






一、概述
1、无序,存储顺序和取出顺序不一致
2、不能重复,唯一
二、HashSet
(一)特点:
1、不保证 set 的迭代顺序,特别是它不保证该顺序恒久不变。
- 虽然Set集合的元素无序,但是,作为集合来说,它肯定有它自己的存储顺序, 而你的顺序恰好和它的存储顺序一致,这代表不了有序,你可以多存储一些数据,就能看到效果。
2、不能重复,唯一性。
3、HashSet底层是HashMap实现的,而数据结构为哈希表
(二)唯一性的分析:源码解析。
1)通过查看add()方法的源码,我们知道这个方法底层(其实是HashMap的put方法)依赖两个方法:hashCode()和equals()。
2)步骤:
- 先调用hashCode()方法,得出哈希值进行比较。
- 如果不同,就直接添加到集合中 。
- 如果相同,继续走,比较地址值(==)或者equals() 方法
- 返回true: 说明元素重复,就不添加
- 返回false:说明元素不重复,就添加到集合
3)如果类没有重写这两个方法,默认使用Object()的,一般来说不会相同。

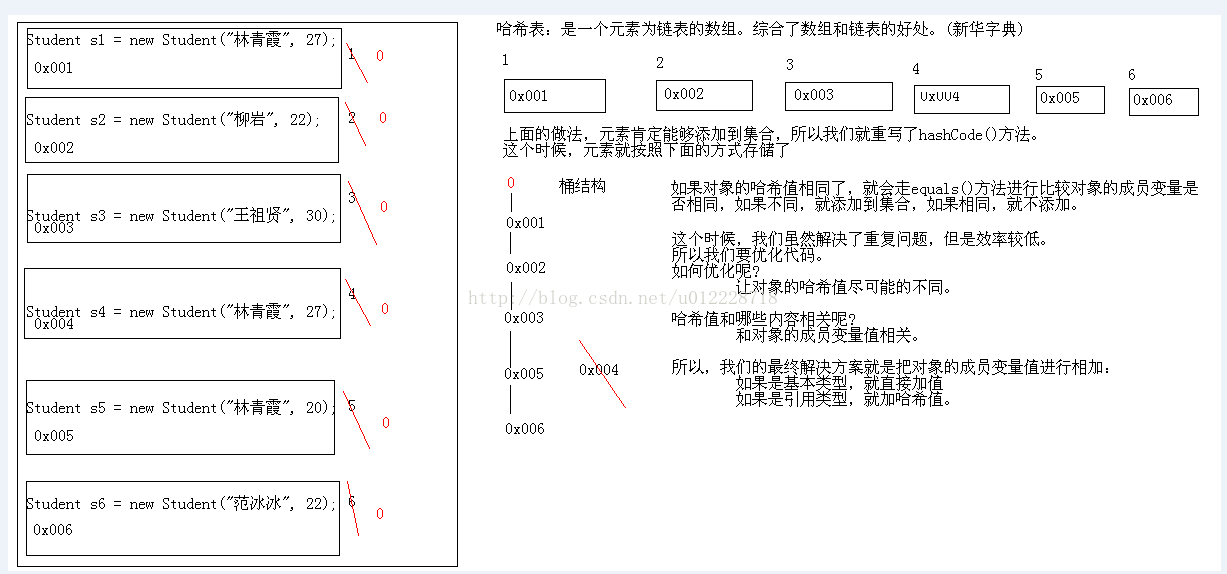
(三)唯一性内存图解
1、底层数据结构为哈希表
2、哈希表为一个元素为链表的数组,综合了数组与列表的好处。(新华字典)
<span style="font-size:18px;">package collection;
public class Student implements Comparable<Student>{
// 成员变量
private String name;
private int age;
// 构造方法
public Student() {
super();
}
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
// 成员方法
// getXxx()/setXxx()
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
@Override
public int compareTo(Student o) {
// 这里返回什么,其实应该根据我的排序规则来做
// 按照年龄排序,主要条件
int num = this.age - o.age;
// 次要条件
// 年龄相同的时候,还得去看姓名是否也相同
// 如果年龄和姓名都相同,才是同一个元素
int num2 = num == 0 ? this.name.compareTo(o.name) : num;//字符串重写了compareTo方法
return num2;
}
}
</span><span style="font-size:18px;"> /*
* 需求:存储自定义对象,并保证元素的唯一性
* 要求:如果两个对象的成员变量值都相同,则为同一个元素。
*
* 因为我们知道HashSet底层依赖的是hashCode()和equals()方法。
* 1、如果不重写两个方法我们没有重写的时候,会默认使用的是Object类。
* 这个时候,他们的哈希值是不会一样的,根本就不会继续判断,执行了添加操作。
*/
public void test2(){
// 创建集合对象
HashSet<Student> hs = new HashSet<Student>();
// 创建学生对象
Student s1 = new Student("林青霞", 27);
Student s2 = new Student("柳岩", 22);
