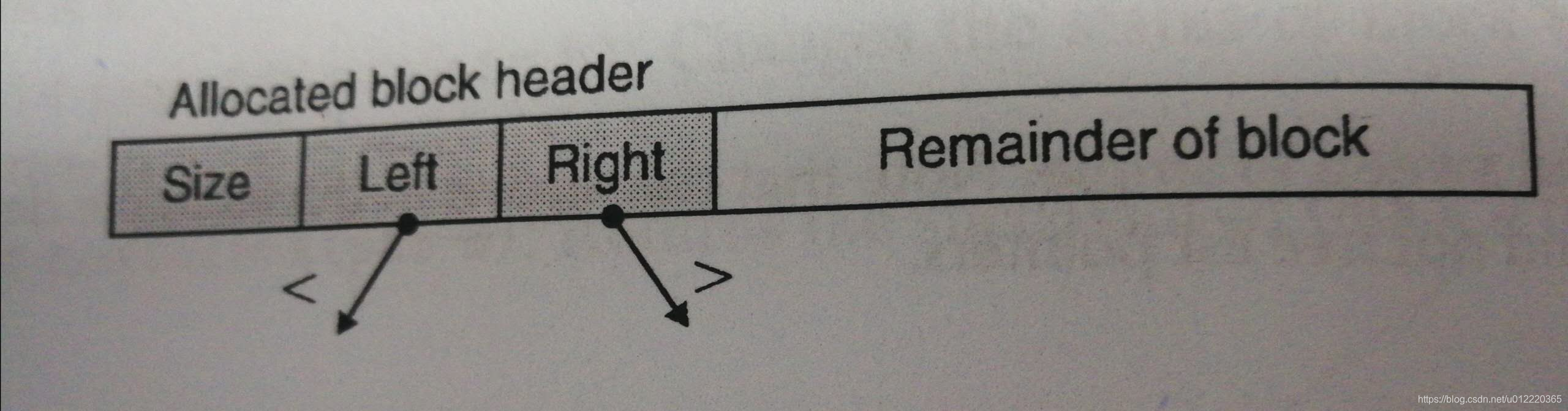
上面是一种对block进行改动从而判断内存中的一个值是否是指针,方法是增加left和right指针从而把所有allocated block连成一个二叉树,这样就可以遍历整个二叉树从而看当前内存中的值是否落在某个block中(通过block的地址和size就知道指针是否指向当前block内)
common memory-related bugs in C
- dereferencing bad pointers
将指针指向错误的地方
scanf("%d",&val) //正确写法
scanf("%d",val) //会被当前val的值作为指针而将数据写入到这个假指针指向的位置
- reading uninitialized memory
当内存被分配后并没有初始化为0,需要自己初始化,如果直接用… - allowing stack buffer overflows
void bufoverflow(){
char buf[64];
gets(buf);//此处可能产生bug
return;
}
- assuming the point and the object they point to are the same size
int makeArray(int n,int m){
int i;
int **A=(int **)Malloc(n*sizeof(int));//错误,应为sizeof(int *)
for(i=0;i<n;i++)
A[i]=(int *)Malloc(m*sizeof(int));
return A;
}
- making off-by-one errors
就是注意数组越界的问题
– referencing a point instead of the object it point to
注意操作的优先级,从而确定当前是在操作指针还是指针对应对象
int *binheapDelete(int **binheap,int *size){
int *packet=binhead[0];
binheap[0]=binheap[*size-1];
*size--;//此处应为(*size)--
heapify(binheap,*size,0);
return (packet);
}
- misunderstanding pointer arithmetic
指针的++运算和数字的++运算是不一样的,这个时候指针的++有点OO的感觉,会根据当前类型来smart的处理++
int *search(int *p,int val){
while(*p && *p!=val)
p+=sizeof(int);//此处应为p++
return p;
- referencing nonexistent variables
对于分配在栈上的一些变量,取他们地址return出去是有问题的,应为紧接着return这个frame会被时放点,而指针指向的内存地址会被后面的函数写入新的数据
int *stackref(){
int val;
return &val;
}
- referencing data in free heap blocks
先释放了一个指针指向的内存,然后又操作该指针 - introducing memory leaks
malloc后不free,造成内存泄漏














 2639
2639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









