






根据上一节的而配置,我们在sharding-proxy代理数据库中新建一张表
CREATE TABLE `t_order_0` (
`order_id` bigint(11) NOT NULL,
`user_id` int(11) DEFAULT NULL,
`status` varchar(255) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
新建好,我们可以发现在真实数据库中自动建立了2张表,t_order_0,t_order_1,是sharing-proxy自动帮我们建立的表
往代理数据库中添加数据: INSERT INTO `t_order` VALUES ('1', '1', '1');
根据配置:发现数据入库在物理数据库t_order_1中
在往代理数据库中插入数据: INSERT INTO `t_order` VALUES ('2', '2', '2'); 发现数据入库在物理数据库t_order_0中

可以发现物理数据库新增2条
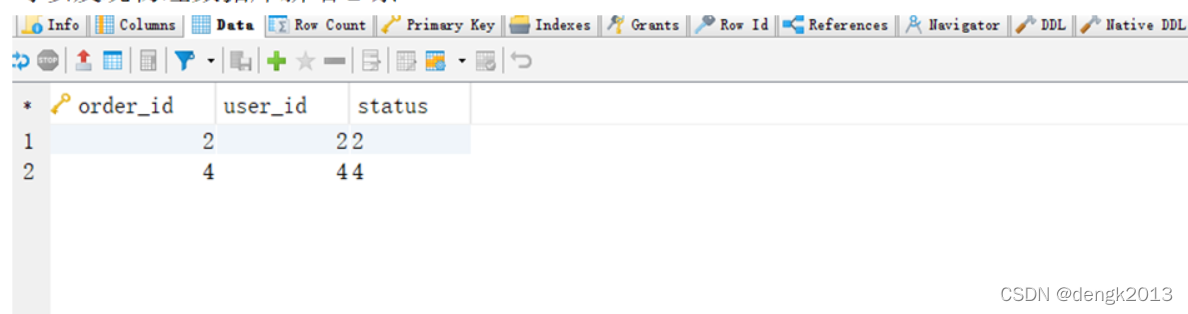
就这样分表结束了。通过代码编写只需要连接sharding-proxy
分表的配置如下:
schemaName: sharding_db
dataSources:
ds_0:
url: jdbc:mysql://129.2.176.195:3306/sharding_test?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true
username: root
password: root123
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
shardingRule:
tables:
t_order:
actualDataNodes: ds_${0}.t_order_${0..1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_${order_id % 2}
keyGenerator:
type: SNOWFLAKE
column: order_id
bindingTables:
- t_order
defaultDatabaseStrategy:
inline:
shardingColumn: user_id
algorithmExpression: ds_${0}
defaultTableStrategy:
none:
===============分库分表=====================
配置如下:
schemaName: sharding_db
dataSources:
ds_0:
url: jdbc:mysql://128.1.76.95:3306/sharding_test?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true
username: root
password: root123
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
ds_1:
url: jdbc:mysql://128.1.76.94:3306/sharding_test?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true
username: root
password: root123
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
shardingRule:
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_${order_id % 2}
keyGenerator:
type: SNOWFLAKE
column: order_id
bindingTables:
- t_order
defaultDatabaseStrategy:
inline:
shardingColumn: user_id
algorithmExpression: ds_${user_id % 2}
defaultTableStrategy:
none:
可以发现,操作sharding-proxy,数据分别入库在不同的数据库中和表中
===========读写分离========================
配置如下:
schemaName: master_slave_db
dataSources:
master_ds:
url: jdbc:mysql://192.3.76.194:3306/demo_ds_master?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true
username: root
password: root123
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
slave_ds_0:
url: jdbc:mysql://192.3.76.195:3306/demo_ds_slave_0?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true
username: root
password: root123
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
slave_ds_1:
url: jdbc:mysql://128.1.76.95:3306/demo_ds_slave_1?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true
username: root
password: root123
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
masterSlaveRule:
name: ms_ds
masterDataSourceName: master_ds
slaveDataSourceNames:
- slave_ds_0
- slave_ds_1
分别在主库创建数据库,在从库建立2个数据库,然后重启服务
重启服务我们会发现:在代理服务器自动创建了master_slave_db数据库
读写分离操作:往代理服务器新建一张表,发现主数据库也创建了表,而从服务器没有创建表,这时候我们在从服务器手动创建数据库;第二:往代理服务器新增一条数据,发现主服务器有数据,而从服务器没有数据,第三:往代理服务器读取数据发现没有数据这就证明了读写分离;
总结:在代理服务器向操作sql,写操作在主服务器上执行,读操作在从服务器操作,如果开启了bin-log,进行了主从复制的话,那么读写分离大大减轻了服务器的压力
总结+截图:
我们开启了主从复制:
1,首先在主服务器创建数据库demo_ds_master







================下面我们开启主从复制,也就是从服务的表结构在主服务器创建===========
1.清空表结构和数据
- 观察结果






















 2028
2028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