Student s3 = new Student("王祖贤", 30);
Student s4 = new Student("林青霞", 27);
Student s5 = new Student("林青霞", 20);
Student s6 = new Student("范冰冰", 22);
// 添加元素
hs.add(s1);
hs.add(s2);
hs.add(s3);
hs.add(s4);
hs.add(s5);
hs.add(s6);
// 遍历集合
for (Student s : hs) {
System.out.println(s.getName() + "---" + s.getAge());
}
}</span>三、LinkedHashSet
(一)特点:
- 底层数据结构由哈希表和链表组成
- 链表保证元素有序,存储和取出是一致)。
- 无重复,哈希表保证元素的唯一性
四、TreeSet
(一)特点:
1、能够对元素按照某种规则进行排序。排序有两种方式(取决于构造函数):
- 自然排序:无参的构造方法。
- 在使用 TreeSet 作为集合存储对象(如Student类)的时候,Student 需要实现Comparable,重写compareTo()方法。
- 比较器排序:
- 需要一个实现 Comparator 接口的子类,实现compare()方法。
- 直接使用内部类即可,这样比较灵活。
2、TreeSet集合的特点:排序和唯一
(二)两种不同排序实例:
1、自然排序:需要实现Comparable,重写compareTo()方法。
<span style="font-size:18px;"> /*
* TreeSet存储自定义对象并保证排序和唯一。
*
* A:你没有告诉我们怎么排序
* 自然排序,按照年龄从小到大排序
* B:元素什么情况算唯一你也没告诉我
* 成员变量值都相同即为同一个元素
*/
public void test2(){
// 创建集合对象
TreeSet<Student> ts = new TreeSet<Student>();
// 创建元素
Student s1 = new Student("linqingxia", 27);
Student s2 = new Student("zhangguorong", 29);
Student s3 = new Student("wanglihong", 23);
Student s4 = new Student("linqingxia", 27);
Student s5 = new Student("liushishi", 22);
Student s6 = new Student("wuqilong", 40);
Student s7 = new Student("fengqingy", 22);
// 添加元素
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
ts.add(s5);
ts.add(s6);
ts.add(s7);
// 遍历
for (Student s : ts) {
System.out.println(s.getName() + "---" + s.getAge());
}
}</span>
2、比较器排序:需要一个实现 Comparator 接口的子类,实现compare()方法。
<span style="font-size:18px;"> /*
* 需求:请按照姓名的长度排序
*
* TreeSet集合保证元素排序和唯一性的原理
* 唯一性:是根据比较的返回是否是0来决定。
* 排序:
* A:自然排序(元素具备比较性)
* 让元素所属的类实现自然排序接口 Comparable
* B:比较器排序(集合具备比较性)
* 让集合的构造方法接收一个比较器接口的子类对象 Comparator
*/
public void test3(){
// 创建集合对象
// TreeSet<Student> ts = new TreeSet<Student>(); //自然排序
// public TreeSet(Comparator comparator) //比较器排序
// TreeSet<Student> ts = new TreeSet<Student>(new MyComparator());
// 如果一个方法的参数是接口,那么真正要的是接口的实现类的对象
// 而匿名内部类就可以实现这个东西
TreeSet<Student> ts = new TreeSet<Student>(new Comparator<Student>() {
@Override
public int compare(Student s1, Student s2) {
// 姓名长度
int num = s1.getName().length() - s2.getName().length();
// 姓名内容
int num2 = num == 0 ? s1.getName().compareTo(s2.getName())
: num;
// 年龄
int num3 = num2 == 0 ? s1.getAge() - s2.getAge() : num2;
return num3;
}
});
// 创建元素
Student s1 = new Student("linqingxia", 27);
Student s2 = new Student("zhangguorong", 29);
Student s3 = new Student("wanglihong", 23);
Student s4 = new Student("linqingxia", 27);
Student s5 = new Student("liushishi", 22);
Student s6 = new Student("wuqilong", 40);
Student s7 = new Student("fengqingy", 22);
Student s8 = new Student("linqingxia", 29);
// 添加元素
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
ts.add(s5);
ts.add(s6);
ts.add(s7);
ts.add(s8);
// 遍历
for (Student s : ts) {
System.out.println(s.getName() + "---" + s.getAge());
}
}</span>
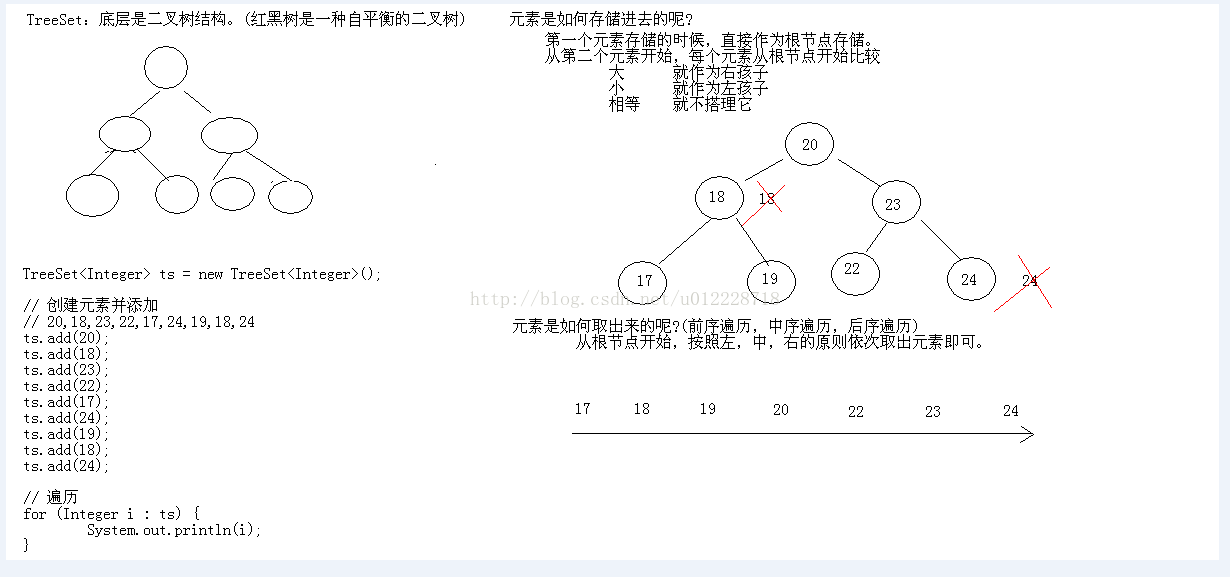
(三)TreeSet 的数据结构
1、通过观察TreeSet的add()方法,我们知道最终要看TreeMap的put()方法。
- 基于红黑树。
2、图解














 312
312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









